Handwriting generation
There are 2 data files that you need to consider: data.npy and sentences.txt. data.npycontains 6000 sequences of points that correspond to handwritten sentences. sentences.txt contains the corresponding text sentences. You can see an example on how to load and plot an example sentence in example.ipynb. Each handwritten sentence is represented as a 2D array with T rows and 3 columns. T is the number of timesteps. The first column represents whether to interrupt the current stroke (i.e. when the pen is lifted off the paper). The second and third columns represent the relative coordinates of the new point with respect to the last point. Please have a look at the plot_stroke if you want to understand how to plot this sequence.
Unconditional generation.
Generated samples:

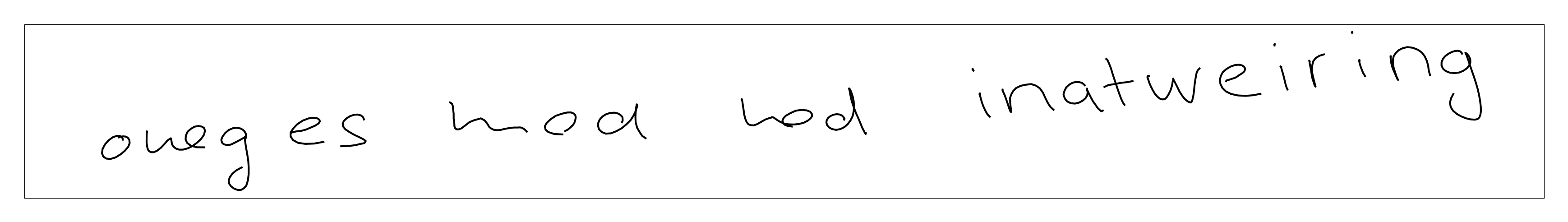
Samples generated using priming:
- Prime style text is "medical assistance", text after this is generated by model

- Prime style text is "something which he is passing on", text after this is generated by model

- Prime style text is "In Africa Jones hotels spring", text after this is generated by model

Conditional generation.
Generated samples:




