OAG-BERT
We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model which not only understands academic texts but also heterogeneous entity knowledge in OAG.
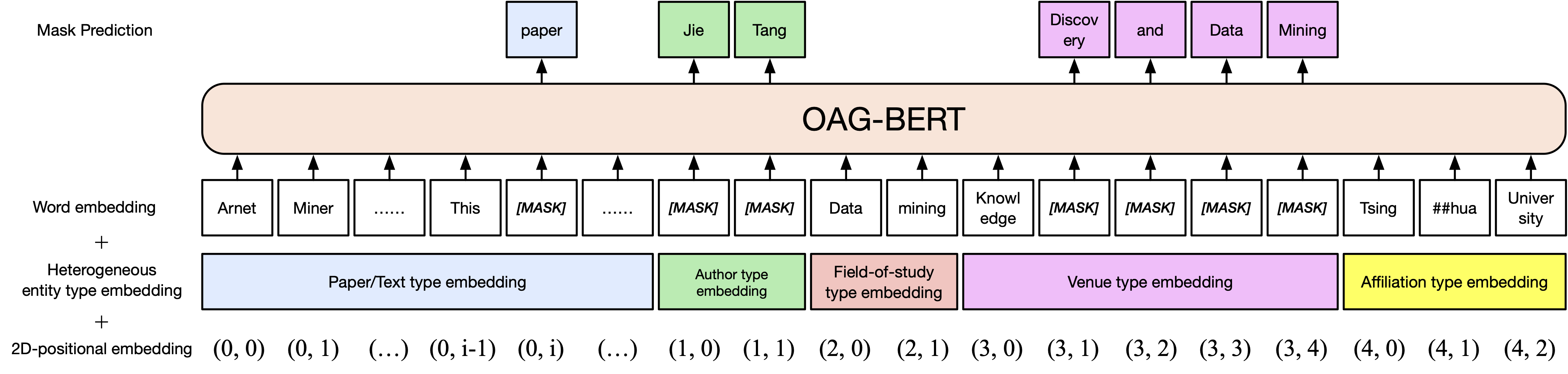
V1: The vanilla version
A basic version OAG-BERT. Similar to SciBERT, we pre-train the BERT model on academic text corpus in Open Academic Graph, including paper titles, abstracts and bodies.
The usage of OAG-BERT is the same of ordinary SciBERT or BERT. For example, you can use the following code to encode two text sequences and retrieve their outputs
from cogdl import oagbert
tokenizer, bert_model = oagbert()
sequence = ["CogDL is developed by KEG, Tsinghua.", "OAGBert is developed by KEG, Tsinghua."]
tokens = tokenizer(sequence, return_tensors="pt", padding=True)
outputs = bert_model(**tokens)
V2: The entity augmented version
An extension to the vanilla OAG-BERT. We incorporate rich entity information in Open Academic Graph such as authors and field-of-study. Thus, you can encode various type of entities in OAG-BERT v2. For example, to encode the paper of BERT, you can use the following code
from cogdl import oagbert
import torch
tokenizer, model = oagbert("oagbert-v2")
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = ['Jacob Devlin', 'Ming-Wei Chang', 'Kenton Lee', 'Kristina Toutanova']
venue = 'north american chapter of the association for computational linguistics'
affiliations = ['Google']
concepts = ['language model', 'natural language inference', 'question answering']
# build model inputs
input_ids, input_masks, token_type_ids, masked_lm_labels, position_ids, position_ids_second, masked_positions, num_spans = model.build_inputs(
title=title, abstract=abstract, venue=venue, authors=authors, concepts=concepts, affiliations=affiliations
)
# run forward
sequence_output, pooled_output = model.bert.forward(
input_ids=torch.LongTensor(input_ids).unsqueeze(0),
token_type_ids=torch.LongTensor(token_type_ids).unsqueeze(0),
attention_mask=torch.LongTensor(input_masks).unsqueeze(0),
output_all_encoded_layers=False,
checkpoint_activations=False,
position_ids=torch.LongTensor(position_ids).unsqueeze(0),
position_ids_second=torch.LongTensor(position_ids_second).unsqueeze(0)
)
You can also use some integrated functions to use OAG-BERT v2 directly, such as using decode_beamsearch to generate entities based on existing context. For example, to generate concepts with 2 tokens for the BERT paper, run the following code
model.eval()
candidates = model.decode_beamsearch(
title=title,
abstract=abstract,
venue=venue,
authors=authors,
affiliations=affiliations,
decode_span_type='FOS',
decode_span_length=2,
beam_width=8,
force_forward=False
)
OAG-BERT surpasses other academic language models on a wide range of entity-aware tasks while maintains its performance on ordinary NLP tasks.
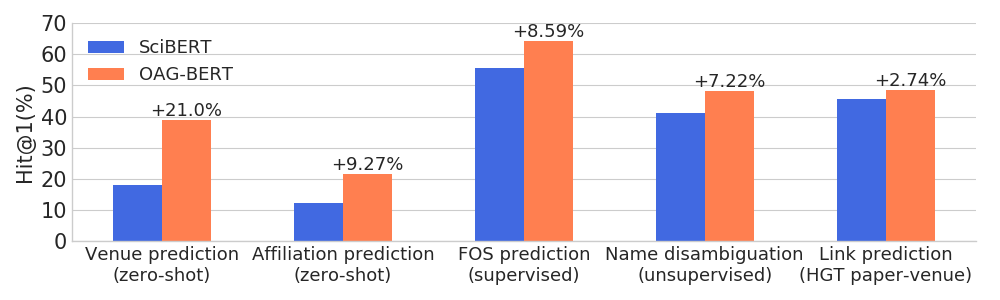
Beyond
We also release another two V2 version for users.
One is a generation based version which can be used for generating texts based on other information. For example, use the following code to automatically generate paper titles with abstracts.
from cogdl import oagbert
tokenizer, model = oagbert('oagbert-v2-lm')
model.eval()
for seq, prob in model.generate_title(abstract="To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations for NSFC (National Nature Science Foundation of China) and paper tagging in the AMiner system. It is also available to the public through the CogDL package."):
print('Title: %s' % seq)
print('Perplexity: %.4f' % prob)
# One of our generations: "pre-training oag-bert: an academic language model for enriching academic texts with domain knowledge"
In addition to that, we fine-tune the OAG-BERT for calculating paper similarity based on name disambiguation tasks, which is named as Sentence-OAGBERT following Sentence-BERT. The following codes demonstrate an example of using Sentence-OAGBERT to calculate paper similarity.
import os
from cogdl import oagbert
import torch
import torch.nn.functional as F
import numpy as np
# load time
tokenizer, model = oagbert("oagbert-v2-sim")
model.eval()
# Paper 1
title = 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding'
abstract = 'We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation...'
authors = ['Jacob Devlin', 'Ming-Wei Chang', 'Kenton Lee', 'Kristina Toutanova']
venue = 'north american chapter of the association for computational linguistics'
affiliations = ['Google']
concepts = ['language model', 'natural language inference', 'question answering']
# encode first paper
input_ids, input_masks, token_type_ids, masked_lm_labels, position_ids, position_ids_second, masked_positions, num_spans = model.build_inputs(
title=title, abstract=abstract, venue=venue, authors=authors, concepts=concepts, affiliations=affiliations
)
_, paper_embed_1 = model.bert.forward(
input_ids=torch.LongTensor(input_ids).unsqueeze(0),
token_type_ids=torch.LongTensor(token_type_ids).unsqueeze(0),
attention_mask=torch.LongTensor(input_masks).unsqueeze(0),
output_all_encoded_layers=False,
checkpoint_activations=False,
position_ids=torch.LongTensor(position_ids).unsqueeze(0),
position_ids_second=torch.LongTensor(position_ids_second).unsqueeze(0)
)
# Positive Paper 2
title = 'Attention Is All You Need'
abstract = 'We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely...'
authors = ['Ashish Vaswani', 'Noam Shazeer', 'Niki Parmar', 'Jakob Uszkoreit']
venue = 'neural information processing systems'
affiliations = ['Google']
concepts = ['machine translation', 'computation and language', 'language model']
input_ids, input_masks, token_type_ids, masked_lm_labels, position_ids, position_ids_second, masked_positions, num_spans = model.build_inputs(
title=title, abstract=abstract, venue=venue, authors=authors, concepts=concepts, affiliations=affiliations
)
# encode second paper
_, paper_embed_2 = model.bert.forward(
input_ids=torch.LongTensor(input_ids).unsqueeze(0),
token_type_ids=torch.LongTensor(token_type_ids).unsqueeze(0),
attention_mask=torch.LongTensor(input_masks).unsqueeze(0),
output_all_encoded_layers=False,
checkpoint_activations=False,
position_ids=torch.LongTensor(position_ids).unsqueeze(0),
position_ids_second=torch.LongTensor(position_ids_second).unsqueeze(0)
)
# Negative Paper 3
title = "Traceability and international comparison of ultraviolet irradiance"
abstract = "NIM took part in the CIPM Key Comparison of ″Spectral Irradiance 250 to 2500 nm″. In UV and NIR wavelength, the international comparison results showed that the consistency between Chinese value and the international reference one"
authors = ['Jing Yu', 'Bo Huang', 'Jia-Lin Yu', 'Yan-Dong Lin', 'Cai-Hong Dai']
veune = 'Jiliang Xuebao/Acta Metrologica Sinica'
affiliations = ['Department of Electronic Engineering']
concept= ['Optical Division']
input_ids, input_masks, token_type_ids, masked_lm_labels, position_ids, position_ids_second, masked_positions, num_spans = model.build_inputs(
title=title, abstract=abstract, venue=venue, authors=authors, concepts=concepts, affiliations=affiliations
)
# encode thrid paper
_, paper_embed_3 = model.bert.forward(
input_ids=torch.LongTensor(input_ids).unsqueeze(0),
token_type_ids=torch.LongTensor(token_type_ids).unsqueeze(0),
attention_mask=torch.LongTensor(input_masks).unsqueeze(0),
output_all_encoded_layers=False,
checkpoint_activations=False,
position_ids=torch.LongTensor(position_ids).unsqueeze(0),
position_ids_second=torch.LongTensor(position_ids_second).unsqueeze(0)
)
# calulate text similarity
# normalize
paper_embed_1 = F.normalize(paper_embed_1, p=2, dim=1)
paper_embed_2 = F.normalize(paper_embed_2, p=2, dim=1)
paper_embed_3 = F.normalize(paper_embed_3, p=2, dim=1)
# cosine sim.
sim12 = torch.mm(paper_embed_1, paper_embed_2.transpose(0, 1))
sim13 = torch.mm(paper_embed_1, paper_embed_3.transpose(0, 1))
print(sim12, sim13)
This fine-tuning was conducted on whoiswho name disambiguation tasks. The papers written by the same authors are treated as positive pairs and the rests as negative pairs. We sample 0.4M positive pairs and 1.6M negative pairs and use constrative learning to fine-tune the OAG-BERT (version 2). For 50% instances we only use paper title while the other 50% use all heterogeneous information. We evaluate the performance using Mean Reciprocal Rank where higher values indicate better results. The performance on test sets is shown as below.
| oagbert-v2 | oagbert-v2-sim | |
|---|---|---|
| Title | 0.349 | 0.725 |
| Title+Abstract+Author+Aff+Venue | 0.355 | 0.789 |
For more details, refer to examples/oagbert_metainfo.py in CogDL.
Chinese Version
We also trained the Chinese OAGBERT for use. The model was pre-trained on a corpus including 44M Chinese paper metadata including title, abstract, authors, affiliations, venues, keywords and funds. The new entity FUND is extended beyond entities used in the English version. Besides, the Chinese OAGBERT is trained with the SentencePiece tokenizer. These are the two major differences between the English OAGBERT and Chinese OAGBERT.
The examples of using the original Chinese OAGBERT and the Sentence-OAGBERT can be found in examples/oagbert/oagbert_metainfo_zh.py and examples/oagbert/oagbert_metainfo_zh_sim.py. Similarly to the English Sentence-OAGBERT, the Chinese Sentence-OAGBERT is fine-tuned on name disambiguation tasks for calculating paper embedding similarity. The performance is shown as below. We recommend users to directly use this version if downstream tasks do not have enough data for fine-tuning.
| oagbert-v2-zh | oagbert-v2-zh-sim | |
|---|---|---|
| Title | 0.337 | 0.619 |
| Title+Abstract | 0.314 | 0.682 |
Cite
If you find it to be useful, please cite us in your work:
@article{xiao2021oag,
title={OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Model},
author={Liu, Xiao and Yin, Da and Zhang, Xingjian and Su, Kai and Wu, Kan and Yang, Hongxia and Tang, Jie},
journal={arXiv preprint arXiv:2103.02410},
year={2021}
}
@inproceedings{zhang2019oag,
title={OAG: Toward Linking Large-scale Heterogeneous Entity Graphs.},
author={Zhang, Fanjin and Liu, Xiao and Tang, Jie and Dong, Yuxiao and Yao, Peiran and Zhang, Jie and Gu, Xiaotao and Wang, Yan and Shao, Bin and Li, Rui and Wang, Kuansan},
booktitle={Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19)},
year={2019}
}
@article{chen2020conna,
title={CONNA: Addressing Name Disambiguation on The Fly},
author={Chen, Bo and Zhang, Jing and Tang, Jie and Cai, Lingfan and Wang, Zhaoyu and Zhao, Shu and Chen, Hong and Li, Cuiping},
journal={IEEE Transactions on Knowledge and Data Engineering},
year={2020},
publisher={IEEE}
}






