dlrm
An implementation of a deep learning recommendation model (DLRM) The model input consists of dense and sparse features. The former is a vector of floating point values. The latter is a list of sparse indices into embedding tables, which consist of vectors of floating point values. The selected vectors are passed to mlp networks denoted by triangles, in some cases the vectors are interacted through operators (Ops).
output:
probability of a click
model: |
/\
/__\
|
_____________________> Op <___________________
/ | \
/\ /\ /\
/__\ /__\ ... /__\
| | |
| Op Op
| ____/__\_____ ____/__\____
| |_Emb_|____|__| ... |_Emb_|__|___|
input:
[ dense features ] [sparse indices] , ..., [sparse indices]
More precise definition of model layers:
-
fully connected layers of an mlp
z = f(y)
y = Wx + b
-
embedding lookup (for a list of sparse indices p=[p1,...,pk])
z = Op(e1,...,ek)
obtain vectors e1=E[:,p1], ..., ek=E[:,pk]
-
Operator Op can be one of the following
Sum(e1,...,ek) = e1 + ... + ek
Dot(e1,...,ek) = [e1'e1, ..., e1'ek, ..., ek'e1, ..., ek'ek]
Cat(e1,...,ek) = [e1', ..., ek']'
where ' denotes transpose operation
Reference:
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang,
Narayanan Sundaram, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu,
Alisson G. Azzolini, Dmytro Dzhulgakov, Andrey Mallevich, Ilia Cherniavskii,
Yinghai Lu, Raghuraman Krishnamoorthi, Ansha Yu, Volodymyr Kondratenko,
Stephanie Pereira, Xianjie Chen, Wenlin Chen, Vijay Rao, Bill Jia, Liang Xiong,
Misha Smelyanskiy, "Deep Learning Recommendation Model for Personalization and
Recommendation Systems", CoRR, arXiv:1906.00091, May, 2019
Implementation
DLRM PyTorch. Implementation of DLRM in PyTorch framework:
dlrm_s_pytorch.py
DLRM Caffe2. Implementation of DLRM in Caffe2 framework:
dlrm_s_caffe2.py
DLRM Data. Implementation of DLRM data generation and loading:
dlrm_data_pytorch.py, dlrm_data_caffe2.py, data_utils.py
DLRM Tests. Implementation of DLRM tests in ./test
dlrm_s_test.sh
DLRM Benchmarks. Implementation of DLRM benchmarks in ./bench
dlrm_s_benchmark.sh, dlrm_s_criteo_kaggle.sh
How to run dlrm code?
- A sample run of the code, with a tiny model is shown below
$ python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6
time/loss/accuracy (if enabled):
Finished training it 1/3 of epoch 0, -1.00 ms/it, loss 0.451893, accuracy 0.000%
Finished training it 2/3 of epoch 0, -1.00 ms/it, loss 0.402002, accuracy 0.000%
Finished training it 3/3 of epoch 0, -1.00 ms/it, loss 0.275460, accuracy 0.000%
- A sample run of the code, with a tiny model in debug mode
$ python dlrm_s_pytorch.py --mini-batch-size=2 --data-size=6 --debug-mode
model arch:
mlp top arch 3 layers, with input to output dimensions:
[8 4 2 1]
# of interactions
8
mlp bot arch 2 layers, with input to output dimensions:
[4 3 2]
# of features (sparse and dense)
4
dense feature size
4
sparse feature size
2
# of embeddings (= # of sparse features) 3, with dimensions 2x:
[4 3 2]
data (inputs and targets):
mini-batch: 0
[[0.69647 0.28614 0.22685 0.55131]
[0.71947 0.42311 0.98076 0.68483]]
[[[1], [0, 1]], [[0], [1]], [[1], [0]]]
[[0.55679]
[0.15896]]
mini-batch: 1
[[0.36179 0.22826 0.29371 0.63098]
[0.0921 0.4337 0.43086 0.49369]]
[[[1], [0, 2, 3]], [[1], [1, 2]], [[1], [1]]]
[[0.15307]
[0.69553]]
mini-batch: 2
[[0.60306 0.54507 0.34276 0.30412]
[0.41702 0.6813 0.87546 0.51042]]
[[[2], [0, 1, 2]], [[1], [2]], [[1], [1]]]
[[0.31877]
[0.69197]]
initial parameters (weights and bias):
[[ 0.05438 -0.11105]
[ 0.42513 0.34167]
[-0.1426 -0.45641]
[-0.19523 -0.10181]]
[[ 0.23667 0.57199]
[-0.16638 0.30316]
[ 0.10759 0.22136]]
[[-0.49338 -0.14301]
[-0.36649 -0.22139]]
[[0.51313 0.66662 0.10591 0.13089]
[0.32198 0.66156 0.84651 0.55326]
[0.85445 0.38484 0.31679 0.35426]]
[0.17108 0.82911 0.33867]
[[0.55237 0.57855 0.52153]
[0.00269 0.98835 0.90534]]
[0.20764 0.29249]
[[0.52001 0.90191 0.98363 0.25754 0.56436 0.80697 0.39437 0.73107]
[0.16107 0.6007 0.86586 0.98352 0.07937 0.42835 0.20454 0.45064]
[0.54776 0.09333 0.29686 0.92758 0.569 0.45741 0.75353 0.74186]
[0.04858 0.7087 0.83924 0.16594 0.781 0.28654 0.30647 0.66526]]
[0.11139 0.66487 0.88786 0.69631]
[[0.44033 0.43821 0.7651 0.56564]
[0.0849 0.58267 0.81484 0.33707]]
[0.92758 0.75072]
[[0.57406 0.75164]]
[0.07915]
DLRM_Net(
(emb_l): ModuleList(
(0): EmbeddingBag(4, 2, mode=sum)
(1): EmbeddingBag(3, 2, mode=sum)
(2): EmbeddingBag(2, 2, mode=sum)
)
(bot_l): Sequential(
(0): Linear(in_features=4, out_features=3, bias=True)
(1): ReLU()
(2): Linear(in_features=3, out_features=2, bias=True)
(3): ReLU()
)
(top_l): Sequential(
(0): Linear(in_features=8, out_features=4, bias=True)
(1): ReLU()
(2): Linear(in_features=4, out_features=2, bias=True)
(3): ReLU()
(4): Linear(in_features=2, out_features=1, bias=True)
(5): Sigmoid()
)
)
time/loss/accuracy (if enabled):
Finished training it 1/3 of epoch 0, -1.00 ms/it, loss 0.451893, accuracy 0.000%
Finished training it 2/3 of epoch 0, -1.00 ms/it, loss 0.402002, accuracy 0.000%
Finished training it 3/3 of epoch 0, -1.00 ms/it, loss 0.275460, accuracy 0.000%
updated parameters (weights and bias):
[[ 0.0543 -0.1112 ]
[ 0.42513 0.34167]
[-0.14283 -0.45679]
[-0.19532 -0.10197]]
[[ 0.23667 0.57199]
[-0.1666 0.30285]
[ 0.10751 0.22124]]
[[-0.49338 -0.14301]
[-0.36664 -0.22164]]
[[0.51313 0.66663 0.10591 0.1309 ]
[0.32196 0.66154 0.84649 0.55324]
[0.85444 0.38482 0.31677 0.35425]]
[0.17109 0.82907 0.33863]
[[0.55238 0.57857 0.52154]
[0.00265 0.98825 0.90528]]
[0.20764 0.29244]
[[0.51996 0.90184 0.98368 0.25752 0.56436 0.807 0.39437 0.73107]
[0.16096 0.60055 0.86596 0.98348 0.07938 0.42842 0.20453 0.45064]
[0.5476 0.0931 0.29701 0.92752 0.56902 0.45752 0.75351 0.74187]
[0.04849 0.70857 0.83933 0.1659 0.78101 0.2866 0.30646 0.66526]]
[0.11137 0.66482 0.88778 0.69627]
[[0.44029 0.43816 0.76502 0.56561]
[0.08485 0.5826 0.81474 0.33702]]
[0.92754 0.75067]
[[0.57379 0.7514 ]]
[0.07908]
Testing
Testing scripts to confirm functional correctness of the code
./test/dlrm_s_tests.sh
Running commands ...
python dlrm_s_pytorch.py
python dlrm_s_caffe2.py
Checking results ...
diff test1 (no numeric values in the output = SUCCESS)
diff test2 (no numeric values in the output = SUCCESS)
diff test3 (no numeric values in the output = SUCCESS)
diff test4 (no numeric values in the output = SUCCESS)
NOTE: Testing scripts accept extra arguments which will passed along, such as --use-gpu
Benchmarking
-
Performance benchmarking
./bench/dlrm_s_benchmark.sh -
The code supports interface with the Kaggle Display Advertising Challenge Dataset.
Please do the following to prepare the dataset for use with DLRM code:- First, specify the raw data file (train.txt) as downloaded with --raw-data-file=<path/train.txt>
- This is then pre-processed (categorize, concat across days...) to allow using with dlrm code
- The processed data is stored as .npz file in <root_dir>/input/kaggle_data/.npz
- The processed file (.npz) can be used for subsequent runs with --processed-data-file=<path/.npz>
./bench/dlrm_s_criteo_kaggle.sh
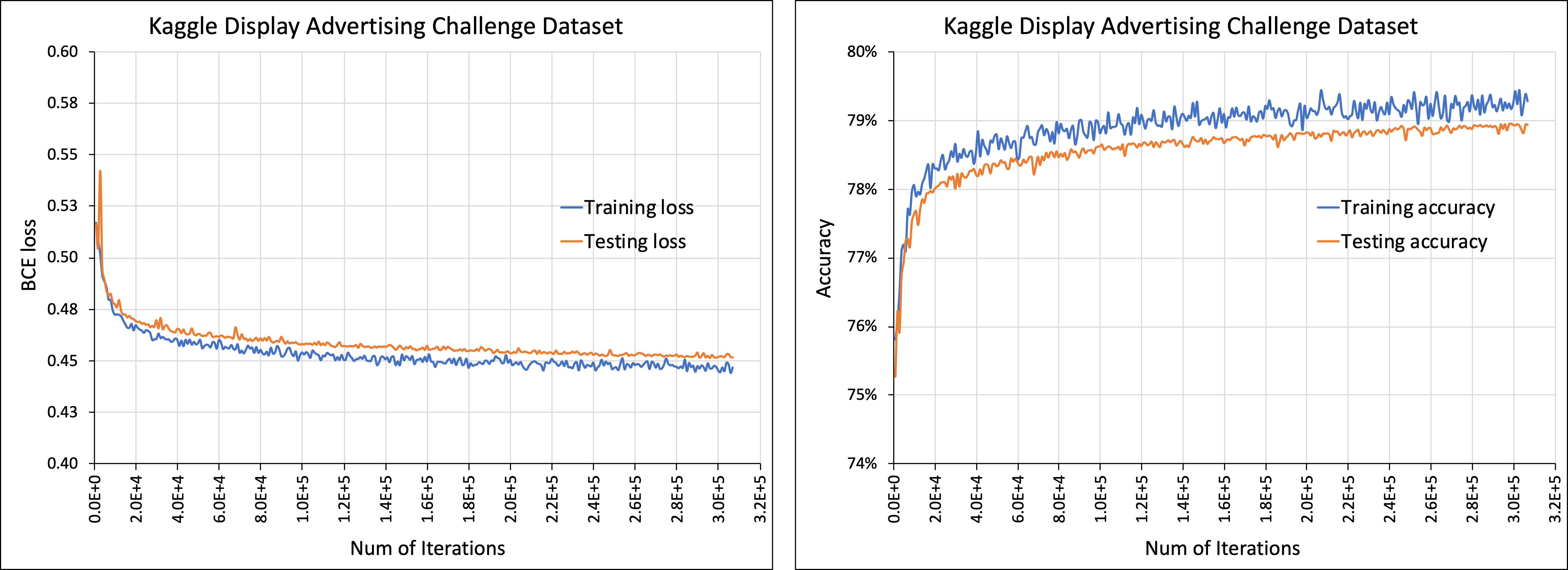
NOTE: Benchmarking scripts accept extra arguments which will passed along, such as --num-batches=100 to limit the number of data samples
Version
0.1 : Initial release of the DLRM code
Requirements
pytorch-nightly (6/10/19)
onnx (optional)
torchviz (optional)



