Horovod
Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed Deep Learning fast and easy to use.
Horovod is hosted by the LF AI Foundation (LF AI). If you are a company that is deeply committed to using open source technologies in artificial intelligence, machine and deep learning, and wanting to support the communities of open source projects in these domains, consider joining the LF AI Foundation. For details about who's involved and how Horovod plays a role, read the LF AI announcement.
Why not traditional Distributed TensorFlow?
The primary motivation for this project is to make it easy to take a single-GPU TensorFlow program and successfully train it on many GPUs faster. This has two aspects:
- How much modification does one have to make to a program to make it distributed, and how easy is it to run it?
- How much faster would it run in distributed mode?
Internally at Uber we found the MPI model to be much more straightforward and require far less code changes than the Distributed TensorFlow with parameter servers. See the Usage section for more details.
In addition to being easy to use, Horovod is fast. Below is a chart representing the benchmark that was done on 128 servers with 4 Pascal GPUs each connected by RoCE-capable 25 Gbit/s network:
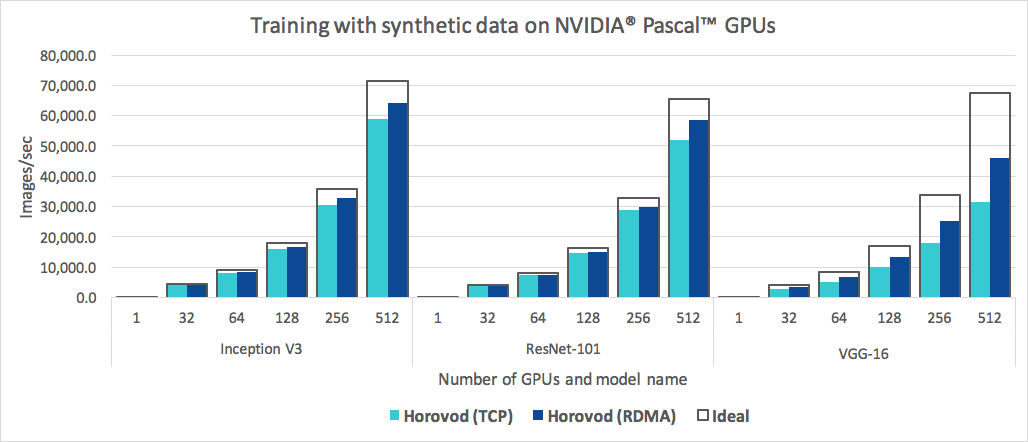
Horovod achieves 90% scaling efficiency for both Inception V3 and ResNet-101, and 68% scaling efficiency for VGG-16. See the Benchmarks page to find out how to reproduce these numbers.
While installing MPI and NCCL itself may seem like an extra hassle, it only needs to be done once by the team dealing with infrastructure, while everyone else in the company who builds the models can enjoy the simplicity of training them at scale.



