PHYRE
It provides a set of physics puzzles in a simulated 2D world. Each puzzle has a goal state (e.g., make the green ball touch the blue wall) and an initial state in which the goal is not satisfied (see the figure below). A puzzle can be solved by placing one or more new bodies in the environment such that when the physical simulation is run the goal is satisfied. An agent playing this game must solve previously unseen puzzles in as few attempts as possible.
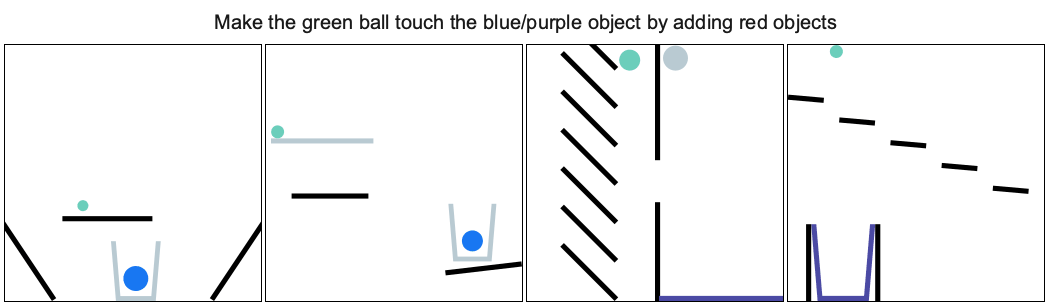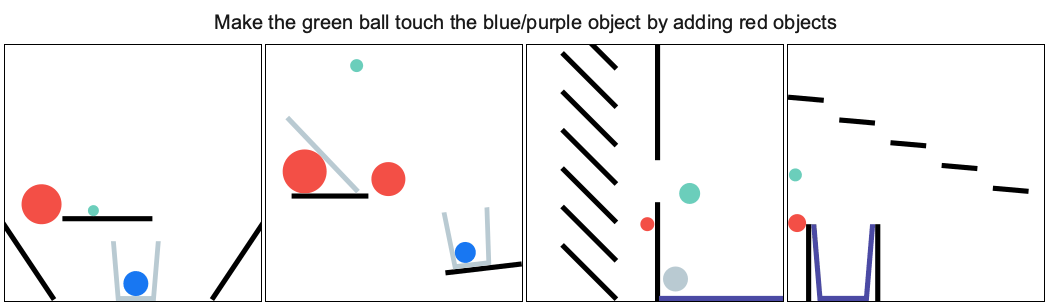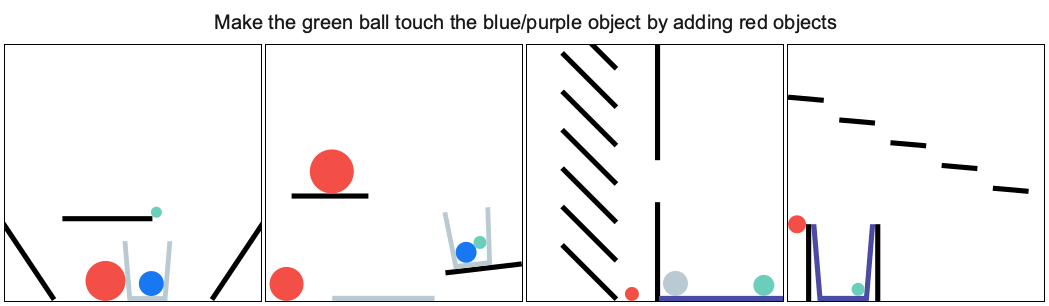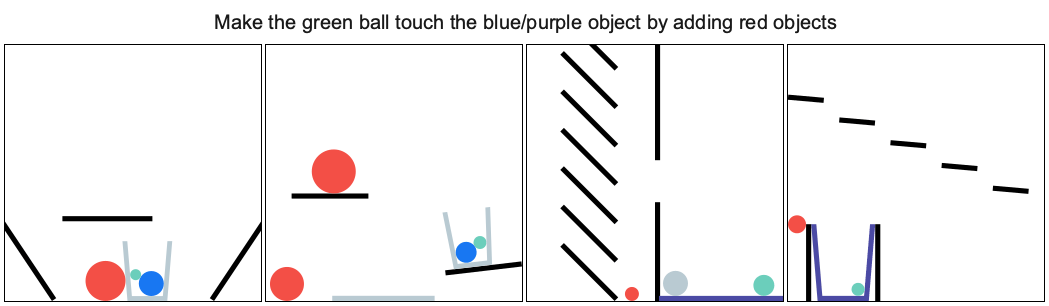
You can explore the tasks and try to solve them using the demo and jump straight into jupyter notebook.
Getting started
Installation
The simplest way to install PHYRE is via pip. As PHYRE requires Python version 3.6, we recommend installing PHYRE inside a virtual environment, e.g. using Conda.
We provide PHYRE as a pip package for both Linux and Mac OS.
conda create -n phyre python=3.6 && conda activate phyre
pip install phyre
To check that the installation was successful, run python -m phyre.server and open http://localhost:30303. That should start a local demo server.
Notebooks
We provide jupyter notebooks that show how to use PHYRE API to run simulations and evaluate a random agent and how to use simulation cache to train agents faster.
In order to run the notebooks, you may need to install additional python dependencies with pip install -r requirements.examples.txt.
Training an agent
We provide a set of baseline agents that are described in the paper.
In order to run them, you need to install additional python dependencies with pip install -r requirements.agents.txt.
All the agents are located in agents/ folder. The entry point is train.py
that will train an agent on specified eval setup with a specified fold.
E.g., the following command will train a memoization agent:
python agents/train.py \
--output-dir=results/ball_cross_template/0 \
--eval-setup-name=ball_cross_template \
--fold-id=0 \
--mem-rerank-size 100 \
--agent-type=memoize
File run_experiment.py contains groups of experiments, e.g, sweeping over number of update for DQN-O or training agents on all seeds and eval setups. And train_all_baseline.sh starts experiments to train all baseline algorithms in the paper.



