Mish
Mish: Self Regularized Non-Monotonic Activation Function.
Inspired by Swish Activation Function (Paper), Mish is a Self Regularized Non-Monotonic Neural Activation Function. Activation Function serves a core functionality in the training process of a Neural Network Architecture and is represented by the basic mathematical representation:
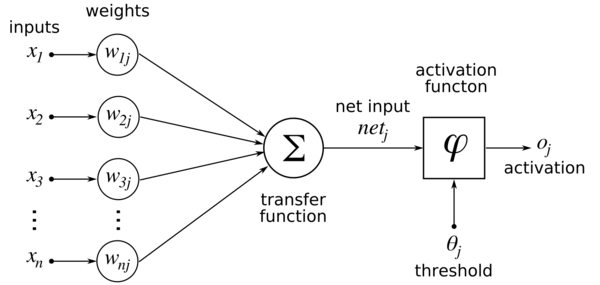
An Activation Function is generally used to introduce non-linearity and over the years of theoretical machine learning research, many activation functions have been constructed with the 2 most popular amongst them being:
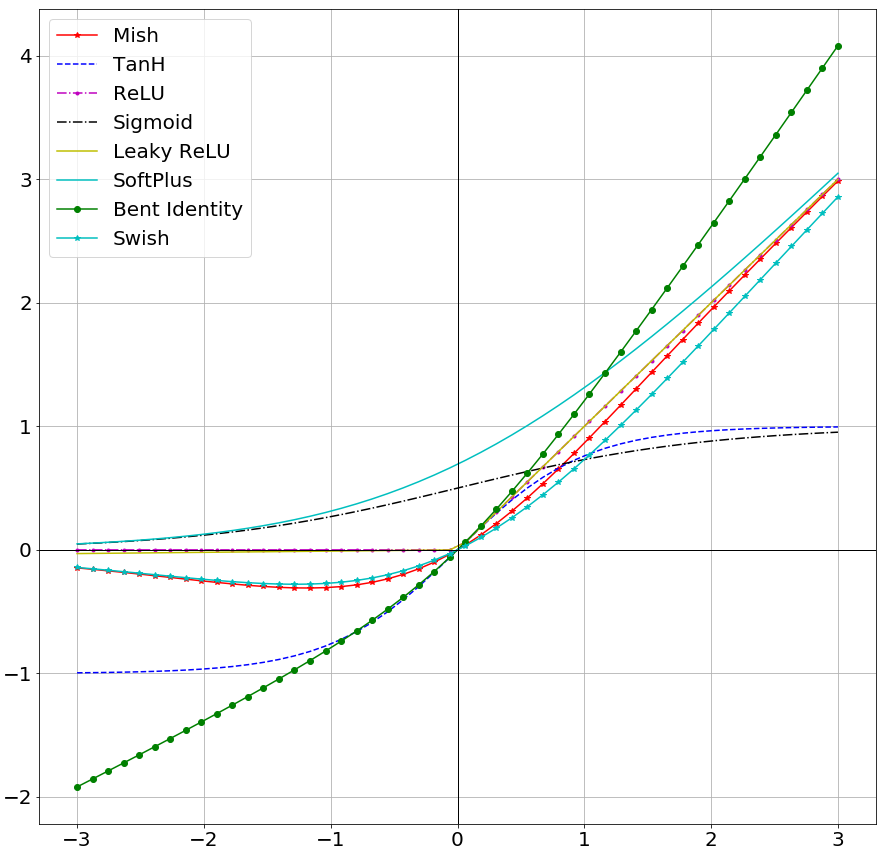
- ReLU (Rectified Linear Unit; f(x)=max(0,x))
- TanH
Other notable ones being:
- Softmax (Used for Multi-class Classification in the output layer)
- Sigmoid (f(x)=(1+e-x)-1;Used for Binary Classification and Logistic Regression)
- Leaky ReLU (f(x)=0.001x (x<0) or x (x>0))
Mathematics under the hood:
Mish Activation Function can be mathematically represented by the following formula:



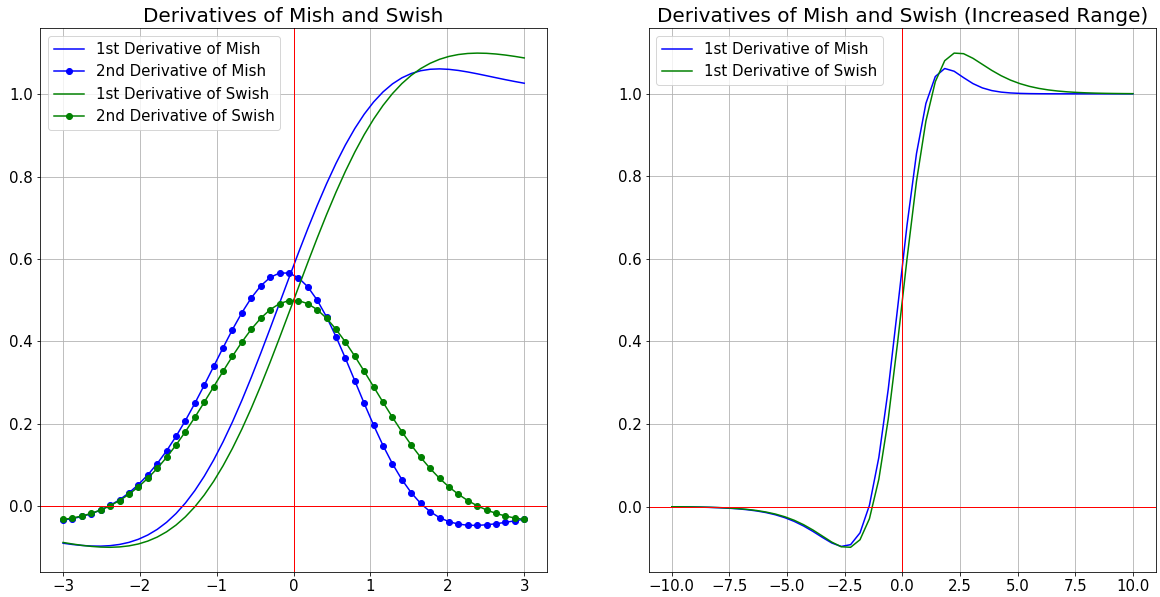
And it's 1st and 2nd derivatives are given below:


Where:


The Taylor Series Expansion of f(x) at x=0 is given by:

The Taylor Series Expansion of f(x) at x=∞ is given by:

Minimum of f(x) is observed to be ≈-0.30884 at x≈-1.1924
When visualized, Mish Activation Function closely resembles the function path of Swish having a small decay (preserve) in the negative side while being near linear on the positive side. It is a Non-Monotonic Function and as observed from it's derivatives functions shown above and graph shown below, it can be noted that it has a Non-Monotonic 1st derivative and 2nd derivative.
Mish ranges between ≈-0.31 to ∞.
Following image shows the effect of Mish being applied on random noise. This is a replication of the effect of the activation function on the image tensor inputs in CNN models.

Based on mathematical analysis, it is also confirmed that the function has a parametric order of continuity of: C∞
Mish has a very sharp global minima similar to Swish, which might account to gradients updates of the model being stuck in the region of sharp decay thus may lead to bad performance levels as compared to ReLU. Mish, also being mathematically heavy, is more computationally expensive as compared to the time complexity of Swish Activation Function.
The output landscape of 5 layer randomly initialized neural network was compared for ReLU, Swish, and Mish. The observation clearly shows the sharp transition between the scalar magnitudes for the co-ordinates of ReLU as compared to Swish and Mish. Smoother transition results in smoother loss functions which are easier to optimize and hence the network generalizes better. Additional comparison of output landscapes is done for GELU, SELU, ELU, Leaky ReLU, PReLU and RReLU. Most of them similar to ReLU have sharp transitions in the output landscape and thus prove to be a roadblock to effective optimization of gradients.



The Pre-Activations (ωx + b) distribution was observed for the final convolution layer in a ResNet v1-20 with Mish activation function before and after training for 20 epochs on CIFAR-10. As shown below, units are being preserved in the negative side which improves the network capacity to generalize well due to less loss of information.

Complex Analysis of Mish Activation Function:

Variation of Parameter Comparison:
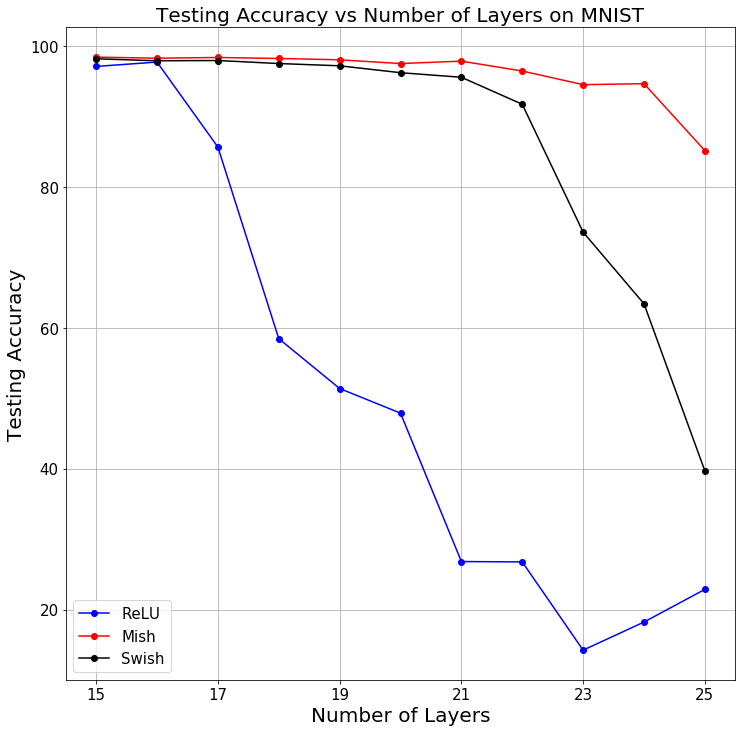
To observe how increasing the number of layers in a network while maintaining other parameters constant affect the test accuracy, fully connected networks of varying depths on MNIST, with each layer having 500 neurons were trained. Residual Connections were not used because they enable the training of arbitrarily deep networks. BatchNorm was used to lessen the dependence on initialization along with a dropout of 25%. The network is optimized using SGD on a batch size of 128, and for fair comparison, the same learning rates for each activation function was maintained. In the experiments, all 3 activations maintained nearly the same test accuracy for 15 layered Network. Increasing number of layers from 15 gradually resulted in a sharp decrease in test accuracy for Swish and ReLU, however, Mish outperformed them both in large networks where optimization becomes difficult.
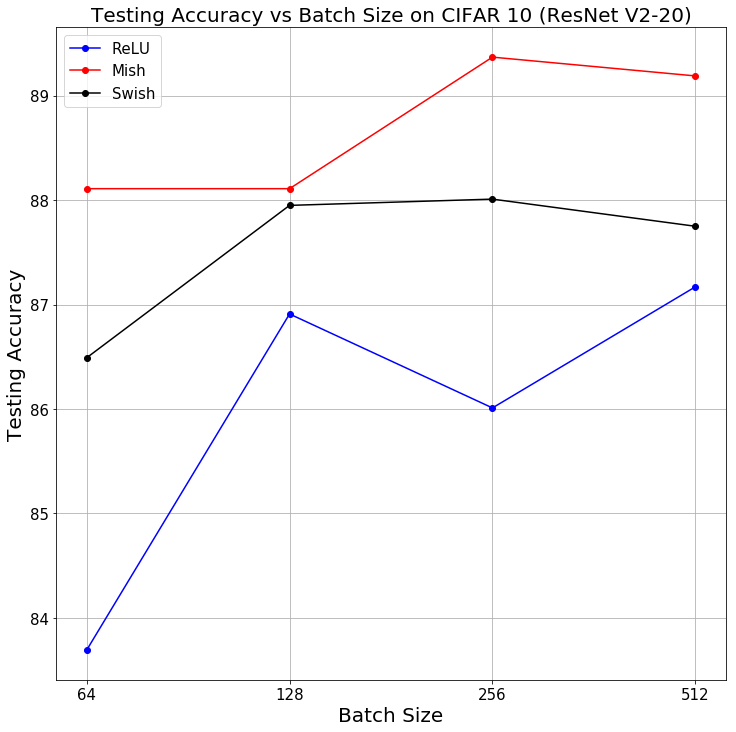
The consistency of Mish providing better test top-1 accuracy as compared to Swish and ReLU was also observed by increasing Batch Size for a ResNet v2-20 on CIFAR-10 for 50 epochs while keeping all other network parameters to be constant for fair comparison.
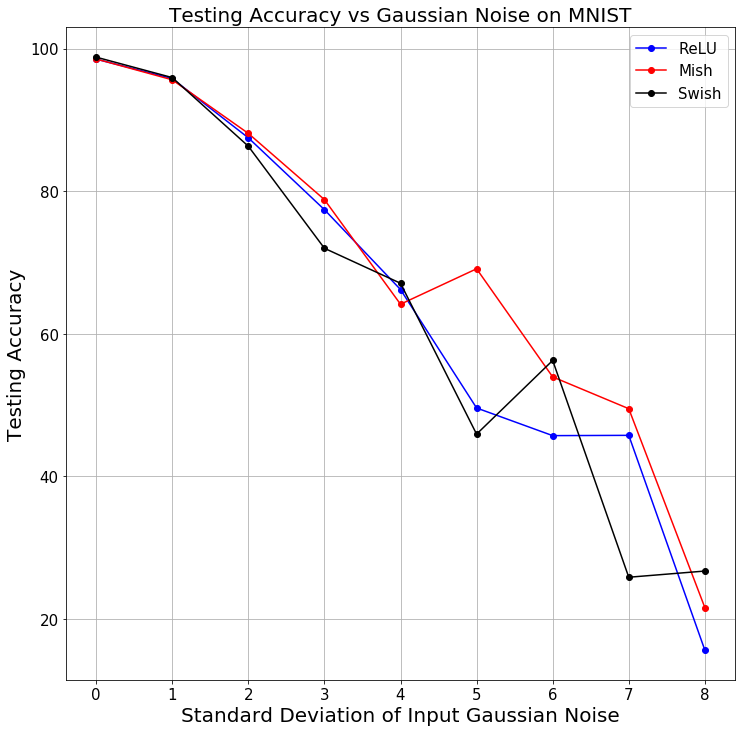
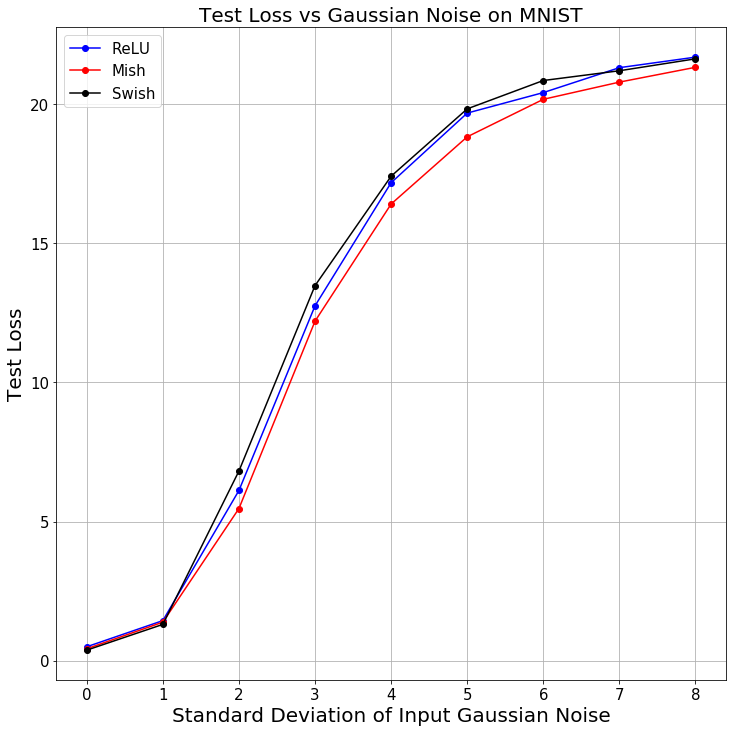
Gaussian Noise with varying standard deviation was added to the input in case of MNIST classification using a simple conv net to observe the trend in decreasing test top-1 accuracy for Mish and compare it to that of ReLU and Swish. Mish mostly maintained a consistent lead over that of Swish and ReLU (Less than ReLU in just 1 instance and less than Swish in 3 instance) as shown below. The trend for test loss was also observed following the same procedure. (Mish has better loss than both Swish and ReLU except in 1 instance)
Edge of Chaos and Rate of Convergence (EOC & ROC):
Coming Soon
Properties Summary:
| Activation Function Name | Function Graph | Equation | Range | Order of Continuity | Monotonic | Monotonic Derivative | Approximates Identity Near Origin | Dead Neurons | Saturated |
|---|---|---|---|---|---|---|---|---|---|
| Mish |  |
 |
≈-0.31 to ∞ | C∞ | No :negative_squared_cross_mark: | No :negative_squared_cross_mark: | Yes :heavy_check_mark: (Approximates half of identity at origin) | No :negative_squared_cross_mark: | No :negative_squared_cross_mark: |
Results:
All results and comparative analysis are present in the Readme file present in the Notebooks Folder.
Summary of Results:
Comparison is done based on the high priority metric, for image classification the Top-1 Accuracy while for Generative Networks and Image Segmentation the Loss Metric. Therefore, for the latter, Mish > Baseline is indicative of better loss and vice versa. For Embeddings, the AUC metric is considered.
| Activation Function | Mish > Baseline Model | Mish < Baseline Model |
|---|---|---|
| ReLU | 54 | 20 |
| Swish-1 | 52 | 22 |
| ELU(α=1.0) | 13 | 1 |
| Aria-2(β = 1, α=1.5) | 2 | 0 |
| Bent's Identity | 1 | 0 |
| Hard Sigmoid | 1 | 0 |
| RReLU | 7 | 3 |
| Leaky ReLU(α=0.3) | 8 | 4 |
| PReLU(Default Parameters) | 9 | 2 |
| SELU | 13 | 0 |
| Sigmoid | 11 | 0 |
| SoftPlus(β = 1) | 9 | 1 |
| Softsign | 8 | 1 |
| TanH | 13 | 0 |
| SQNL | 1 | 0 |
| Thresholded ReLU(θ=1.0) | 1 | 0 |
| E-Swish (β=1.75) | 9 | 6 |
| GELU | 8 | 2 |
| CELU(α=1.0) | 9 | 0 |
| HardShrink(λ = 0.5) | 9 | 0 |
| Hardtanh | 9 | 1 |
| ReLU6 | 8 | 1 |
| LogSigmoid | 9 | 1 |
| Softshrink (λ = 0.5) | 7 | 0 |
| Tanhshrink | 10 | 0 |
CIFAR Results (Top-1 Testing Accuracy):
| Models | Mish | Swish | ReLU |
|---|---|---|---|
| ResNet v1-20 | CIFAR 10: 91.81% |
CIFAR 10: 91.95% |
CIFAR 10: 91.5% |
| ResNet v1-32 | CIFAR 10: 92.29% |
CIFAR 10: 92.3% |
CIFAR 10: 91.78% |
| ResNet v1-44 | CIFAR 10: 92.46% |
CIFAR 10: 92.84% |
CIFAR 10: 92.33% |
| ResNet v1-56 | CIFAR 10: 92.21% |
CIFAR 10: 91.85% |
CIFAR 10: 91.97% |
| ResNet v1-110 | CIFAR 10: 91.44% |
CIFAR 10: 91.34% |
CIFAR 10: 91.69% |
| ResNet v1-164 | CIFAR 10: 83.62% |
CIFAR 10: 82.19% |
CIFAR 10: 82.37% |
| ResNet v2-20 | CIFAR 10: 92.02% |
CIFAR 10: 91.61% |
CIFAR 10: 91.71% |
| ResNet v2-56 | CIFAR 10: 87.18% |
CIFAR 10: 86.36% |
CIFAR 10: 83.86% |
| ResNet v2-110 | CIFAR 10: 92.58% |
CIFAR 10: 92.22% |
CIFAR 10: 91.93% |
| ResNet v2-164 | CIFAR 10: 87.74% |
CIFAR 10: 86.13% |
CIFAR 10: 83.59% |
| ResNet v2-245 | CIFAR 10: 86.67% |
CIFAR 10: 85.41% |
CIFAR 10: 86.32% |
| WRN 10-2 | CIFAR 10: 86.83% |
CIFAR 10: 86.56% |
CIFAR 10: 84.52% |
| WRN 16-4 | CIFAR 10: 90.54% |
CIFAR 10: 90.07% |
CIFAR 10: 90.74% |
| WRN 22-10 | CIFAR 10: 90.38% |
CIFAR 10: 90.17% |
CIFAR 10: 91.28% |
| WRN 40-4 | CIFAR 10: NA |
CIFAR 10: NA |
CIFAR 10: NA |
| VGG 16 | CIFAR 10: NA |
CIFAR 10: NA |
CIFAR 10: NA |
| SimpleNet | CIFAR 10: 91.70% |
CIFAR 10: 91.44% |
CIFAR 10: 91.16% |
| Xception Net | CIFAR 10: 88.73% |
CIFAR 10: 88.56% |
CIFAR 10: 88.38% |
| Capsule Network | CIFAR 10: 83.15% |
CIFAR 10: 82.48% |
CIFAR 10: 82.19% |
| Inception ResNet v2 | CIFAR 10: 85.21% |
CIFAR 10: 84.96% |
CIFAR 10: 82.22% |
| DenseNet-121 | CIFAR 10: 91.2678% |
CIFAR 10: 90.9217% |
CIFAR 10: 91.0997% |
| DenseNet - 161 | CIFAR 10: 90.8228% |
CIFAR 10: 90.1602% |
CIFAR 10: 91.0206% |
| DenseNet - 169 | CIFAR 10: 90.5063% |
CIFAR 10: 90.6744% |
CIFAR 10: 91.6535% |
| DenseNet - 201 | CIFAR 10: 90.7338% |
CIFAR 10: 91.0107% |
CIFAR 10: 90.7239% |
| ResNext - 50 | CIFAR 10: 90.8327% |
CIFAR 10: 91.6238% |
CIFAR 10: 89.3592% |
| MobileNet v1 | CIFAR 10: 85.2749% |
CIFAR 10: 85.6903% |
CIFAR 10: 84.1179% |
| MobileNet v2 | CIFAR 10: 86.254% |
CIFAR 10: 86.0759% |
CIFAR 10: 86.0463% |
| SENet - 18 | CIFAR 10: 90.526% |
CIFAR 10: 89.4284% |
CIFAR 10: 90.1602% |
| SENet - 34 | CIFAR 10: 91.0997% |
CIFAR 10: 89.9624% |
CIFAR 10: 91.6733% |
| ShuffleNet v1 | CIFAR 10: 87.3121% |
CIFAR 10: 86.9462% |
CIFAR 10: 87.0451% |
| ShuffleNet v2 | CIFAR 10: 87.37% |
CIFAR 10: 86.9363% |
CIFAR 10: 87.0055% |
| SqueezeNet | CIFAR 10: 88.13% |
CIFAR 10: 88.3703% |
CIFAR 10: 87.8461% |
| Inception v3 | CIFAR 10: 91.8314% |
CIFAR 10: 91.1788% |
CIFAR 10: 90.8426% |
| Efficient Net B0 | CIFAR 10: 80.7358% |
CIFAR 10: 79.371% |
CIFAR 10: 79.3117% |
| Efficient Net B1 | CIFAR 10: 80.9632% |
CIFAR 10: 81.9818% |
CIFAR 10: 82.4367% |
| Efficient Net B2 | CIFAR 10: 81.2006% |
CIFAR 10: 80.9039% |
CIFAR 10: 81.7148% |



