Knodle
Knodle (Knowledge-supervised Deep Learning Framework) - a new framework for weak supervision with neural networks. It provides a modularization for separating weak data annotations, powerful deep learning models, and methods for improving weakly supervised training.
Installation
pip install knodle
Usage
knodle offers various methods for denoising weak supervision sources and improve them. There are several methods available for denoising. Examples can be seen in the tutorials folder.
There are four mandatory inputs for knodle:
model_input_x: Your model features (e.g. TF-IDF values) without any labels. Shape: (n_instances x features)mapping_rules_labels_t: This matrix maps all weak rules to a label. Shape: (n_rules x n_classes)rule_matches_z: This matrix shows all applied rules on your dataset. Shape: (n_instances x n_rules)model: A PyTorch model which can take your providedmodel_input_xas input. Examples are in the model folder.
If you know which denoising method you want to use, you can directly call the corresponding module (the list of currently supported methods is provided below).
Example for training the baseline classifier:
from knodle.model.logistic_regression_model import LogisticRegressionModel
from knodle.trainer.baseline.majority import MajorityVoteTrainer
NUM_OUTPUT_CLASSES = 2
model = LogisticRegressionModel(model_input_x.shape[1], NUM_OUTPUT_CLASSES)
trainer = MajorityVoteTrainer(
model=model,
mapping_rules_labels_t=mapping_rules_labels_t,
model_input_x=model_input_x,
rule_matches_z=rule_matches_z,
dev_model_input_x=X_dev,
dev_gold_labels_y=Y_dev
)
trainer.train()
trainer.test(X_test, Y_test)
A more detailed example of classifier training is here.
Main Principles
The framework provides a simple tensor-driven abstraction based on PyTorch allowing researchers to efficiently develop and compare their methods. The emergence of machine learning software frameworks is the biggest enabler for the wide spread adoption of machine learning and its speed of development. With Knodle we want to empower researchers in a similar fashion.
Knodle main goals:
- Data abstraction. The interface is a tensor-driven data abstraction which unifies a large number of input
variants and is applicable to a large number of tasks. - Method independence. We distinguish between weak supervision and prediction model. This enables comparability and accounts for a domain-specific inductive biases.
- Accessibility. There is a high-level access to the library, that makes it easy to test existing methods, incorporate new ones and benchmark them against each other.
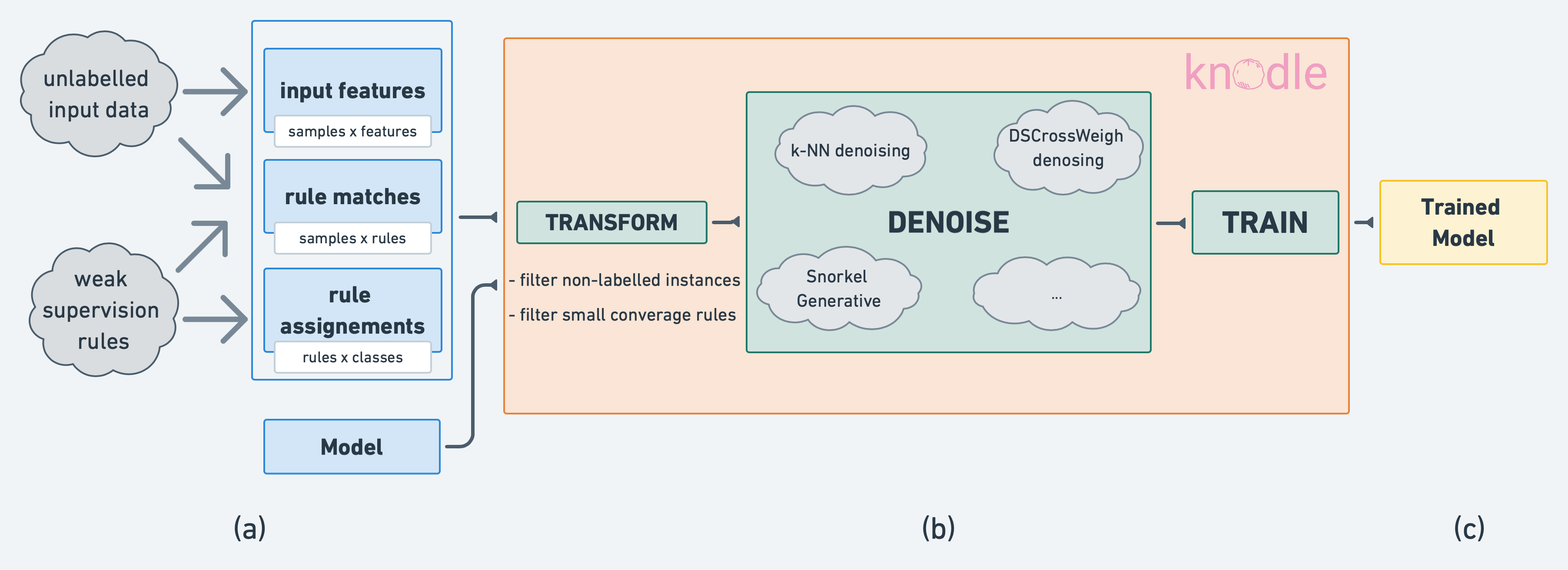
Apart from that, Knodle includes a selection of well-known data sets from prior work in weak supervision. Knodle ecosystem provides modular access to datasets and denoising methods (that can, in turn, be combined with arbitrary deep learning models), enabling easy experimentation.
Datasets currently provided in Knodle:
- Spam Dataset - a dataset, based on the YouTube comments dataset from Alberto et al. (2015). Here, the task is to classify whether a text is relevant to the video or holds spam, such as adver- tisement.
- Spouse Dataset - relation extraction dataset is based on the Signal Media One-Million News Articles Dataset from Corney et al. (2016).
- IMDb Dataset - a dataset, that consists of short movie reviews. The task is to determine whether a review holds a positive or negative sentiment.
- TAC-based Relation Extraction Dataset - a dataset built over Knowledge Base Population challenges in the Text Analysis Conference. For development and test purposes the corpus annotated via crowdsourcing and human labeling from KBP is used (Zhang et al. (2017). The training is done on a weakly-supervised noisy dataset based on TAC KBP corpora (Surdeanu (2013)).
All datasets are added to the Knodle framework in the tensor format described above and could be dowloaded here.
To see how the datasets were created please have a look at the dedicated tutorial.
Denoising Methods
There are several denoising methods available.
| Trainer Name | Module | Description |
|---|---|---|
| MajorityVoteTrainer | knodle.trainer.baseline |
This builds the baseline for all methods. No denoising takes place. The final label will be decided by using a simple majority vote approach and the provided model will be trained with these labels. |
| AutoTrainer | knodle.trainer |
This incorporates all denoising methods currently provided in Knodle. |
| KNNAggregationTrainer | knodle.trainer.knn_aggregation |
This method looks at the similarities in sentence values. The intuition behind it is that similar samples should be activated by the same rules which is allowed by a smoothness assumption on the target space. Similar sentences will receive the same label matches of the rules. This counteracts the problem of missing rules for certain labels. |
| WSCrossWeighTrainer | knodle.trainer.wscrossweigh |
This method weighs the training samples basing on how reliable their labels are. The less reliable sentences (i.e. sentences, whose weak labels are possibly wrong) are detected using a DS-CrossWeigh method, which is similar to k-fold cross-validation, and got reduced weights in further training. This counteracts the problem of wrongly classified sentences. |
| SnorkelTrainer | knodle.trainer.snorkel |
A wrapper of the Snorkel system, which incorporates both generative and discriminative Snorkel steps in a single call. |
Each of the methods has its own default config file, which will be used in training if no custom config is provided.
Details about negative samples
Tutorials
We also aimed at providing the users with basic tutorials that would explain how to use our framework. All of them are stored in examples folder and logically divided into two groups:
- tutorials that demonstrate how to prepare the input data for Knodle Framework...
- tutorials how to work with Knodle Framework...
- ... on the example of AutoTrainer. This trainer is to be called when user wants to train a weak classifier, but has no intention to use any specific denoising method, but rather try all currently provided in Knodle (link).
- ... on the example of WSCrossWeighTrainer. With this trainer a weak classifier with WSCrossWeigh denoising method will be trained (link).
Compatibility
Currently the package is tested on Python 3.7. It is possible to add further versions. The CI/CD pipeline needs to be updated in that case.
Structure
The structure of the code is as follows
knodle
├── knodle
│ ├── evaluation
│ ├── model
│ ├── trainer
│ ├── baseline
│ ├── knn_aggregation
│ ├── snorkel
│ ├── wscrossweigh
│ └── utils
│ ├── transformation
│ └── utils
├── tests
│ ├── data
│ ├── evaluation
│ ├── trainer
│ ├── baseline
│ ├── wscrossweigh
│ ├── snorkel
│ └── utils
│ └── transformation
└── examples
├── data_preprocessing
├── imdb_dataset
└── tac_based_dataset
└── training
├── simple_auto_trainer
└── wscrossweigh







