gdc
A Distributional Approach To Controlled Text Generation
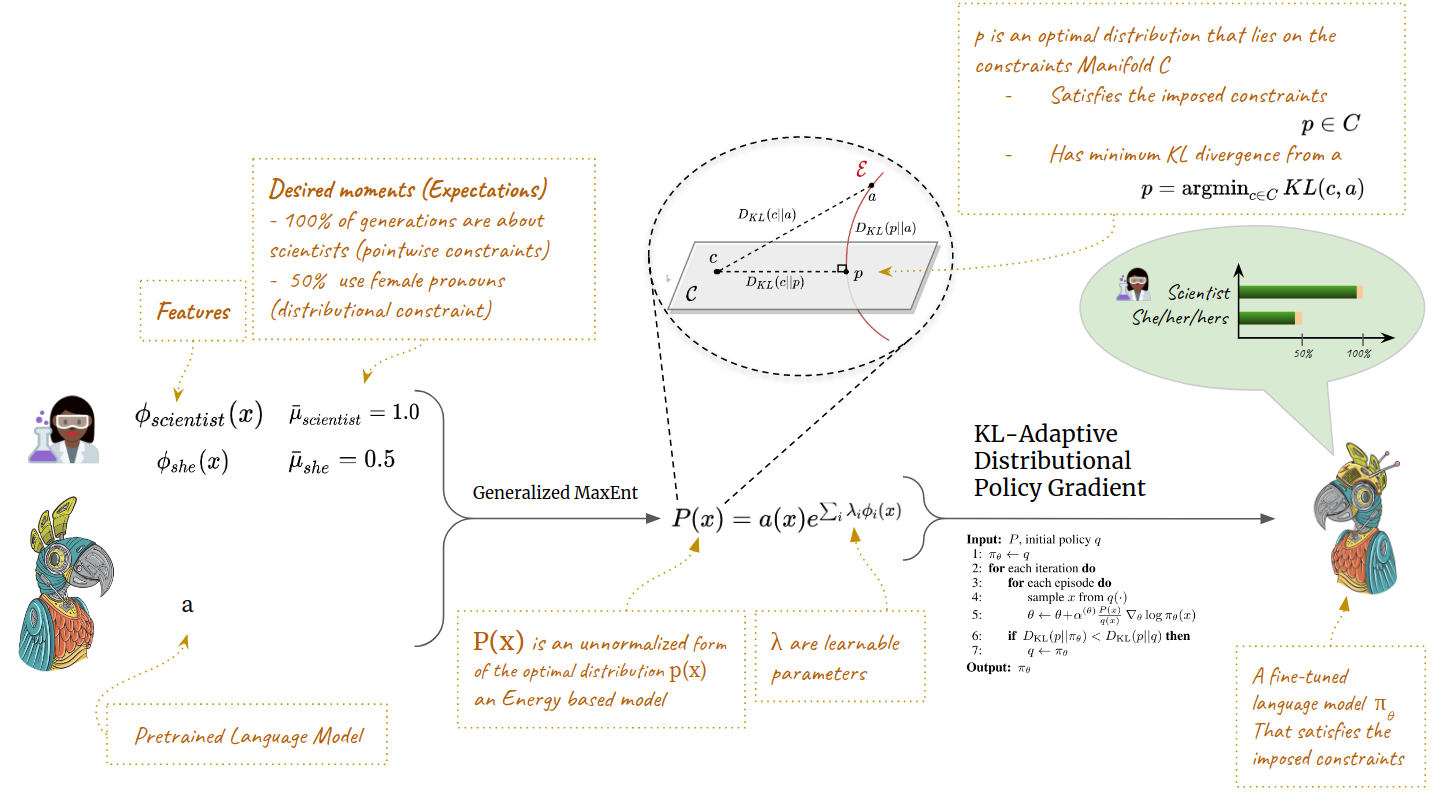
This is the repository code for the ICLR 2021 paper "A Distributional Approach to Controlled Text Generation". The code in this repo should help reproduce all the experiments and results in the paper.
Installation
pip install -r requirements.txt
Code Guide and Examples
- package
gdc/: contains all trainer classes. - folder
examples/: Implements the training loop for pointwise (run.py) and distributional & hybrid (run-distributional.py) experiments. - folder
configs/: Contains template configurations for all types of experiments.
Configuration Files
We use json configuration files to pass all training parameters including the contraints type and specifications. Here are the most important config parameters (the rest are self-explanatory):
trainer_class: Depending on which type of costraint you want, use GDCTrainer for distributional and PointwiseGDCTrainer for pointwise constraints. Other trainers exist for baselines (see examples below).lm_name: name of the language model you want to start with as on transformers hub.ref_lm_namename of the reference policy language model (proposal used for importance sampling) as on transformers hub.tk_name: tokenizer name.scorers: this is the most important parameter which is used to define your constraints. You can view each constraint as a scorer function that takes a collection of samples and returns an equivalent number of values representing the degree of constraint satisfaction in each sample.Scoreris passed a list of json objects, each of which contains the
following:name: name of the constraint.config: another json object with the following keys:scorer_type: The type of constraints. Possible types includesingle_word,wordlist,wikibio-wordlist,model, andgender.scorer_attribute: Depending on the scorer type, this defines what exactly do you want to control for that given type. (See below for a tutorial on building your own scorer).
desired_moments: this is specially for distributional constraints and it defines the required moments (feature means) that you want to achieve. Note that for pointwise constraints you must set your desired moment to 1.0.moment_matching_sample_size: this defines the number of samples used for moment matching (or lambda learning). See section 2.2 in the paper.eval_top_p: During training, we evaluate the model by sampling from it. This defines the nucleus sampling top_p value used for evaluation.q_update_interval: Number of update steps after which we check ifpiis better thanq, and updateq.q_update_criterion: Criterion used to decide whetherpiis improving or not. Options are KL-Divergence (used in the paper), or Total Variation Distance.eval_interval: Number of updates after which to evaluate the model i.e sample with nucleus sampling and compute different quality metrics on the generations.
Pointwise Constraints
In the case of solely pointwise constraints, the EBM could be constructed directly as
P(x) = a(x) . b(x) , where b(x) is a binary value indicating if the pointwise constraint is met or not for a specific sequence x. Therefore, calculations of the λ in the EBM is not necessary, we provide an optimized implementation for this using the PointwiseGDCTrainer.
- Single words
# Fine tune GPT-2 on a single word constraint inside the
# "trainer_class": "PointwiseGDCTrainer",
# Single word = "amazing" pointwise constraint
# inside word.json
# "trainer_class":"PointwiseGDCTrainer",
# "scorer_type": "single_word",
# "scorer_attribute": "amazing", (try it! replace "amazing" with any word)
python run.py --config ../configs/gdc/pointwise/word.json
- Word lists
# Fine tune GPT-2 using on a word-list pointwise constraint
# inside wordlist.json:
# "trainer_class":"PointwiseGDCTrainer",
# "scorer_type": "wordlist",
# "scorer_attribute": "politics", (try it! replace with any filename in ./gdc/resources/wordlists/
python run.py --config ../configs/gdc/pointwise/wordlist.json
- Discriminators
# "trainer_class":"PointwiseGDCTrainer",
# Use a pretrained sentiment classifier (class id = 0 or 2) as a pointwise constraint
# "scorer_type": "model",
# "scorer_attribute": "sentiment",
# "class_index": [0,2], # class idx: 0 positive, 1 negative, 2 very positive, 3 very negative
python run.py --config ../configs/gdc/pointwise/discriminator.json
Distributional and Hybrid Constraints
- Single Distributional Constraint
# inside the config file single-distributional.json
# this is how to define scorers and assign them the desired moments
# "scorers":[
# {"name": "female", "config":{"scorer_type": "gender", "scorer_attribute": "female"}}
# ],
# "desired_moments": {"female":0.50},
# "trainer_class":"GDCTrainer",
python run-distributional.py --config ../configs/distributional/single-distributional.json
- Multiple Distributional Constraints
# inside multiple-distributional.json config file
# add four wordlist constraints with different desired moments
# "scorers":[
# {"name": "science", "config":{"scorer_type": "wikibio-wordlist", "scorer_attribute":"science"}},
# {"name": "art", "config":{"scorer_type": "wikibio-wordlist", "scorer_attribute": "art"}},
# {"name": "sports", "config":{"scorer_type": "wikibio-wordlist", "scorer_attribute": "sports"},
# {"name": "business", "config":{"scorer_type": "wikibio-wordlist", "scorer_attribute": "business"}}
# ],
# "desired_moments": {"science":0.4, "art":0.4, "business":0.10, "sports":0.10},
# "trainer_class":"GDCTrainer",
python run-distributional.py --config ../configs/distributional/multiple-distributional.json
- Hybrid constraints (pointwise + distributional)
# inside hybrid.json config file here is how to combine pointwise and distributional constraints
# when the desired moment 1.0 it becomes a pointwise constraint while 0.5 is distributional
# "scorers":[
# {"name": "female", "config":{ "scorer_type": "gender", "scorer_attribute": "female"}},
# {"name": "sports", "config": {"scorer_type":"wikibio-wordlist", "scorer_attribute": "sports"}}
# ],
# "desired_moments": {"female":0.5, "sports": 1.0},
# "trainer_class":"GDCTrainer",
python run-distributional.py --config ../configs/distributional/hybrid.json
Baselines
We implement three reinforcement learning baselines. Note that RL baselines are only suitable with Pointwise constraints, here are some examples how to run them for some pointwise tasks:
- REINFORCE (Williams, 1992b) using the reward φ(x) as a reward signal.
# Fine tune GPT-2 using on a word list constraint
# inside REINFORCE.json those options are set to make allow this to happen
# "trainer_class": "PGTrainer" (PG -> Policy gradient)
# "scorer_type": "wordlist",
# "scorer_attribute": "politics",
python run.py --config ../configs/reinforce/REINIFORCE.json
- REINFORCE_P(x) Reinforce again with the EBM P as a reward signal.
# Fine tune GPT-2 on a single word constraint
# inside REINFORCE_Px.json those options are set to make allow this to happen
# these two options below are activating REINFORCE_P(x) trainer baseline
# "trainer_class": "PGTrainer",
# "use_P_as_reward": true, (this option works with PGTrainer to the EBM P)
# Single word = "amazing" pointwise constraint (try it! replace "amazing" with any word)
# "scorer_type": "single_word",
# "scorer_attribute": "amazing",
python run.py --config ../configs/reinforce/REINIFORCE_Px.json
- ZIEGLER (Ziegler et al., 2019): Proximal Policy Optimization (PPO) algorithm with φ(x) as a reward signal in addition to a KL penalty penalizing divergences from the original LM.
# Fine tune GPT-2 on a single word constraint
# inside PPO.json
# "trainer_class": "PPOTrainer",
# use a pretrained sentiment classifier (class id = 0 or 2) as a pointwise constraint
# "scorer_type": "model",
# "scorer_attribute": "sentiment",
# "class_index": [0,2], # class idx: 0 positive, 1 negative, 2 very postive, 3 very negative
python run.py --config ../configs/ppo/PPO.json
How Do I Define My Own Constraint?
Let's say you have a another kind of constraint different from the ones existing. Let's say you're not very passionate about the letter "z", so you want only 20% of the generated text to contain the letter "z". Clearly, this is a distributional constraint.
Step 1: Build you Scorer Function.
The first step is to go to gdc/scorer.py and in get_scoring_fn(), you add another if branch (obviously with more scorers, this should be done in a more elegant way):
elif self.config['scorer_type'] == 'single_letter`:
def scoring_fn(samples):
# code that checks for the existence of a certain generic letter.
# the letter should be passed in self.config['scorer_attribute']
# return [1 if a sample containts the letter, otherwise 0 for all samples]
You can also add any operations that your custom scorer needs in the __init__() function.
Step 2: Set up your Configs
As you only have a single distributional constraint. you can clone gdc/configs/distributional/single-distributional.json and edit the following to add your "z" letter constraint.
"scorers":[
{"name": "z_20", "config":{"scorer_type": "single_letter", "scorer_attribute":"z"}}
]
"desired_moments": {"z_20":0.20},
....
then just pass the new config json to run-distributional.py as shown above, and you are good to go!









