nnAudio
Audio processing by using pytorch 1D convolution network. By doing so, spectrograms can be generated from audio on-the-fly during neural network training. Kapre has a similar concept in which they also use 1D convolution from keras to do the waveforms to spectrogram conversions.
Other GPU audio processing tools are torchaudio and tf.signal. But they are not using the neural network approach, and hence the Fourier basis can not be trained.
The name of nnAudio comes from torch.nn, since most of the codes are built from torch.nn.
Dependencies
Numpy 1.14.5
Scipy 1.2.0
PyTorch 1.1.0
Python >= 3.6
librosa = 0.7.0 (Theortically nnAudio depends on librosa. But we only need to use a single function mel from librosa.filters. To save users troubles from installing librosa for this single function, I just copy the chunks of functions corresponding to mel in my code so that nnAudio runs without the need to install librosa)
Instructions
All the required codes and examples are inside the jupyter-notebook. The audio processing layer can be integrated as part of the neural network as shown below. The demo on colab is also avaliable.
Installation
pip install nnAudio
Standalone Usage
from nnAudio import Spectrogram
from scipy.io import wavfile
import torch
sr, song = wavfile.read('./Bach.wav') # Loading your audio
x = song.mean(1) # Converting Stereo to Mono
x = torch.tensor(x).float() # casting the array into a PyTorch Tensor
spec_layer = Spectrogram.STFT(n_fft=2048, freq_bins=None, hop_length=512,
window='hann', freq_scale='linear', center=True, pad_mode='reflect',
fmin=50,fmax=11025, sr=sr) # Initializing the model
spec = spec_layer(x) # Feed-forward your waveform to get the spectrogram
On-the-fly audio processing
One application for nnAudio is on-the-fly spectrogram generation when integrating it inside your neural network
class Model(torch.nn.Module):
def __init__(self, avg=.9998):
super(Model, self).__init__()
# Getting Mel Spectrogram on the fly
+ self.spec_layer = Spectrogram.STFT(sr=44100, n_fft=n_fft, freq_bins=freq_bins, fmin=50, fmax=6000, freq_scale='log', pad_mode='constant', center=True)
self.n_bins = freq_bins
# Creating CNN Layers
self.CNN_freq_kernel_size=(128,1)
self.CNN_freq_kernel_stride=(2,1)
k_out = 128
k2_out = 256
self.CNN_freq = nn.Conv2d(1,k_out,
kernel_size=self.CNN_freq_kernel_size,stride=self.CNN_freq_kernel_stride)
self.CNN_time = nn.Conv2d(k_out,k2_out,
kernel_size=(1,regions),stride=(1,1))
self.region_v = 1 + (self.n_bins-self.CNN_freq_kernel_size[0])//self.CNN_freq_kernel_stride[0]
self.linear = torch.nn.Linear(k2_out*self.region_v, m, bias=False)
def forward(self,x):
+ z = self.spec_layer(x)
z = torch.log(z+epsilon)
z2 = torch.relu(self.CNN_freq(z.unsqueeze(1)))
z3 = torch.relu(self.CNN_time(z2))
y = self.linear(torch.relu(torch.flatten(z3,1)))
return torch.sigmoid(y)
Using GPU
If GPU is avaliable in your computer, you should put the following command at the beginning of your script to ensure nnAudio is run in GPU. By default, PyTorch runs in CPU, so as nnAudio.
if torch.cuda.is_available():
device = "cuda:0"
torch.set_default_tensor_type('torch.cuda.FloatTensor')
else:
device = "cpu"
Functionalities
Currently there are 4 models to generate various types of spectrograms.
1. STFT
Spectrogram.STFT(n_fft=2048, freq_bins=None, hop_length=512, window='hann', freq_scale='no', center=True, pad_mode='reflect', fmin=50,fmax=6000, sr=22050, trainable=False)
freq_scale: 'no', 'linear', or 'log'. This options controls the spacing of frequency among Fourier basis. When chosing 'no', the STFT output is same as the librosa output. fmin and fmax will have no effect under this option. When chosing 'linear' or 'log', the frequency scale will be in linear scale or logarithmic scale with the
2. Mel Spectrogram
MelSpectrogram(sr=22050, n_fft=2048, n_mels=128, hop_length=512, window='hann', center=True, pad_mode='reflect', htk=False, fmin=0.0, fmax=None, norm=1, trainable_mel=False, trainable_STFT=False)
3. CQT Naive Approach
CQT1992v2(sr=22050, hop_length=512, fmin=220, fmax=None, n_bins=84, bins_per_octave=12, norm=1, window='hann', center=True, pad_mode='reflect')
4. CQT Down-sampling approach
CQT2010v2(sr=22050, hop_length=512, fmin=220, fmax=None, n_bins=84, bins_per_octave=12, norm=True, basis_norm=1, window='hann', pad_mode='reflect', earlydownsample=True)
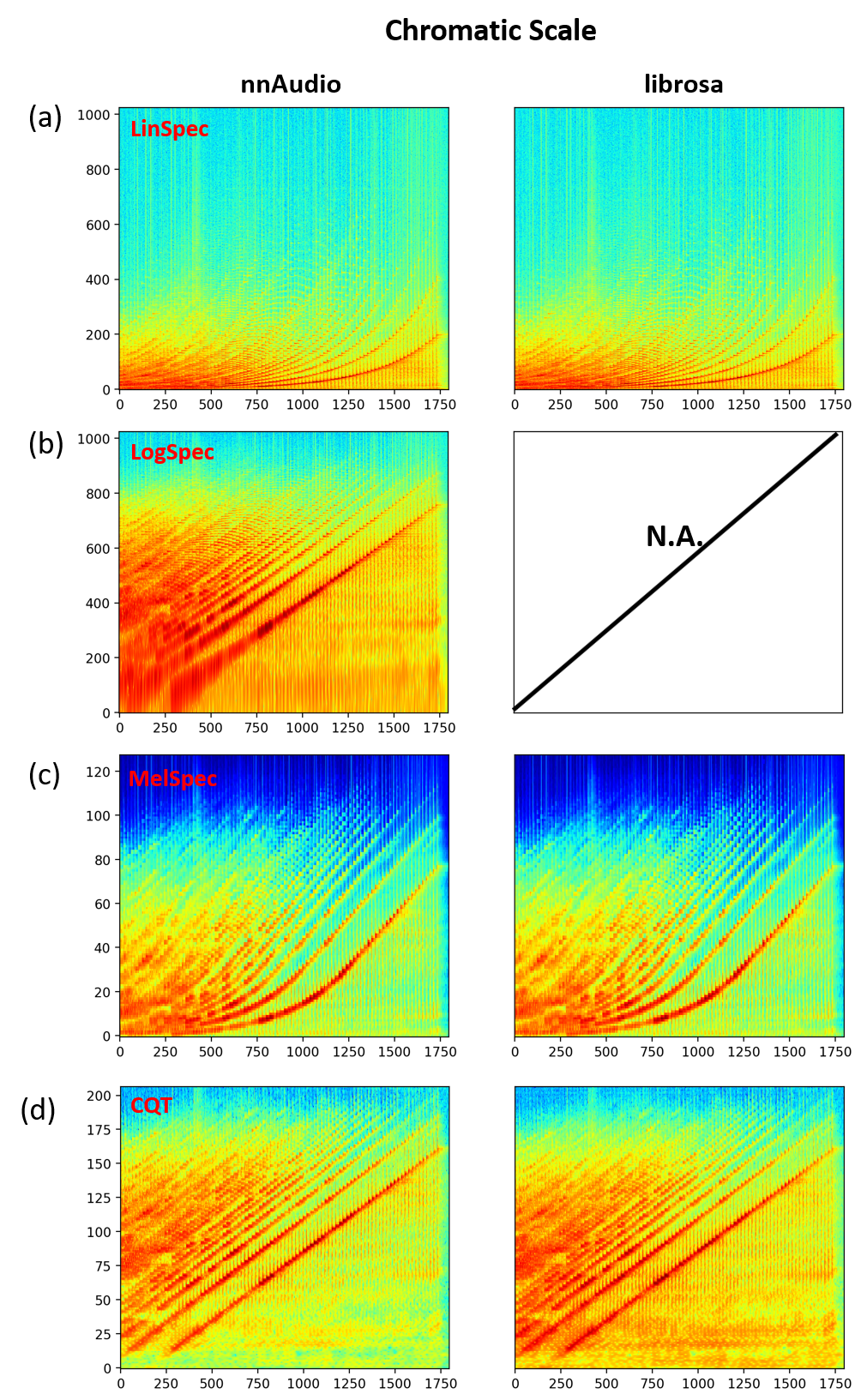
The spectrogram outputs from nnAudio are nearly identical to the implmentation of librosa. The only difference is CQT, where we normalized the CQT kernel with L1 norm and then CQT output is normalized with the CQT kernel length. I am unable to explain the normalization used by librosa.
To use nnAudio, you need to define the neural network layer. After that, you can pass a batch of waveform to that layer to obtain the spectrograms. The input shape should be (batch, len_audio).
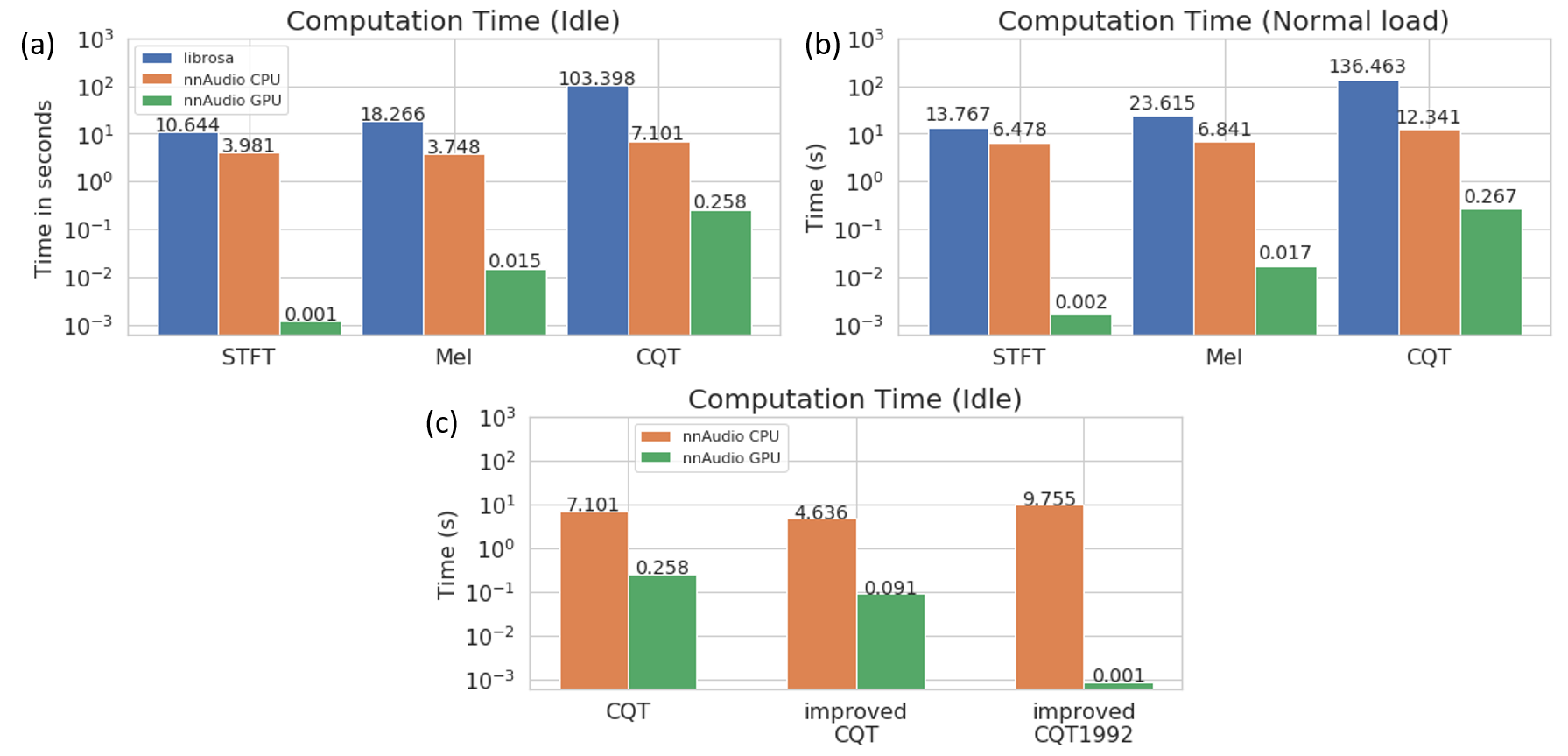
Speed
The speed test is conducted using DGX Station with the following specs
CPU: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz
GPU: Tesla v100 32gb
RAM: 256 GB RDIMM DDR4
During the test, only 1 single GPU is used, and the same test is conducted when
(a) the DGX is idel
(b) the DGX has ongoing jobs