varying-length-summ
We provide the source code for the paper "A New Approach to Overgenerating and Scoring Abstractive Summaries" accepted at NAACL'21. If you find the code useful, please cite the following paper.
@inproceedings{song-etal-2021-new,
title = "A New Approach to Overgenerating and Scoring Abstractive Summaries",
author = "Kaiqiang Song and Bingqing Wang and Zhe Feng and Fei Liu",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.naacl-main.110",
pages = "1392--1404"}
Demo
Source Text:
The Bank of Japan appealed to financial markets to remain calm Friday following the US decision to order Daiwa Bank Ltd. to close its US operations.
System Summaries of Varying Lengths ("BoJ" stands for "Bank of Japan"):
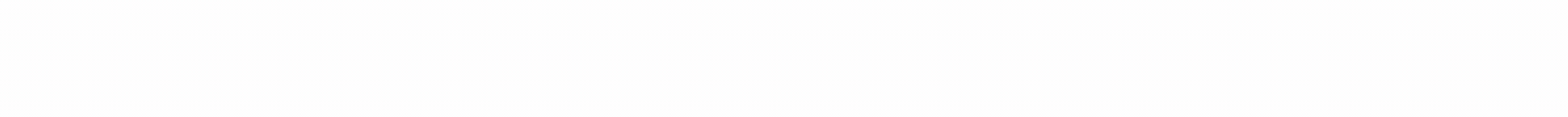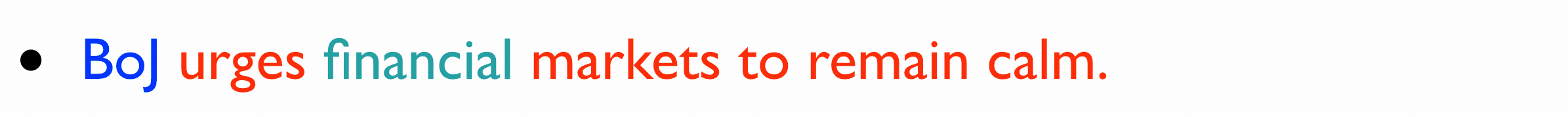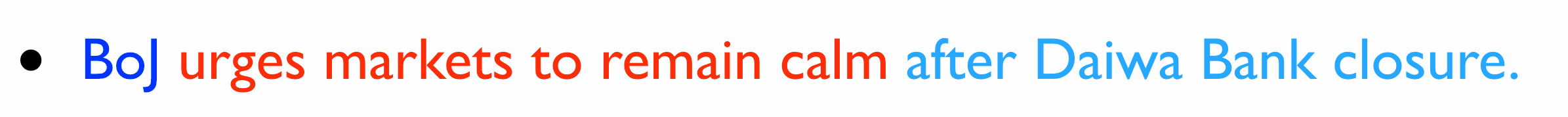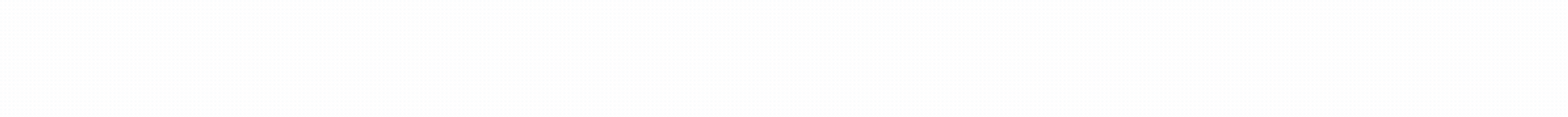
Presentation Video
Dependencies
The code is written in Python (v3.7) and Pytorch (v1.7+). We suggest the following enviorment:
- A Linux machine (Ubuntu) with GPU
- Python (v3.7+)
- Pytorch (v1.7+)
- Pyrouge
- transformers (v2.3.0)
HINT: Since huggingface transformers is alternating very fast, you may need to modify a lot of stuff if you want to use a new version. Contact me if you get any trouble on it.
To install pyrouge and transformers, run the command below:
pip install pyrouge transformers==2.3.0
For generating summaries with varying length
Step 1: clone this repo. Download trained Our Model, move it to the working folder and uncompress it.
git clone https://github.com/ucfnlp/varying-length-summ.git
mv model.zip varying-length-summ
cd varying-length-summ
unzip models.zip
Step 2: Generating summaries with varying length from a raw input file.
python run.py --do_test --parallel --input data/input.txt
It will generate summaries of varying lengths coupled with its order information.
For Selecting summaries with best quality binary classifer
Step 1: Follow the previous section about generating summaries with multiple length.
Step 2: Collect test set similar to data/gigaword_cls/test500* files:
-
a source input file
test500_input.txt -
a target output file
test500_output.txt -
a label file
test500_label.txtfor whether the target summary is admissible for the source input. (all 0 if you don't have thoese labels)
HINT: one instance per line
Step 3: modify the test500 settings in settings/dataset/gigaword_cls.
Step 4: Run the code below.
python run_classifier.py --do_test --parallel
It will generate a prediction of admissible probability in predict.txt.
For Selecting summaries with length reward reranking method
Step 1: Follow the previous section about generating summaries with multiple length.
Step 2: Run the code below.
python run_rerank.py
It will re-rank the summary with length rewards. The predicted length is in length.txt
For Data Downloading (500 inputs x 7 lengths)
Please refer to this link


