Papermill
Papermill is a tool for parameterizing, executing, and analyzing
Jupyter Notebooks.
Papermill lets you:
- parametrize notebooks
- execute and collect metrics across the notebooks
- summarize collections of notebooks
This opens up new opportunities for how notebooks can be used. For
example:
- Perhaps you have a financial report that you wish to run with
different values on the first or last day of a month or at the
beginning or end of the year, using parameters makes this task
easier. - Do you want to run a notebook and depending on its results, choose a
particular notebook to run next? You can now programmatically
execute a workflow without having to copy and paste from
notebook to notebook manually. - Do you have plots and visualizations spread across 10 or more
notebooks? Now you can choose which plots to programmatically
display a summary collection in a notebook to share with
others.
Installation
From the commmand line:
pip install papermill
Installing In-Notebook bindings
Other language bindings welcome if someone would like to maintain parallel implementations!
Usage
Parametrizing a Notebook
To parametrize your notebook designate a cell with the tag parameters.
Papermill looks for the parameters cell and treats this cell as defaults for the parameters passed in at execution time. Papermill will add a new cell tagged with injected-parameters with input parameters in order to overwrite the values in parameters. If no cell is tagged with parameters the injected cell will be inserted at the top of the notebook.
Additionally, if you rerun notebooks through papermill and it will reuse the injected-parameters cell from the prior run. In this case papermill will replace the old injected-parameters cell with the new run's inputs.

Executing a Notebook
The two ways to execute the notebook with parameters are: (1) through
the Python API and (2) through the command line interface.
Execute via the Python API
import papermill as pm
pm.execute_notebook(
'path/to/input.ipynb',
'path/to/output.ipynb',
parameters = dict(alpha=0.6, ratio=0.1)
)
Execute via CLI
Here's an example of a local notebook being executed and output to an
Amazon S3 account:
$ papermill local/input.ipynb s3://bkt/output.ipynb -p alpha 0.6 -p l1_ratio 0.1
Python In-notebook Bindings
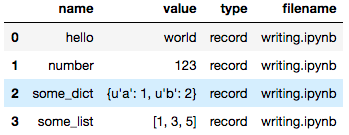
Recording Values to the Notebook
Users can save values to the notebook document to be consumed by other
notebooks.
Recording values to be saved with the notebook.
"""notebook.ipynb"""
import papermill as pm
pm.record("hello", "world")
pm.record("number", 123)
pm.record("some_list", [1, 3, 5])
pm.record("some_dict", {"a": 1, "b": 2})
Users can recover those values as a Pandas dataframe via the
read_notebook function.
"""summary.ipynb"""
import papermill as pm
nb = pm.read_notebook('notebook.ipynb')
nb.dataframe
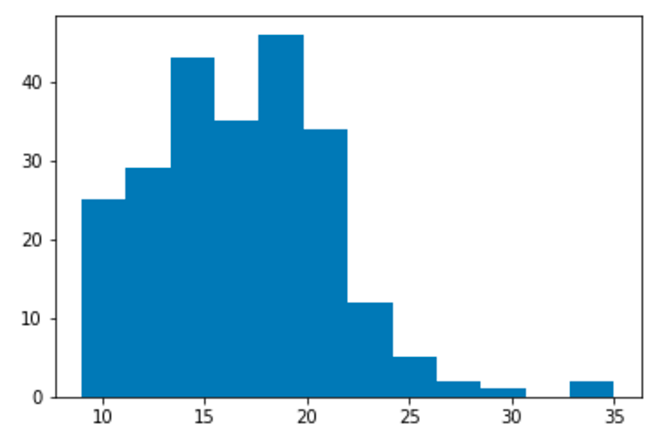
Displaying Plots and Images Saved by Other Notebooks
Display a matplotlib histogram with the key name matplotlib_hist.
"""notebook.ipynb"""
import papermill as pm
from ggplot import mpg
import matplotlib.pyplot as plt
# turn off interactive plotting to avoid double plotting
plt.ioff()
f = plt.figure()
plt.hist('cty', bins=12, data=mpg)
pm.display('matplotlib_hist', f)
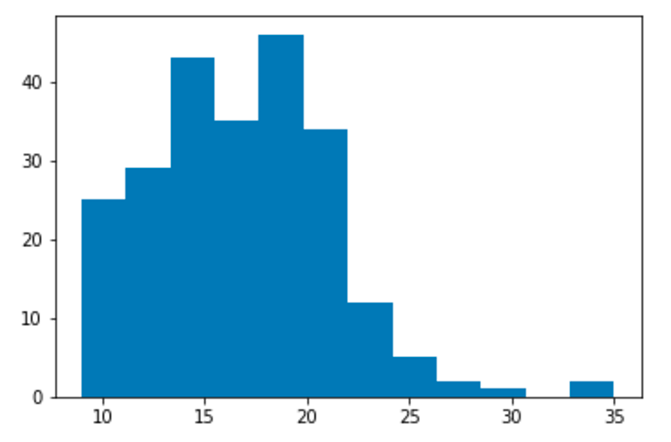
Read in that above notebook and display the plot saved at
matplotlib_hist.
"""summary.ipynb"""
import papermill as pm
nb = pm.read_notebook('notebook.ipynb')
nb.display_output('matplotlib_hist')
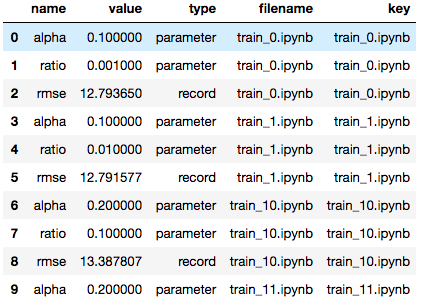
Analyzing a Collection of Notebooks
Papermill can read in a directory of notebooks and provides the
NotebookCollection interface for operating on them.
"""summary.ipynb"""
import papermill as pm
nbs = pm.read_notebooks('/path/to/results/')
# Show named plot from 'notebook1.ipynb'
# Accepts a key or list of keys to plot in order.
nbs.display_output('train_1.ipynb', 'matplotlib_hist')
# Dataframe for all notebooks in collection
nbs.dataframe.head(10)