Anomagram
Anomagram is an interactive experience built with Tensorflow.js to demonstrate how deep neural networks (autoencoders) can be applied to the task of anomaly detection.

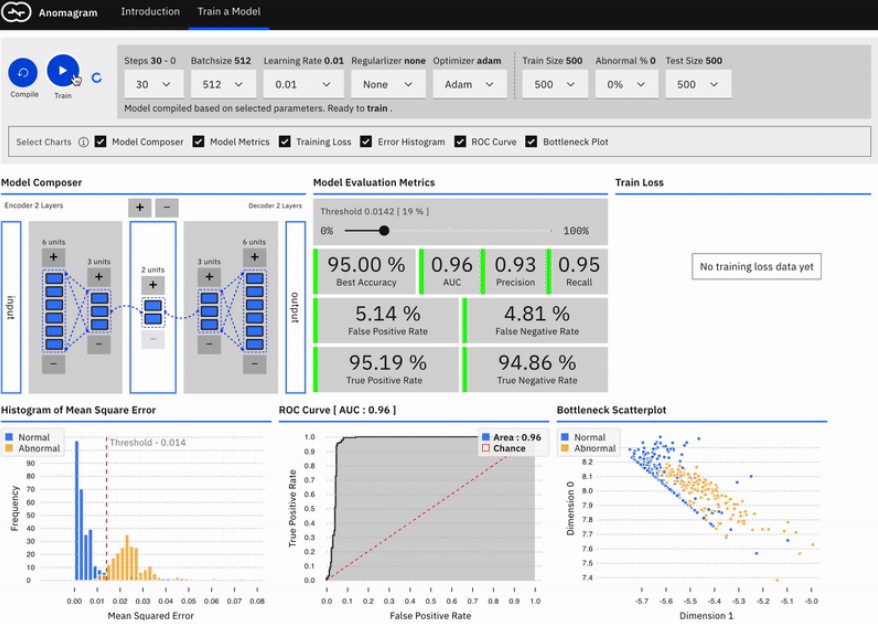
Screenshot above shows the train a model interface that allows you to specify the configuration of an autoencoder (number of layers, number of units in each layer), specify training parameters (steps, batchsize, learning rate, optimizer, regularizer) train it, and evaluate (mse histogram, ROC chart, Loss charts) its performance on test dataset.
Screenshot above shows the introduction interface where you can perform inference using a trained autoencoder implemented in Tensorflow js. The user can either run inference on a test data sample or draw an ECG signal as input and observe the model's behaviour.
Why Anomagram
Machine learning models can be complex to both understand and apply effectively. As ML becomes increasingly relevant to many business problems, it is important to create accessible interfaces that enable non-ML experts (citizen data scientists, software developers, designers etc) to experiment with ML models, and with as little overhead as possible. Anomagram is designed as part of a growing area interactive visualizations (see Neural Network Playground [3], ConvNet Playground, GANLab, GAN dissection, etc) that help communicate technical insights on how deep learning models work. It is entirely browser based, implemented in Tensorflow.js, no installations required. Importantly, Anomagram moves beyond the user of toy/synthetic data and situates learning within the context of a concrete task (anomaly detection for ECG data). The overall user experience goals for Anomagram are summarized as follows.
-
Provide an introduction to Autoencoders and how they can be applied to the task of anomaly detection. This involves providing definitions of concepts (reconstruction error, thresholds etc) and interactive visualizations that demonstrate concepts (e.g. an interactive visualization for inference on test data, a visualization of the structure of an autoencoder, visualization of error histograms as training progresses, etc).
-
Provide an interactive, accessible experience with explanations that support learning by doing. This involves providing a direct manipulation interface that allows the user to specify a model (add/remove layers and units within layers), modify model parameters (training steps, batchsize, learning rate, regularizer, optimizer, etc), modify training/test data parameters (data size, data composition), train the model, and evaluate model performance (visualization of accuracy, precision, recall, false positive, false negative, ROC etc metrics) as each parameter is changed.
Who should use Anomagram? Anyone interested in an accessible way to learn about autoencoders and anomaly detection . Useful for educators (tool to support guided discussion of the topic), entry level data scientists, and non-ML experts (citizen data scientists, software developers, designers etc).
To achieve these goals, the prototype has two main modules (shown in the screenshots above) - an introduction module that provides discussions of concepts, paired with interactive visualizations, and a train a model module where users can build, train and evaluate an autoencoder from scratch.
Gentle Introduction to Anomaly Detection
An outlier is an observation which deviates so much from other observations as to arouse suspicions that it was generated by a different mechanism - Hawkins 1980.
Anomalies often referred to as outliers, abnormalities, rare events or deviants are data points or patterns in data that do not adhere or conform to a well-defined notion of normal behavior. Anomaly detection is therefore defined as the task of finding patterns in data that do not adhere to a well-defined notion of normal behavior.
At the heart of most approaches to anomaly detection (and by Merlin's beard ... there are a lot), is the fundamental concept of modeling "normal behavior". Once this is achieved, we can leverage this knowledge/mechanism in assigning an anomaly score (a measure of "normalness") to new data points test time.
Various approaches differ on how normal behavior is modelled and how an anomaly score is assigned. Time series forecasting approaches tend to first forecast future values and compute an anomaly score as the difference between predictions and actual values.
Existing approaches for anomaly detection typically focus on time series data and univariate data streams (e.g. number of concurrent users of a telecoms base station over time). However, as data include more variables, it becomes more challenging to model each stream individually and aggregate results. For these situations, deep learning can be valuable.
Deep Learning (Using Autoencoders) for Anomaly Detection.
An Autoencoder is a type of artificial neural network used to learn efficient (low dimensional) data representations in an unsupervised manner. It is typically comprised of two components - an encoder that learns to map input data to a low dimension representation ( also called a bottleneck, denoted by z ) and a decoder that learns to reconstruct the original signal from the low dimension representation. The training objective for the autoencoder model is to minimize the reconstruction error - the difference between the input data and the reconstructed output.
Applying Autoencoders for Anomaly Detection
While autoencoder models have been widely applied for dimensionality reduction (similar to techniques such as PCA), they can also be used for anomaly detection. If we train the model on normal data (or data with very few abnormal samples), it learns a reconstruction function that works well for normal looking data (low reconstruction error) and works poorly for abnormal data (high reconstruction error). We can then use reconstruction error as a signal for anomaly detection.
In particular, if we visualize a histrogram of reconstruction errors generated by a trained autoencoder, we hopefully will observe that the distribution of errors for normal samples is overall smaller and markedly separate from the distribution of errors for abnormal data.
Note: We may not always have labelled data, but we can can assume (given the rare nature of anomalies) that the majority of data points for most anomaly detection use cases are normal. See the section below that discusses the impact of data composition (% of abnormal data) on model performance.
Dataset
This prototype uses the ECG5000 dataset which contains 5000 examples of ECG signals from a patient. Each sample (which has been sliced into 140 points corresponding to an extracted heartbeat) has been labelled as normal or being indicative of heart conditions related to congestive heart failure.
Data Transformation
Prior to training the autoencoder, we first apply a minmax scaling transform to the input data which converts it from its original range (2 to -5) to a range of 0 -1 This is done for two main reasons. First, existing research suggests that neural networks in general train better when input values lie between 0 and 1 (or have zero mean and unit variance). Secondly, scaling the data supports the learning objective for the autoencoder (minimizing reconstruction error) and makes the results more interpretable. In general, the range of output values from the autoencoder is dependent on the type of activation function used in the output layer. For example, the tanh activation function outputs values in the range of -1 and 1, sigmoid outputs values in the range of 0 - 1 In the example above, we use the sigmoid activation function in the output layer of the autoencoder, allowing us directly compare the transformed input signal to the output data when computing the means square error metric during training. In addition, having both input and output in the same range allows us to visualize the differences that contribute to the anomaly classification. Note:The parameters of the scaling transform should be computed only on training data and then applied to test data.
Closing Notes
In this prototype, we have considered the task of detecting anomalies in ECG data. We used an autoencoder and demonstrate some fairly good results with minimal tuning. We have also explored how and why it works. This and other neural approaches (Sequence to Sequence Models, Variational Autoencoders, BiGANs etc) can be particularly effective for anomaly detection with multivariate or high dimensional datasets such as images (think convolutional layers instead of dense layers).
Note: A deep learning model is not always the best tool for the job. Particularly, for univariate data (and low dimension data ) , autoregressive linear models (linear regression, ARIMA family of models for time series), Clustering (PCA etc, KMeans), Nearest Neighbour (KNNs) can be very effective. It is also important to note that the data used here is stationary (mean and variance do not change with time), and has been discretized (a typical ECG time series chunked into slices of 140 readings, where each slice constitutes a sample in the dataset). To apply an autoencoder (and other deep learning models) for anomaly detection it is often necessary to first handle stationarity (if it exists) and construct an appropriate dataset based on domain knowledge (chunk/discretize your data). Interested in learning more about other deep learning approaches to anomaly detection? My colleagues and I cover additional details on this topic in the upcoming Fast Forward Labs 2020 report on Deep Learning for Anomaly Detection.
Repository Structure
This repository mainly contains code for the Anomagram demo built with React.js ( app folder) . The experiments folder
contains Tensorflow.js code (node.js backend) that trains a two layer autoencoder and exports a model.



