TorchShard
TorchShard is a lightweight engine for slicing a PyTorch tensor into parallel shards. It can reduce GPU memory and scale up the training when the model has massive linear layers (e.g., ViT, BERT and GPT) or huge classes (millions). It has the same API design as PyTorch.
Installation
pip install torchshard
More options in INSTALL.md.
Usage
import torchshard as ts
ts.distributed.init_process_group(group_size=2) # init parallel groups
m = torch.nn.Sequential(
torch.nn.Linear(20, 30, bias=True),
ts.nn.ParallelLinear(30, 30, bias=True, dim=None), # equal to nn.Linear()
ts.nn.ParallelLinear(30, 30, bias=True, dim=0), # parallel in row dimension
ts.nn.ParallelLinear(30, 30, bias=True, dim=1), # parallel in column dimension
).cuda()
x = m(x) # forward
loss = ts.nn.functional.parallel_cross_entropy(x, y) # parallel loss function
loss.backward() # backward
torch.save(
ts.collect_state_dict(m, m.state_dict()), 'm.pt') # save model state
Performance
The following figure is a showcase of training ResNet-50 on 8 NVIDIA TITAN-XP (12196 MiB) GPUs with scaling up classes from 1000 → 1 Million. The input size is 224 x 224, and the batch size is 256. Parallelism is with 8-way data parallel and 8-way model parallel.
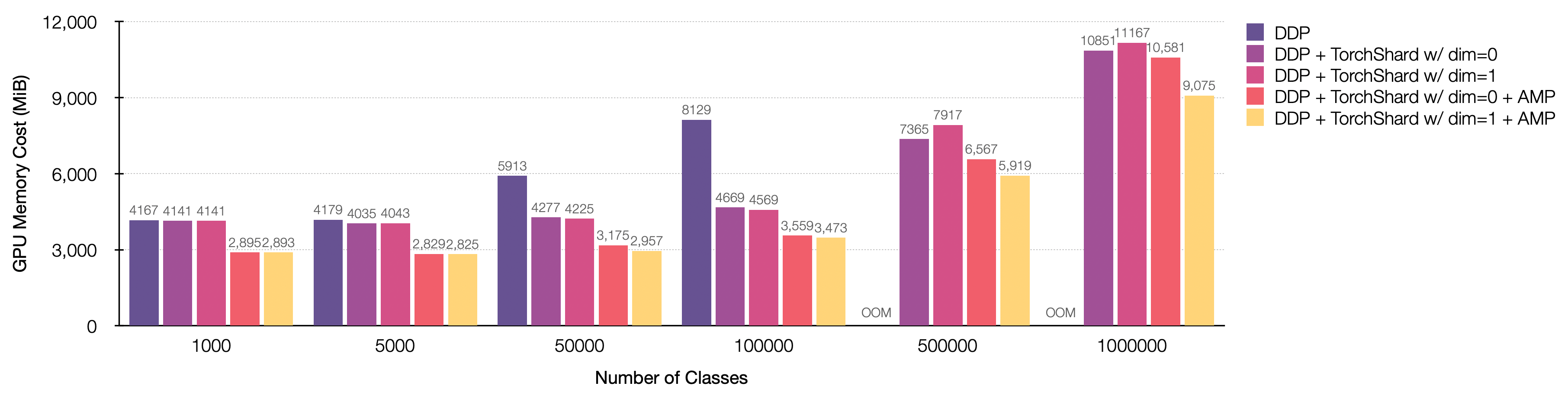
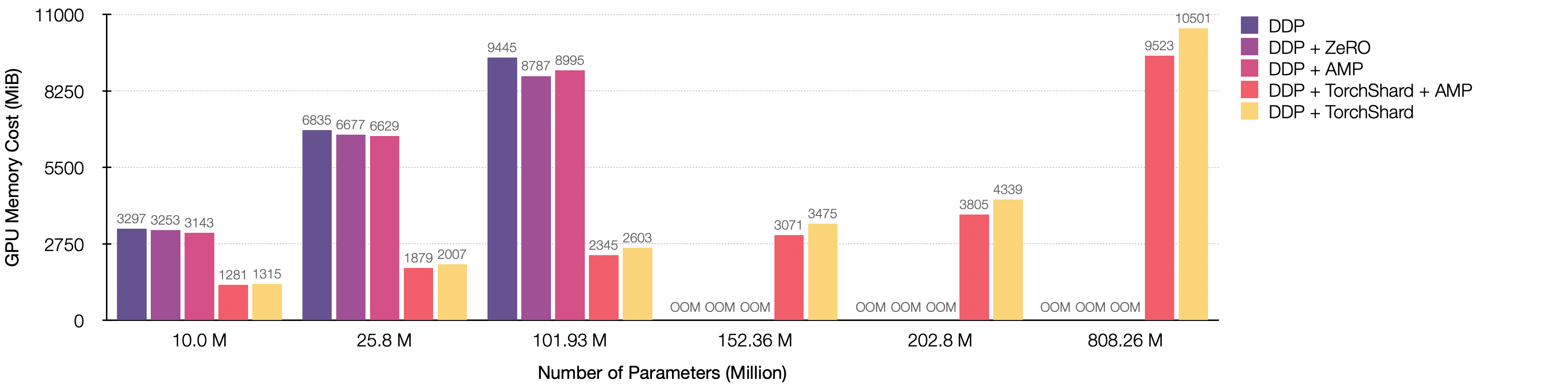
The following figure shows training minGPT on 8 NVIDIA TITAN-XP (12196 MiB) GPUs with scaling up parameters from 10 Million → 808 Million. The input size is 32 x 32, and the batch size is 16. Parallelism is with 1-way data parallel and 8-way model parallel.
Contributing
The TorchShard welcomes your expertise and enthusiasm!
If you are interested in torchshard, you are welcome to help
- polish code and develop new features
- develop high-quality tutorials, projects, and advanced materials
Direct pull requests are welcome. Contact: kaiyuyue [at] umd.edu.
Citing TorchShard
If you think TorchShard is helpful in your research and consider to cite it, please use the following BibTeX entry.
@misc{torchshard2021,
author = {Kaiyu Yue},
title = {TorchShard},
howpublished = {\url{https://github.com/KaiyuYue/torchshard}},
year = {2021}
}






