Action-Based Conversations Dataset (ABCD)
This respository contains the code and data for ABCD (Chen et al., 2021)
Official repository for "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems"
Whereas existing goal-oriented dialogue datasets focus mainly on identifying user intents, customer interactions in reality often involve agents following multi-step procedures derived from explicitly-defined guidelines. For example, in a online shopping scenario, a customer might request a refund for a past purchase. However, before honoring such a request, the agent should check the company policies to see if a refund is warranted. It is very likely that the agent will need to verify the customer's identity and check that the purchase was made within a reasonable timeframe.
To study dialogue systems in more realistic settings, we introduce the Action-Based Conversations Dataset (ABCD), where an agent's actions must be balanced between the desires expressed by the customer and the constraints set by company policies. The dataset contains over 10K human-to-human dialogues with 55 distinct user intents requiring unique sequences of actions to achieve task success. We also design a new technique called Expert Live Chat for collecting data when there are two unequal users engaging in real-time conversation. Please see the paper for more details.
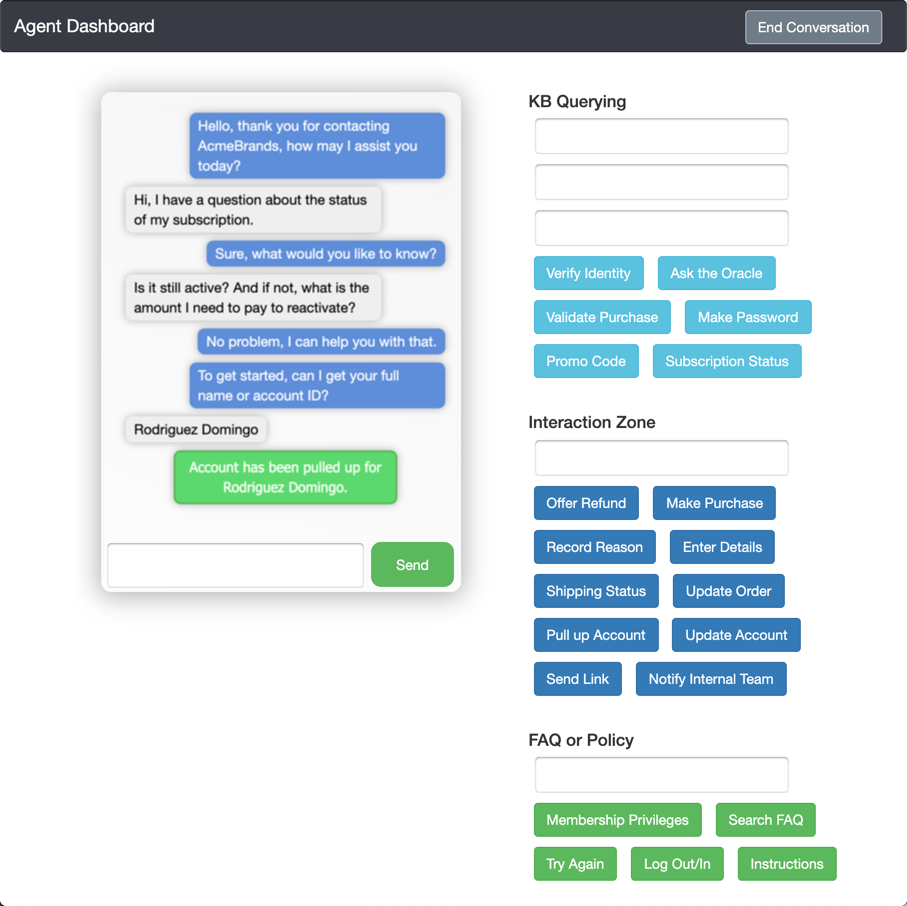
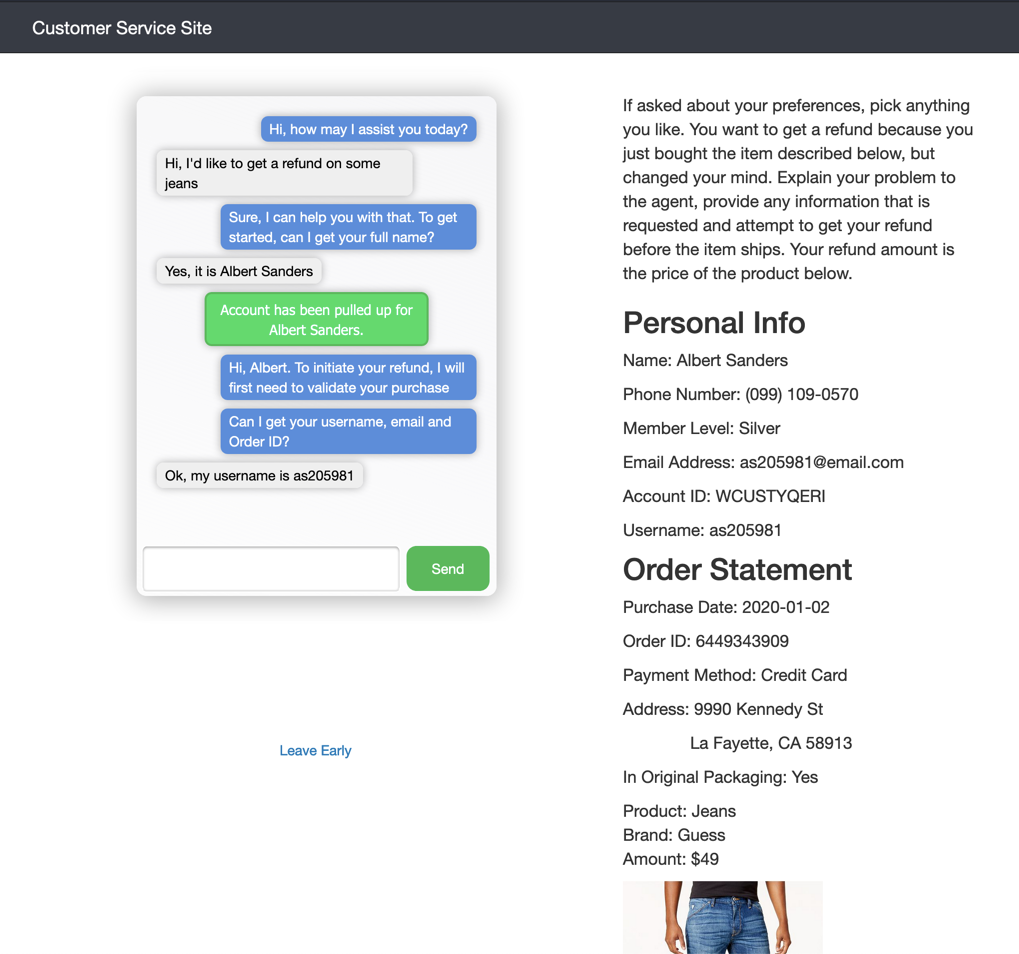
Usage
All code is run by executing the corresponding command within the shell script run.sh, which will kick off the data preparation and training within main.py. To use, first unzip the file found in data/abcd_v1.1.json.gz using the gunzip command (or similar). Then comment or uncomment the appropriate lines in the shell script to get desired behavior. Finally, enter sh run.sh into the command line to get started. Use the --help option of argparse for flag details or read through the file located within utils/arguments.py.
Preparation
Raw data will be loaded from the data folder and prepared into features that are placed into Datasets. If this has already occured, then the system will instead read in the prepared features from cache.
If running CDS for the first time, uncomment out the code within the run script to execute embed.py which will prepare the utterances for ranking.
Training
To specify the task for training, simply use the --task option with either ast or cds, for Action State Tracking and Cascading Dialogue Success respectively. Options for different model types are bert, albert and roberta. Loading scripts can be tuned to offer various other behaviors.
Evaluation
Activate evaluation using the --do-eval flag. By default, run.sh will perform cascading evaluation. To include ablations, add the appropriate options of --use-intent or --use-kb.
Data
The preprocessed data is found in abcd_v1.1.json which is a dictionary with keys of train, dev and test.
Each split is a list of conversations, where each conversation is a dict containing:
- convo_id: a unique conversation identifier
- scenario: the ground truth scenario used to generate the prompt
- original: the raw conversation of speaker and utterances as a list of tuples
- delexed: the delexicalized conversation used for training and evaluation, see below for details
We provide the delexed version so new models performing the same tasks have comparable pre-processing. The original data is also provided in case you want to use the utterances for some other purpose.
For a quick preview, a small sample of chats is provided to help get started. Concretely, abcd_sample.json is a list containing three random conversations from the training set.
Scenario
Each scene dict contains details about the customer setup along with the underlying flow and subflow information an agent should use to address the customer concern. The components are:
- Personal: personal data related to the (fictional) customer including account_id, customer name, membership level, phone number, etc.
- Order: order info related to what the customer purchased or would like to purchase. Includes address, num_products, order_id, product names, and image info
- Product: product details if applicable, includes brand name, product type and dollar amount
- Flow and Subflow: these represent the ground truth user intent. They are used to generate the prompt, but are not shown directly the customer. The job of the agent is to infer this (latent) intent and then match against the Agent Guidelines to resolve the customer issue.
Guidelines
The agent guidelines are offered in their original form within Agent Guidelines for ABCD. This has been transformed into a formatted document for parsing by a model within data/guidelines.json. The intents with their button actions about found within kb.json. Lastly, the breakdown of all flows, subflows, and actions are found within ontology.json.
Conversation
Each conversation is made up of a list of turns. Each turn is a dict with five parts:
- Speaker: either "agent", "customer" or "action"
- Text: the utterance of the agent/customer or the system generated response of the action
- Turn_Count: integer representing the turn number, starting from 1
- Targets : list of five items representing the subtask labels
- Intent Classification (text) - 55 subflow options
- Nextstep Selection (text) - take_action, retrieve_utterance or end_conversation; 3 options
- Action Prediction (text) - the button clicked by the agent; 30 options
- Value Filling (list) - the slot value(s) associated with the action above; 125 options
- Utterance Ranking (int) - target position within list of candidates; 100 options
- Candidates: list of utterance ids representing the pool of 100 candidates to choose from when ranking. The surface form text can be found in
utterances.jsonwhere the utt_id is the index. Only applicable when the current turn is a "retrieve_utterance" step.
In contrast to the original conversation, the delexicalized version will replace certain segments of text with special tokens. For example, an utterance might say "My Account ID is 9KFY4AOHGQ". This will be changed into "my account id is <account_id>".
Contact
Please email [email protected] for questions or feedback.
Citation
@inproceedings{chen2021abcd,
title = "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems",
author = "Chen, Derek and
Chen, Howard and
Yang, Yi and
Lin, Alex and
Yu, Zhou",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, {NAACL-HLT} 2021",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.naacl-main.239",
pages = "3002--3017"
}





