Orion
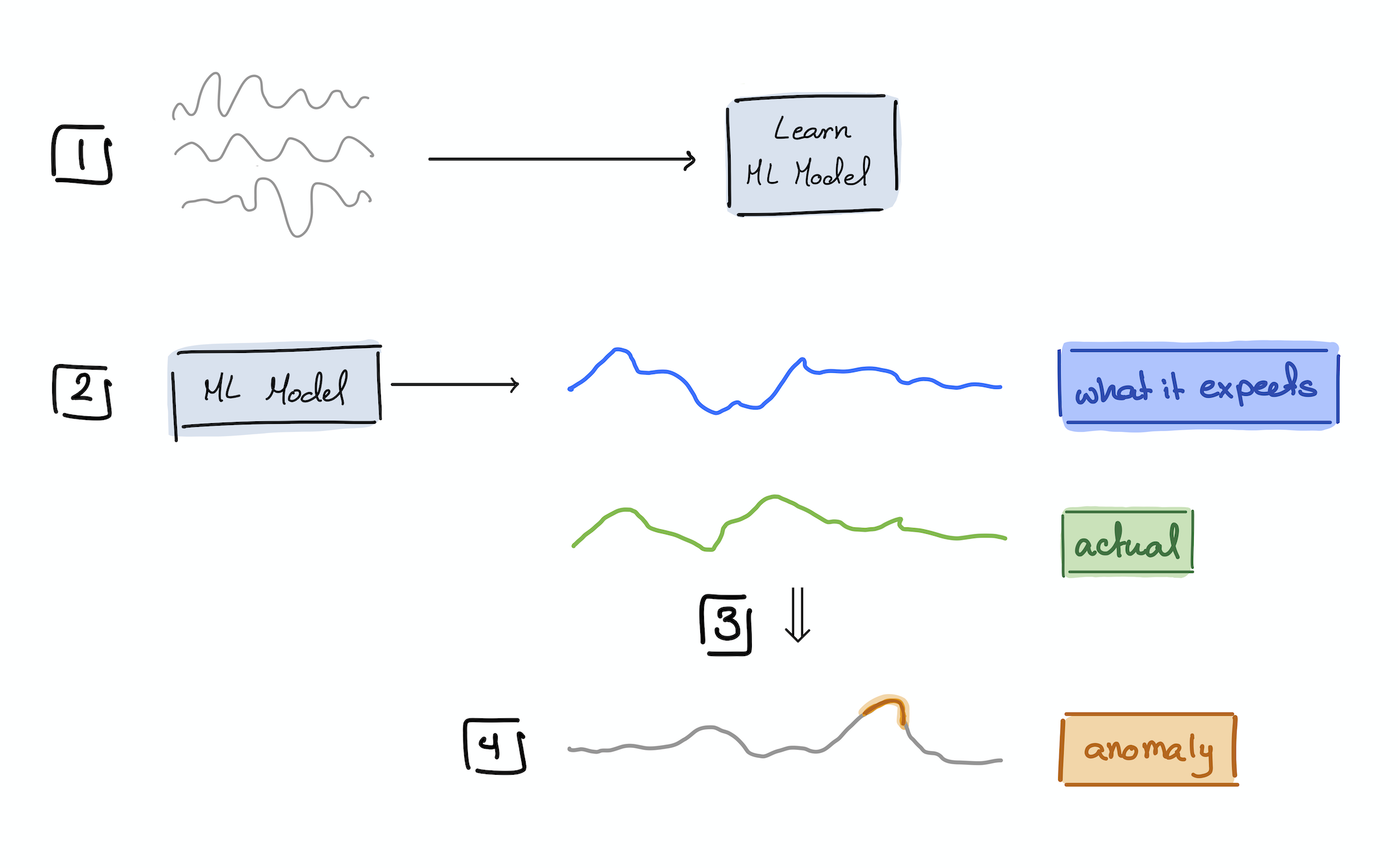
Orion is a machine learning library built for unsupervised time series anomaly detection. With a given time series data, we provide a number of “verified” ML pipelines (a.k.a Orion pipelines) that identify rare patterns and flag them for expert review.
The library makes use of a number of automated machine learning tools developed under Data to AI Lab at MIT.
Recent news: Read about using an Orion pipeline on NYC taxi dataset in a blog series:
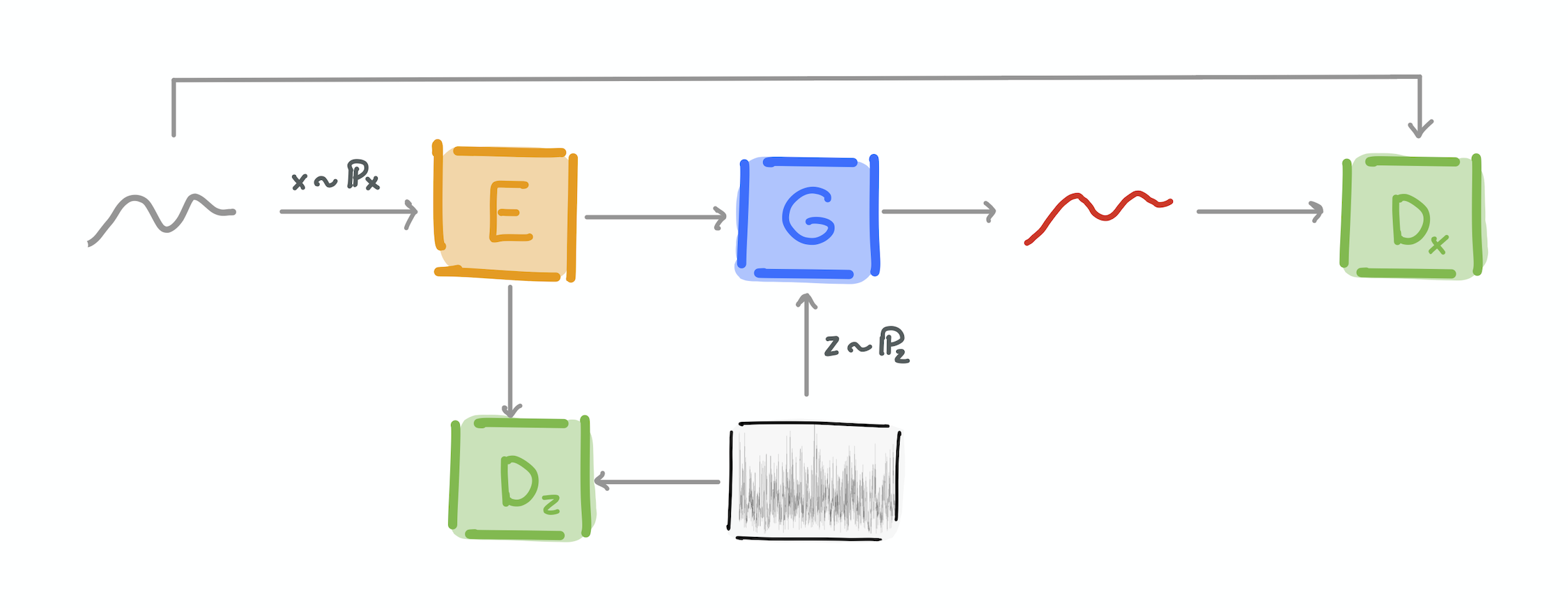
| Part 1: Learn about unsupervised time series anomaly detection | Part 2: Learn how we use GANs to solving the problem? | Part 3: How does one evaluate anomaly detection pipelines? |
|---|---|---|
 |
 |
 |
Notebooks: Discover Orion through colab by launching our notebooks!
Quickstart
Install with pip
The easiest and recommended way to install Orion is using pip:
pip install orion-ml
This will pull and install the latest stable release from PyPi.
In the following example we show how to use one of the Orion Pipelines.
Fit an Orion pipeline
We will load a demo data for this example:
from orion.data import load_signal
train_data = load_signal('S-1-train')
train_data.head()
which should show a signal with timestamp and value.
timestamp value
0 1222819200 -0.366359
1 1222840800 -0.394108
2 1222862400 0.403625
3 1222884000 -0.362759
4 1222905600 -0.370746
In this example we use lstm_dynamic_threshold pipeline and set some hyperparameters (in this case training epochs as 5).
from orion import Orion
hyperparameters = {
'keras.Sequential.LSTMTimeSeriesRegressor#1': {
'epochs': 5,
'verbose': True
}
}
orion = Orion(
pipeline='lstm_dynamic_threshold',
hyperparameters=hyperparameters
)
orion.fit(train_data)
Detect anomalies using the fitted pipeline
Once it is fitted, we are ready to use it to detect anomalies in our incoming time series:
new_data = load_signal('S-1-new')
anomalies = orion.detect(new_data)
:warning: Depending on your system and the exact versions that you might have installed some WARNINGS may be printed. These can be safely ignored as they do not interfere with the proper behavior of the pipeline.
The output of the previous command will be a pandas.DataFrame containing a table of detected anomalies:
start end score
0 1394323200 1399701600 0.673494



