VoiceSmith [WIP]
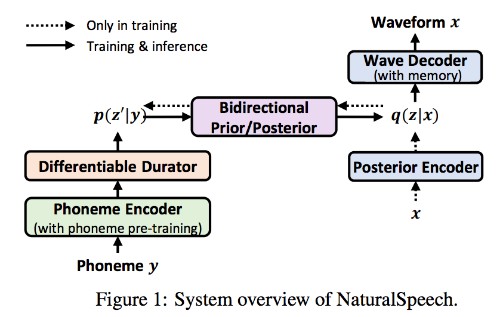
VoiceSmith makes it possible to train and infer on both single and multispeaker models without any coding experience. It fine-tunes a pretty solid text to speech pipeline based on a modified version of DelightfulTTS and UnivNet on your dataset. Both models were pretrained on a proprietary 5000 speaker dataset. It also provides some tools for dataset preprocessing like automatic text normalization.
If you want to play around with a model trained on a highly emotional emotional 60 speaker dataset using an earlier version of this software click here.

Requirements
Hardware
- OS: Windows or any Linux based operating system. If you want to run this on macOS you have to follow the steps in build from source in order to create the installer. This is untested since I don’t currently own a Mac.
- Graphics: NVIDIA GPU with CUDA support is highly recommended, you can train on CPU otherwise but it will take days if not weeks.
- RAM: 8GB of RAM, you can try with less but it may not work.
Software
- Python >=3.7,<3.11, you can download it here.
- Docker, you can download it here.
How to install
- Download the latest installer from the releases page.
- Double click to run the installer.
How to develop
-
Make sure you have the latest version of Node.js installed
-
Clone the repository
git clone https://github.com/dunky11/voicesmith -
Install dependencies, this can take a minute
cd voicesmith npm install -
Click here, select the folder with the latest version, download all files and place them inside the repositories assets folder.
-
Start the project
npm start
Build from source
-
Follow steps 1 – 4 from above.
-
Run make, this will create a folder named out/make with an installer inside. The installer will be different based on your operating system.
npm make
Contribute
Show your support by ⭐ the project. Pull requests are always welcome.
License
This project is licensed under the Apache-2.0 license – see the LICENSE.md file for details.