Neural speaker diarization with pyannote-audio
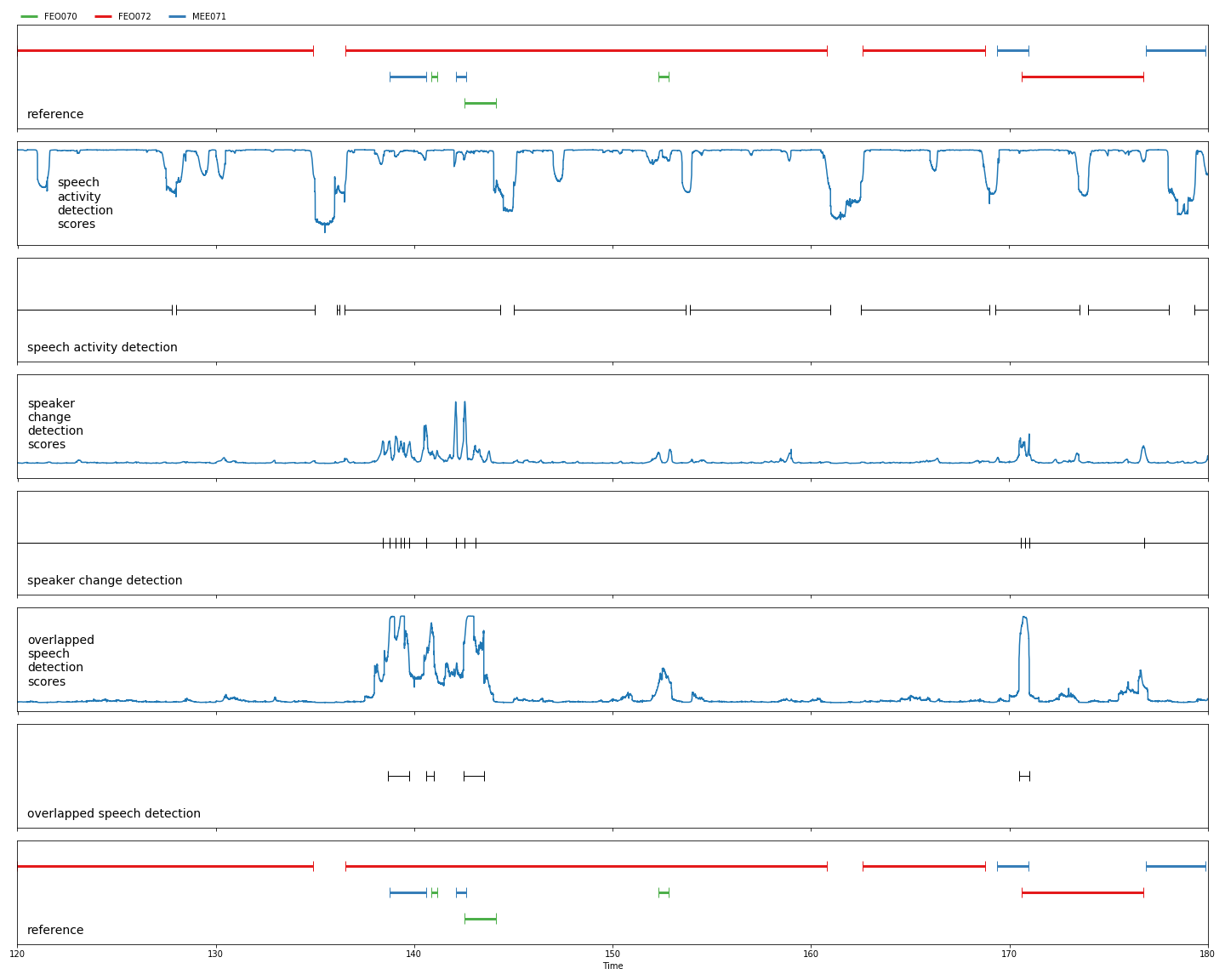
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch machine learning framework, it provides a set of trainable end-to-end neural building blocks that can be combined and jointly optimized to build speaker diarization pipelines:

pyannote.audio also comes with pretrained models covering a wide range of domains for voice activity detection, speaker change detection, overlapped speech detection, and speaker embedding:
![]()
Installation
pyannote.audio only supports Python 3.7 (or later) on Linux and macOS. It might work on Windows but there is no garantee that it does, nor any plan to add official support for Windows.
The instructions below assume that pytorch has been installed using the instructions from https://pytorch.org.
$ pip install pyannote.audio==1.1.1





