TurboTransformers
make transformers serving fast by adding a turbo to your inference engine!
Transformer is the most critical alogrithm innovation in the NLP field in recent years. It brings higher model accuracy while introduces more calculations. The efficient deployment of online Transformer-based services faces enormous challenges. In order to make the costly Transformer online service more efficient, the WeChat AI open-sourced a Transformer inference acceleration tool called TurboTransformers, which has the following characteristics.
- Excellent CPU / GPU performance. For Intel multi-core CPU and NVIDIA GPU hardware platforms, TurboTransformers can fully utilize all levels of computing power of the hardware. It has achieved better performance over pytorch / tensorflow and current mainstream optimization engines (such as onnxruntime-mkldnn / onnxruntime-gpu, torch JIT, NVIDIA faster transformers) on a variety of CPU and GPU hardware. See the detailed benchmark results below.
- Tailored to the characteristics of NLP inference tasks. Unlike the CV task, the input dimensions of the NLP inference task always change. The traditional approach is zero padding or truncation to a fixed length, which introduces additional zero padding computational overhead. Besides, some frameworks such as onnxruntime, tensorRT, and torchlib need to preprocess the calculation graph according to the input size in advance, which is not suitable for NLP tasks with varying sizes. TurboTransformers can support variable-length input sequence processing without preprocessing.
- A simpler method of use. TurboTransformers supports python and C ++ interface for calling. It can be used as an acceleration plug-in for pytorch. In the Transformer task, the end-to-end acceleration effect obtained by adding a few lines of python code.
TurboTransformers has been applied to multiple online BERT service scenarios in Tencent. For example, It brings 1.88x acceleration to the WeChat FAQ service, 2.11x acceleration to the public cloud sentiment analysis service, and 13.6x acceleration to the QQ recommendation system.
The following table is a comparison of TurboTransformers and related work.
| Related Works | Performance | Need Preprocess | Variable Length | Usage |
|---|---|---|---|---|
| pytorch JIT (CPU) | Fast | Yes | No | Hard |
| tf-Faster Transformers (GPU) | Fast | Yes | No | Hard |
| ONNX-runtime(CPU/GPU) | Fast/Fast | Yes | No | Easy |
| tensorflow-1.x (CPU/GPU) | Slow/Medium | Yes | No | Easy |
| pytorch (CPU/GPU) | Medium/Medium | No | Yes | Easy |
| turbo-transformers (CPU/GPU) | Fastest/Fastest | No | Yes | Easy |
Installation on CPU
git clone https://github.com/Tencent/TurboTransformers --recursive
- build docker images and containers on your machine.
sh tools/build_docker_cpu.sh
# optional:
If you want to compare the performance of onnxrt-mkldnn during benchmark, you need to set BUILD_TYPE=dev to compile onnxruntime into the docker image, as follows
env BUILD_TYPE=dev sh tools/build_docker_cpu.sh
- Install turbo in docker
Method 1:I want to unitest
cd /workspace
sh tools/build_and_run_unittests.sh.sh $PWD -DWITH_GPU=OFF
Method 2:I do not want to unitest
cd /workspace
mkdir -p build && cd build
cmake .. -DWITH_GPU=OFF
pip install -r `find . -name *whl`
- Run benchmark (optional) in docker, compare with pytorch, torch-JIT, onnxruntime
cd benchmark
bash run_benchmark.sh
- Install conda packages in docker (optional)
sh tool/build_conda_package.sh
# The conda package will be in /workspace/dist/*.tar.bz2
# When using turbo_transformers in other environments outside this container : python -m pip install your_root_path / dist / *. Tar.bz2
Installation on GPU
git clone https://github.com/Tencent/TurboTransformers --recursive
- build docker images and containers on your machine.
# You can modify the environment variables in the script to specify the cuda version and operating system version
sh tools/build_docker_gpu.sh $PWD
docker run --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=your_container_name REPOSITORY:TAG
# for example: docker run --net=host --rm -it -v $PWD:/workspace -v /etc/passwd:/etc/passwd --name=jiarui_gpu_env ccr.ccs.tencentyun.com/mmspr/turbo_transformers:0.1.1-cuda9.0-ubuntu16.04-gpu-dev
- Install pip package in docker and single test
cd /workspace
sh tools/build_and_run_unittests.sh $PWD -DWITH_GPU=ON
- Run benchmark (optional) in docker container, compare with pytorch
cd benchmark
bash gpu_run_benchmark.sh
Usage
turbo_transformers provides C ++ / python API interfaces. we hope to do our best to adapt to a variety of online environments to reduce the difficulty of development for users.
The first step in using turbo is to load a pre-trained model. We provide a way to load pytorch and tensorflow pre-trained models in huggingface/transformers.
The specific conversion method is to use the corresponding script in ./tools to convert the pre-trained model into an npz format file, and turbo uses the C ++ or python interface to load the npz format model.
In particular, we consider that most of the pre-trained models are in pytorch format and used with python. We provide a shortcut for calling directly in python for the pytorch saved model.
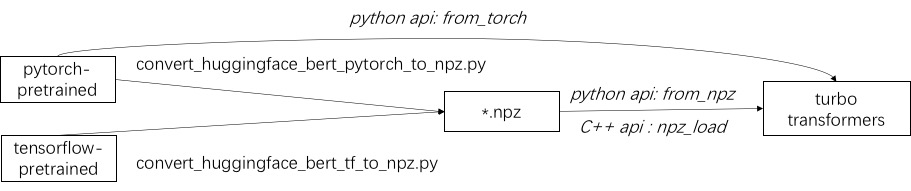
python APIs
Refer to examples in ./example/python.
Since the user of BERT acceleration always requires a customized post-processing process for the task, we provide an example of how to write a sequence classification application.
C++ APIs
Refer to ./example/cpp for an example.
Our example provides the GPU and two CPU multi-thread calling methods. One is to do one BERT inference using multiple threads; the other is to do multiple BERT inference, each of which using one thread.
Users can link turbo-transformers to your code through add_subdirectory.
Attention
The results of Turbo Transformers will be different from the results of PyTorch after 2 digits behind the decimal point, because the fused kernel cannot guarantee the same floating-point precision, especially for GeLU fuction.
Performance
CPU
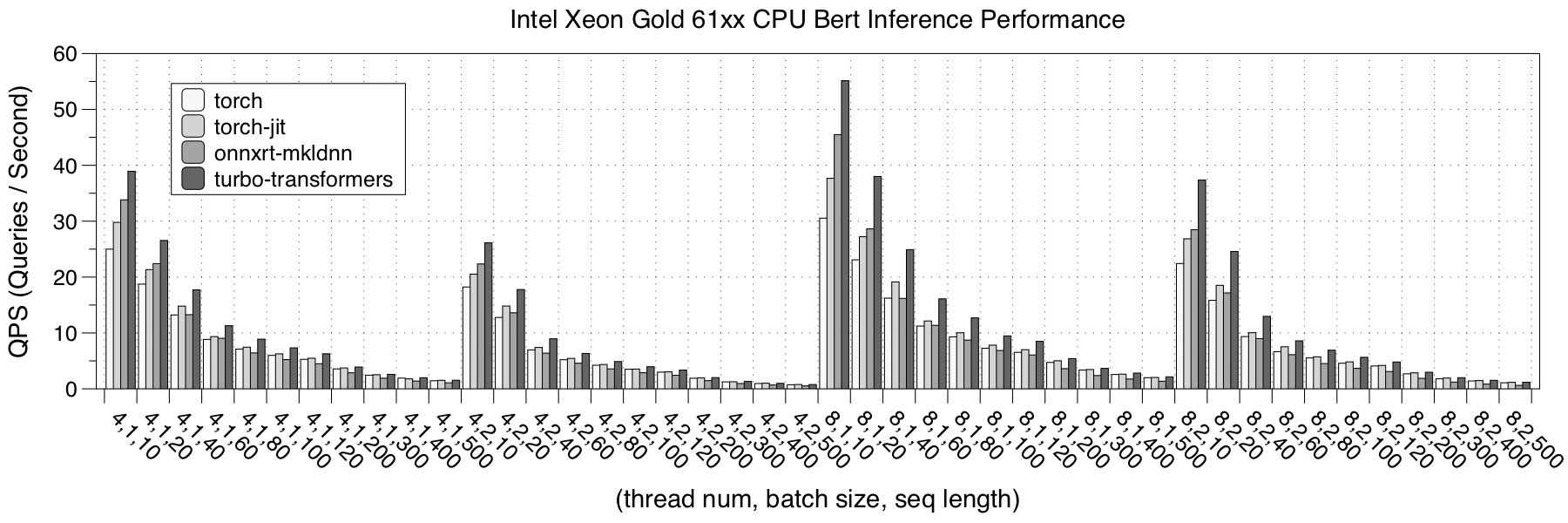
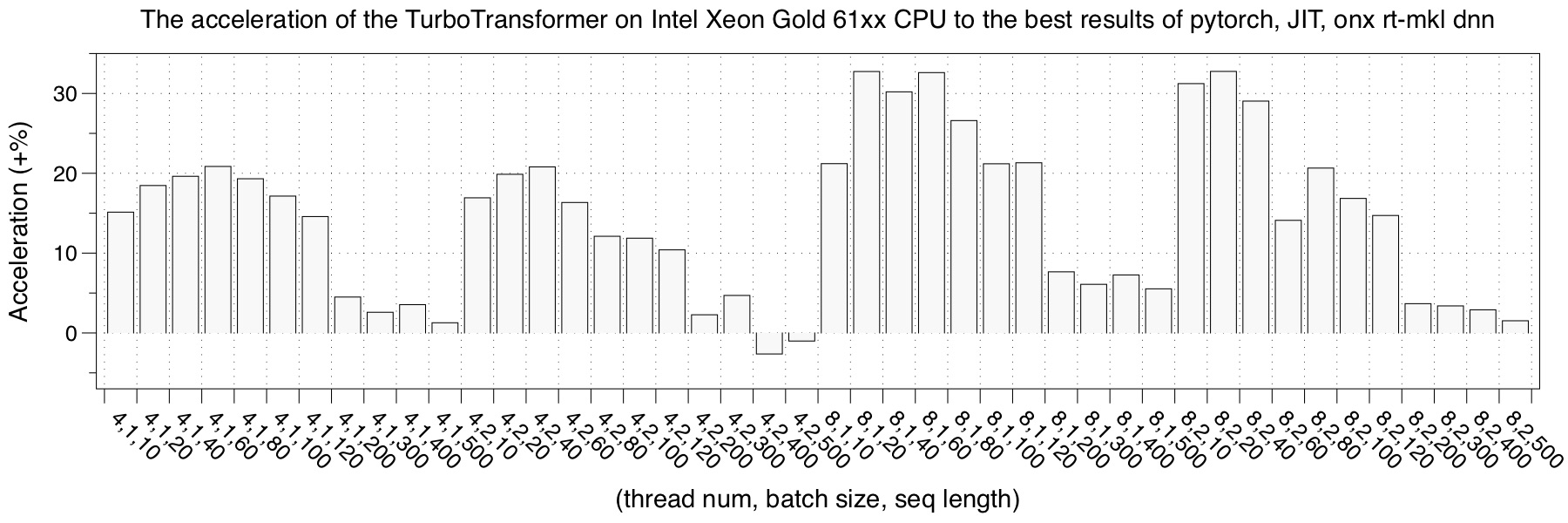
We tested the performance of TurboTransformers on three CPU hardware platforms.
We choose pytorch, pytorch-jit and onnxruntime-mkldnn and TensorRT implementation as a comparison. The performance test result is the average of 150 iterations. In order to avoid the phenomenon that the data of the last iteration is cached in the cache during multiple tests, each test uses random data and refreshes the cache data after calculation.
- Intel Xeon 61xx
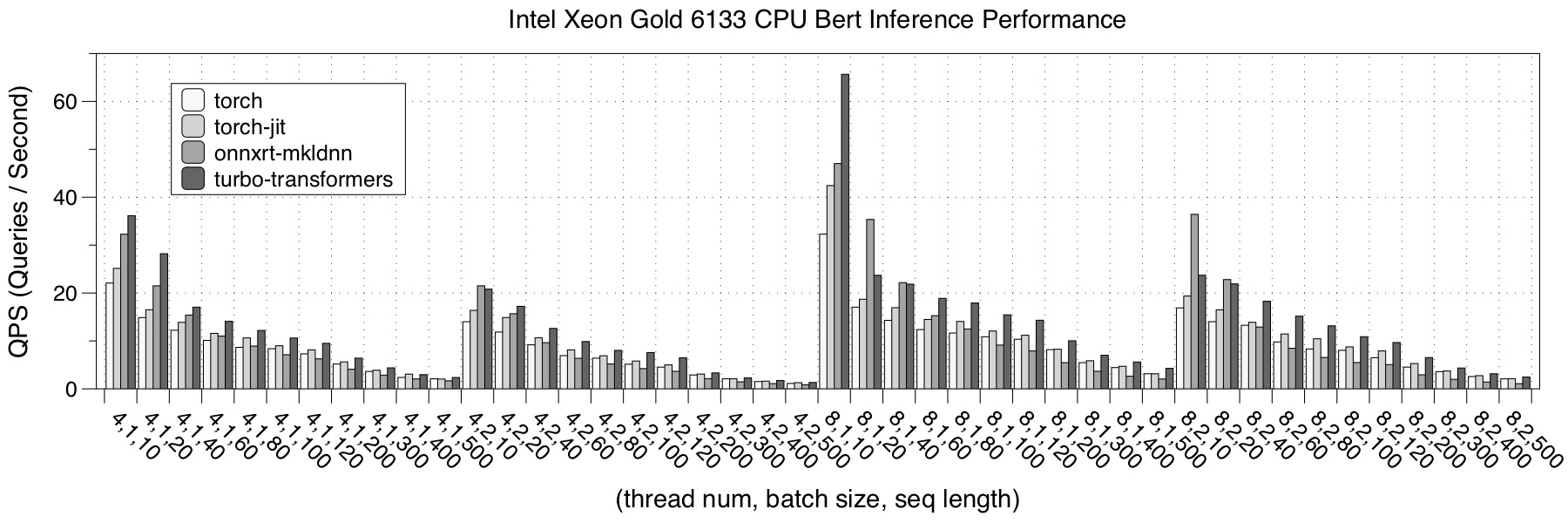
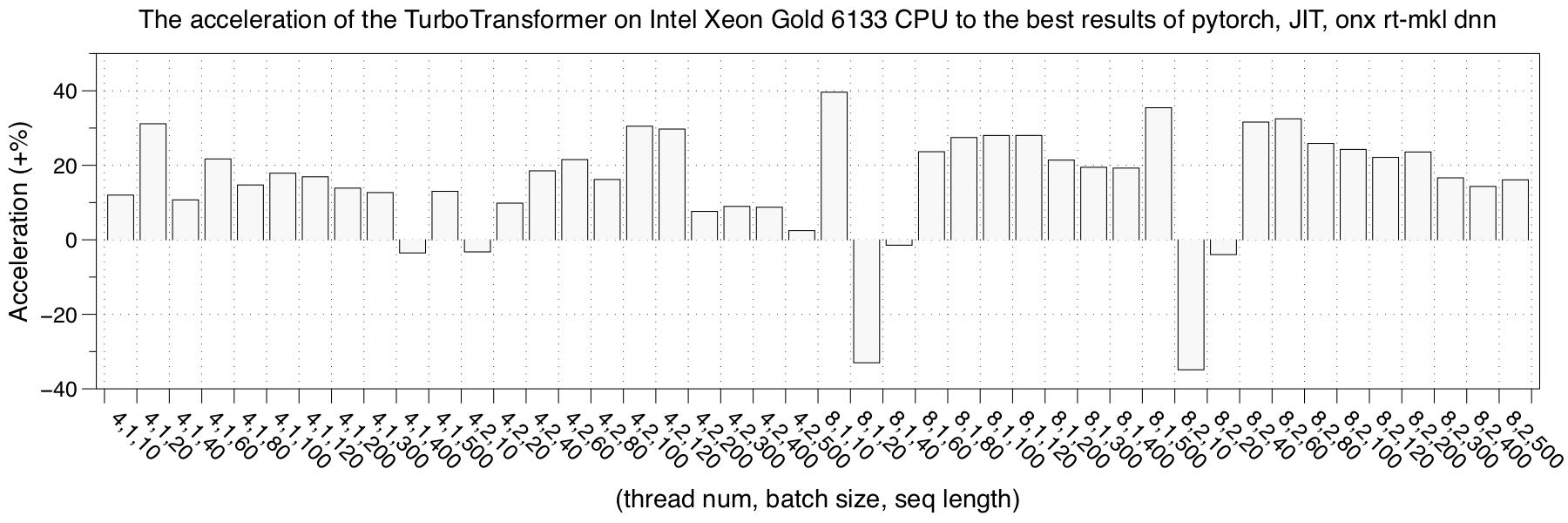
- Intel Xeon 6133
Compared to the 61xx model, Intel Xeon 6133 has a longer vectorized length of 512 bits, and it has a 30 MB shared L3 cache between cores.
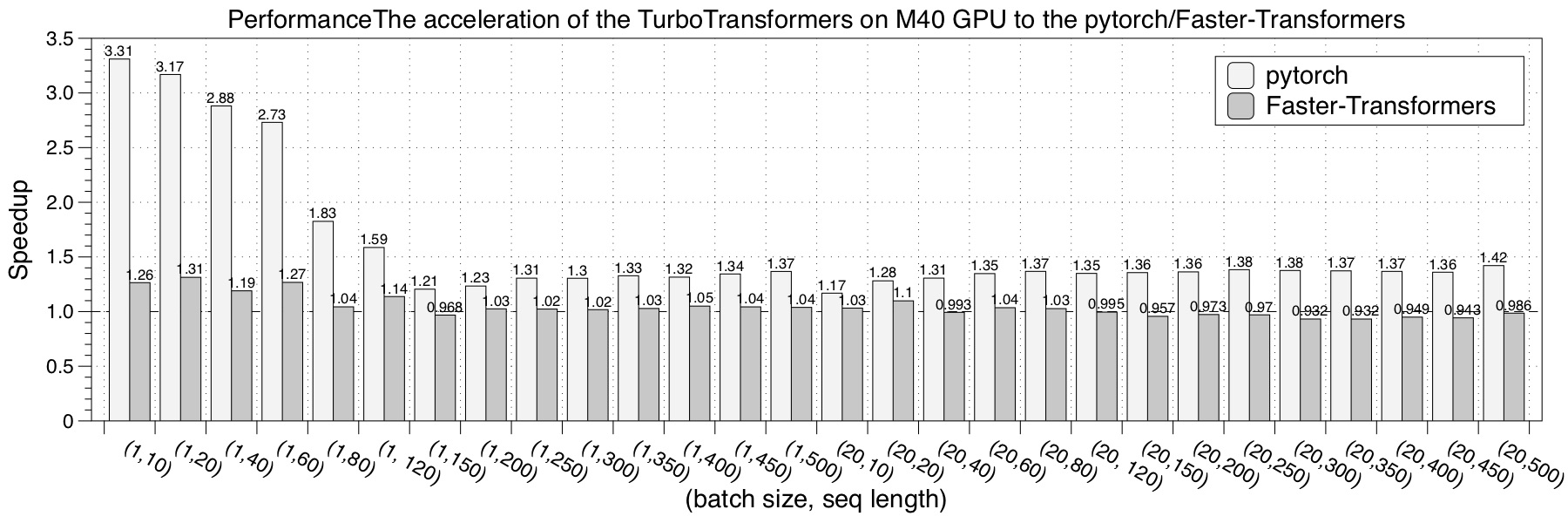
GPU
We tested the performance of turbo_transformers on four GPU hardware platforms.
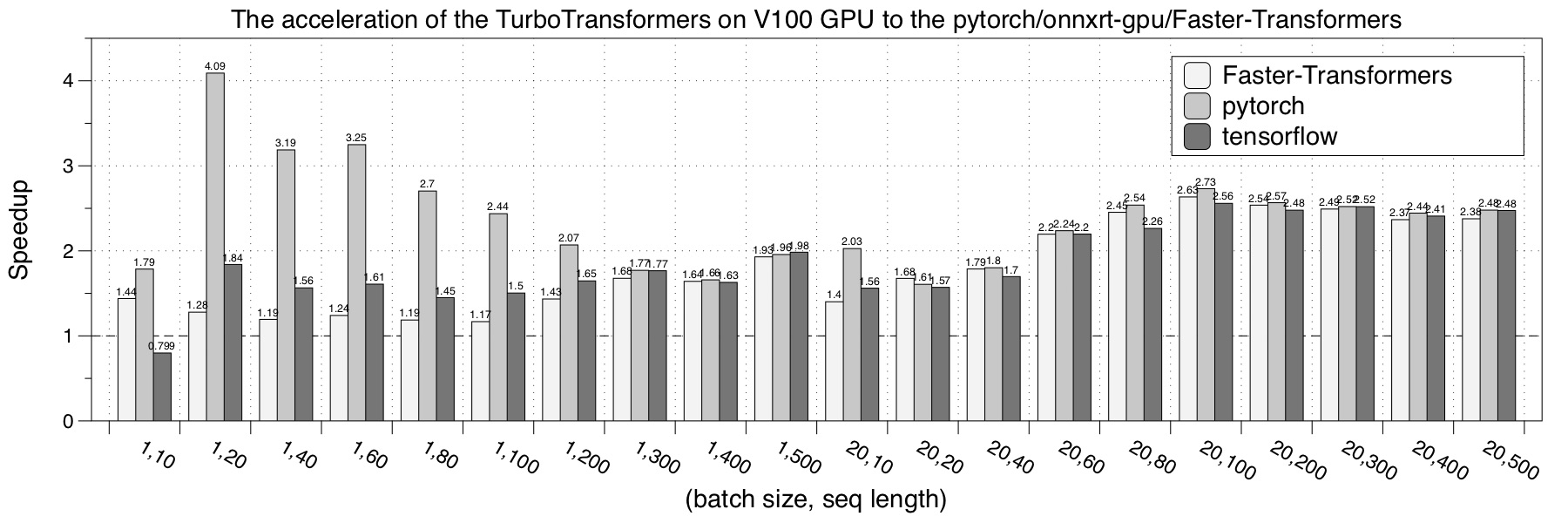
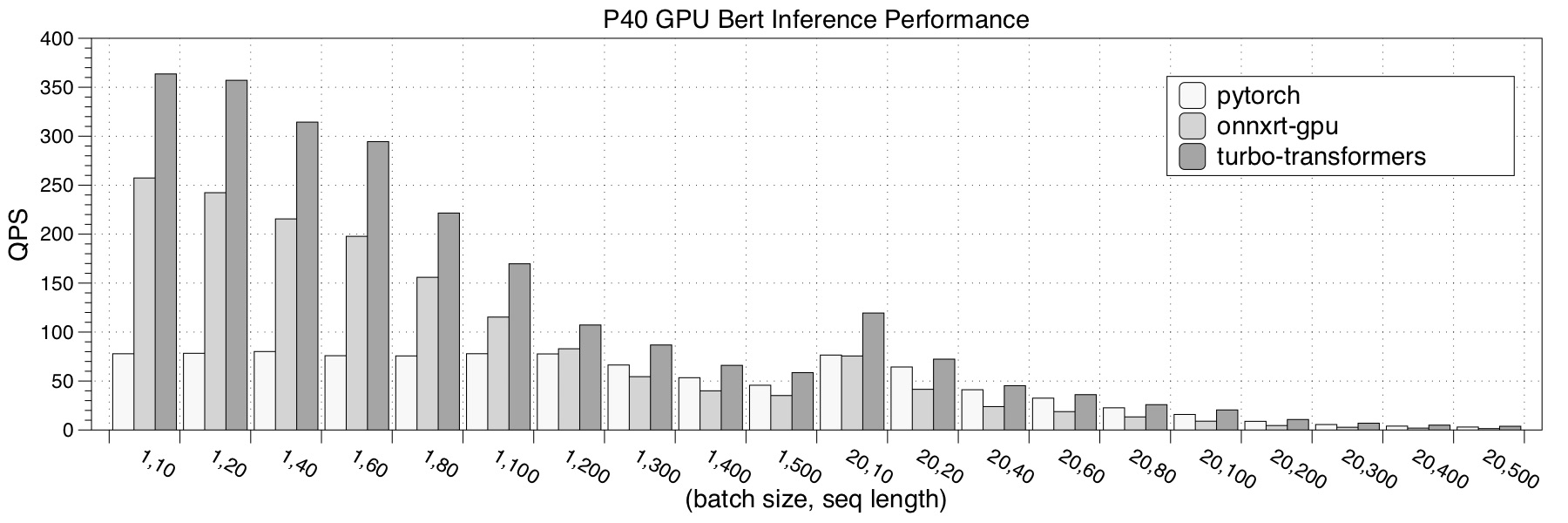
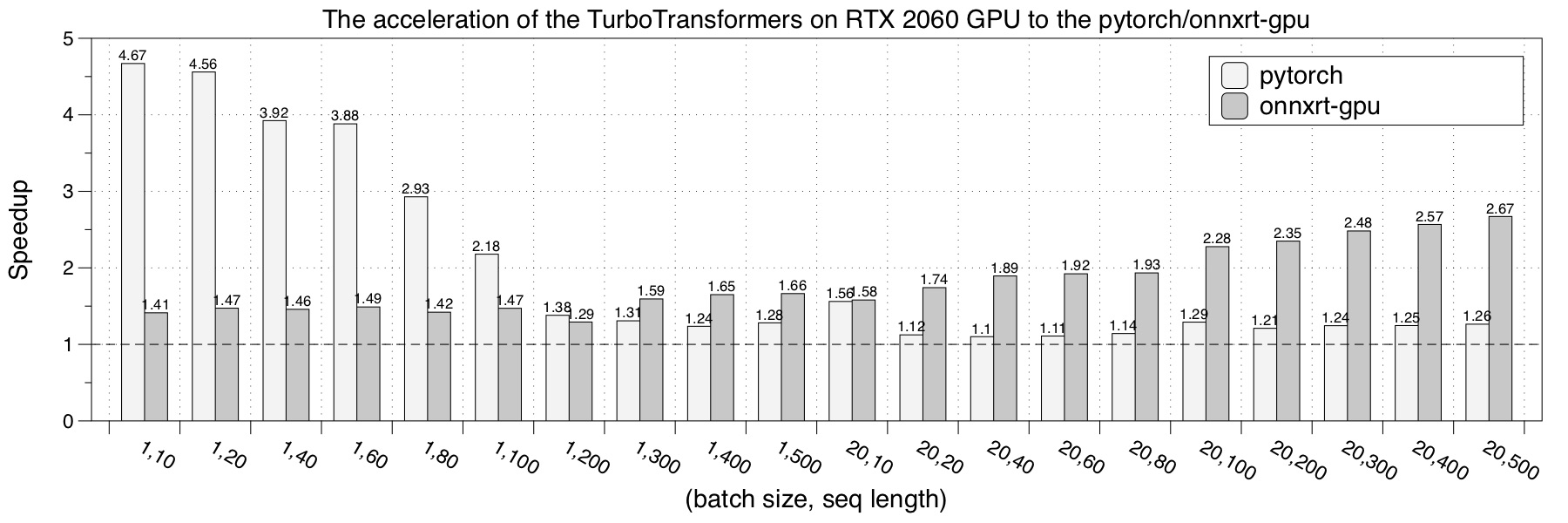
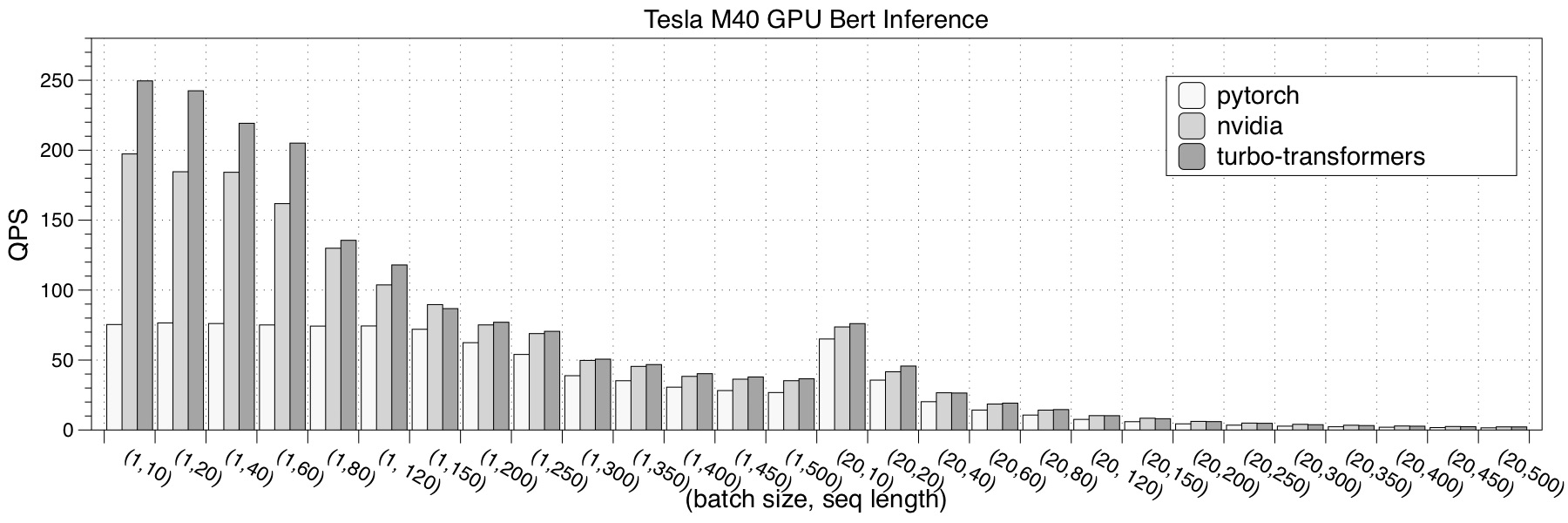
We choose pytorch, NVIDIA Faster Transformers, onnxruntime-gpu and TensorRT implementation as a comparison. The performance test result is the average of 150 iterations.
- RTX 2060
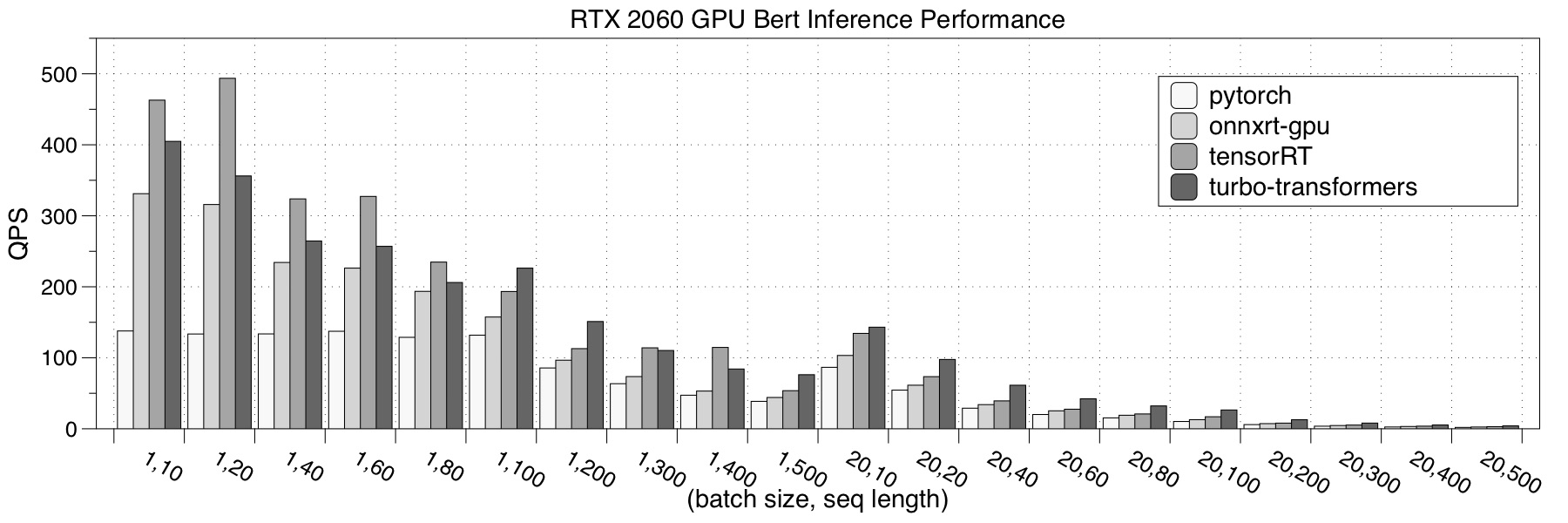
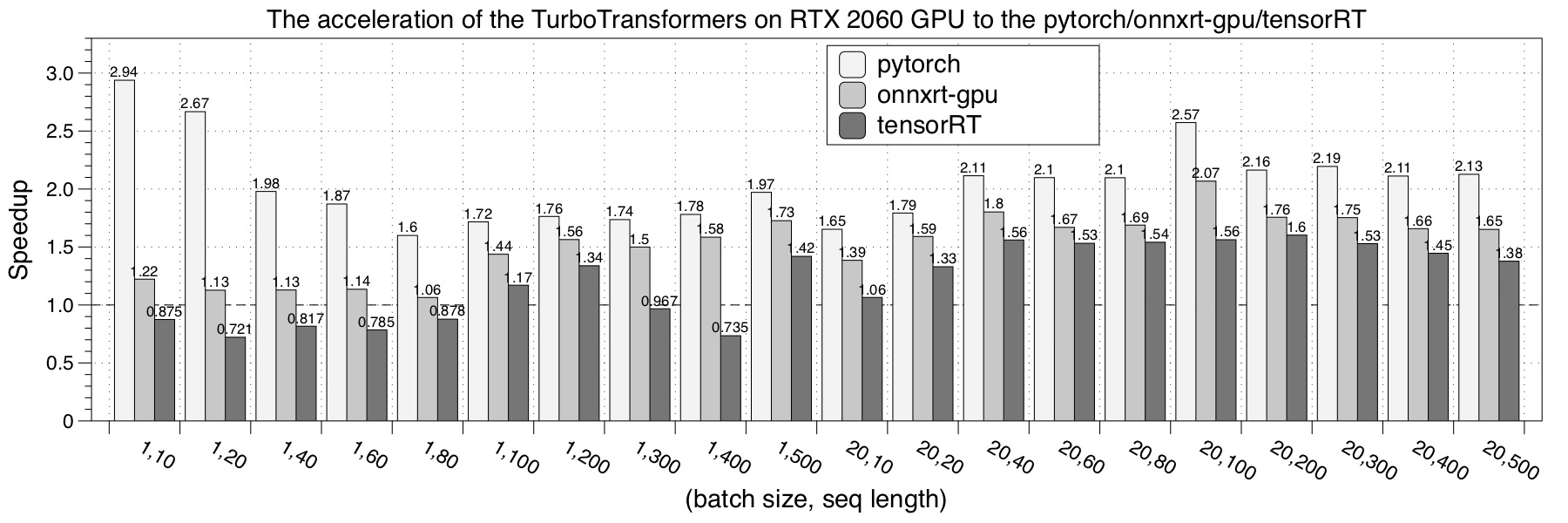
- Tesla V100
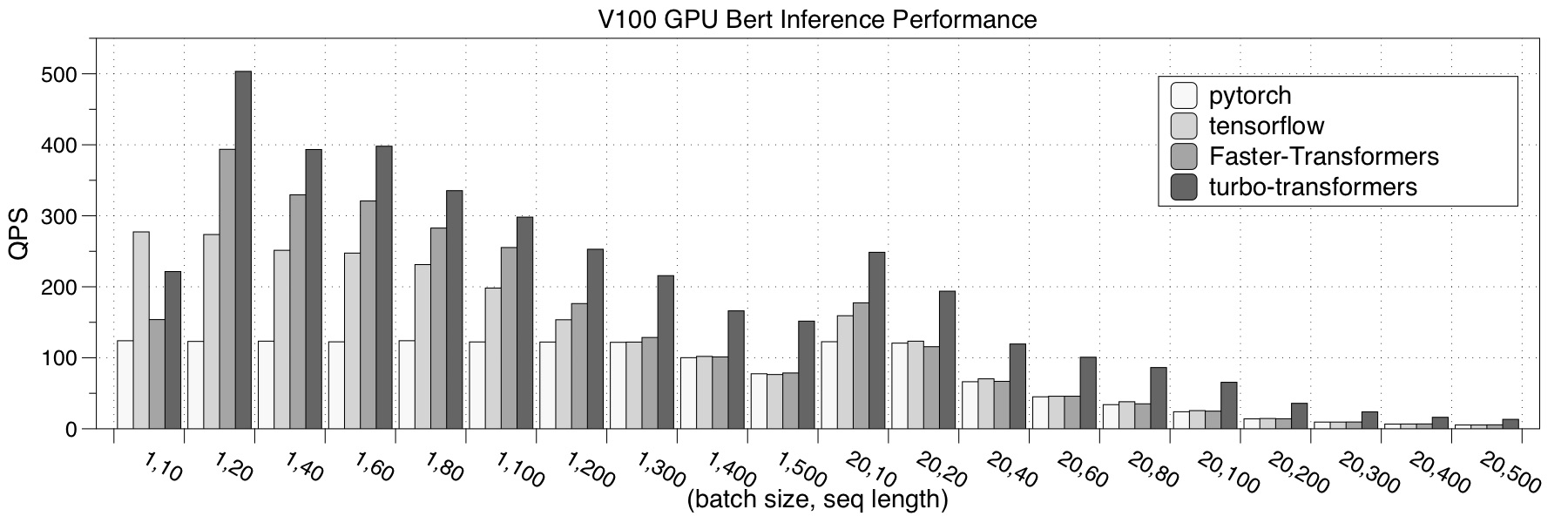
- Tesla P40
- Tesla M40
TODO
Currently (April 2020), we only support a interface of the BERT encoder model using FP32. In the near futuer, we will add support for other models (GPT2, decoders, etc.) and low-precision floating point (CPU int8, GPU FP16).




