BERTweet
A pre-trained language model for English Tweets.
- BERTweet is the first public large-scale language model pre-trained for English Tweets. BERTweet is trained based on the RoBERTa pre-training procedure, using the same model configuration as BERT-base.
- The corpus used to pre-train BERTweet consists of 850M English Tweets (16B word tokens ~ 80GB), containing 845M Tweets streamed from 01/2012 to 08/2019 and 5M Tweets related the COVID-19 pandemic.
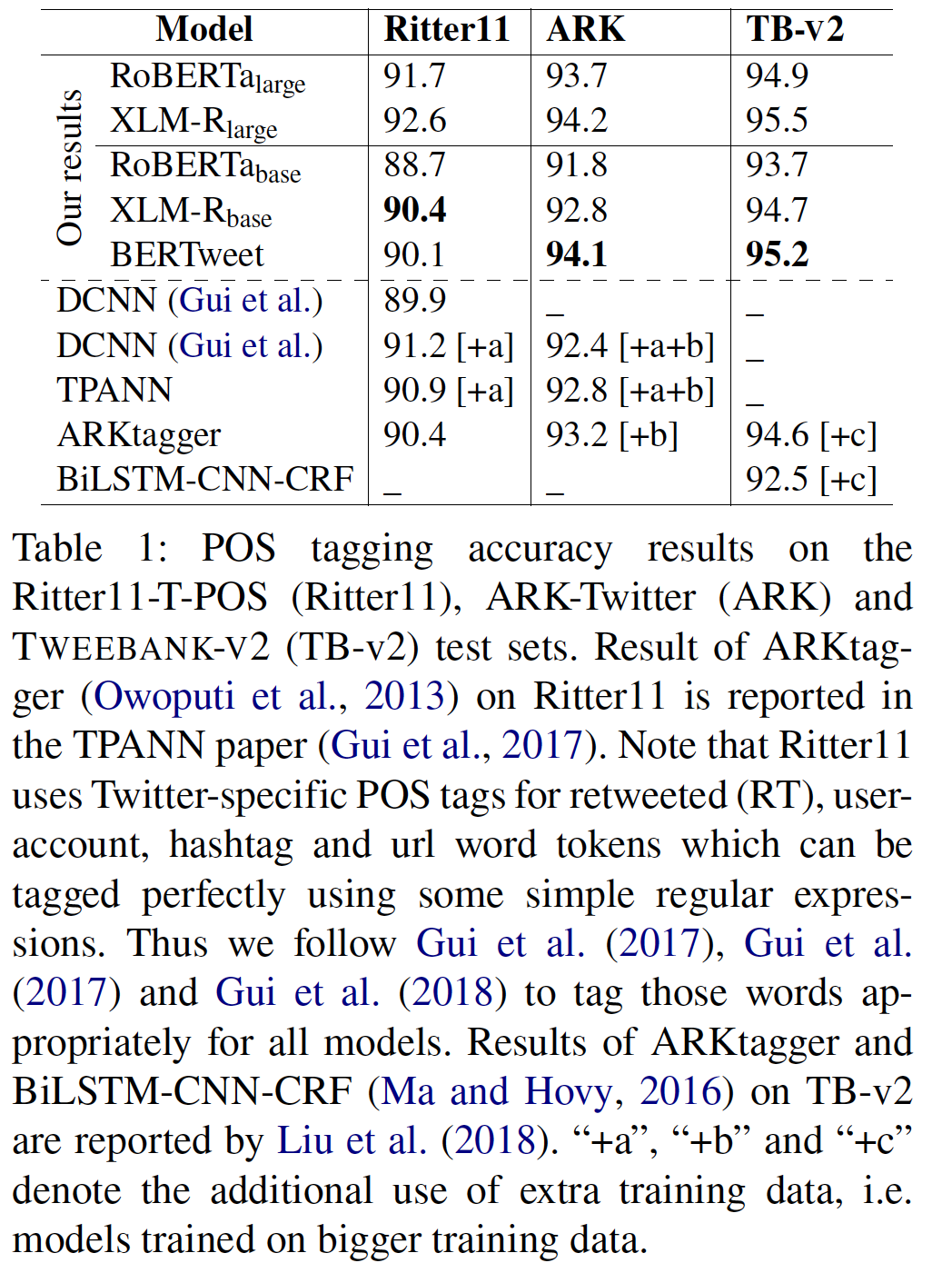
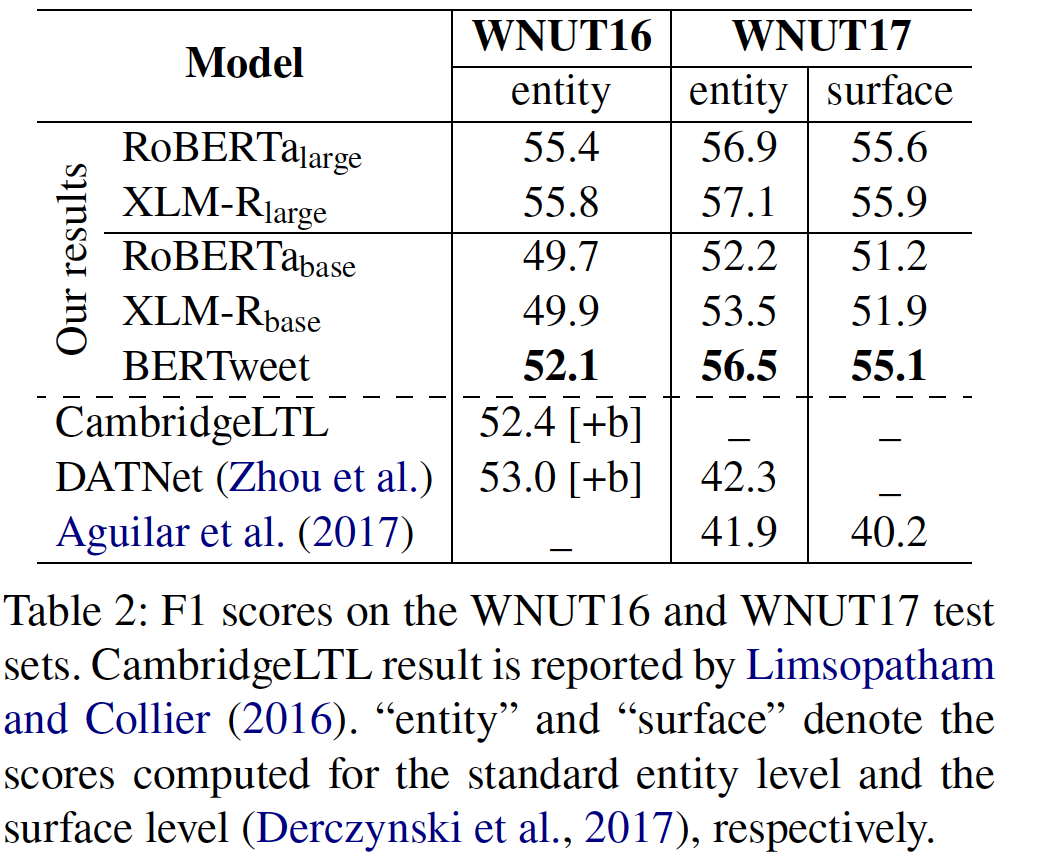
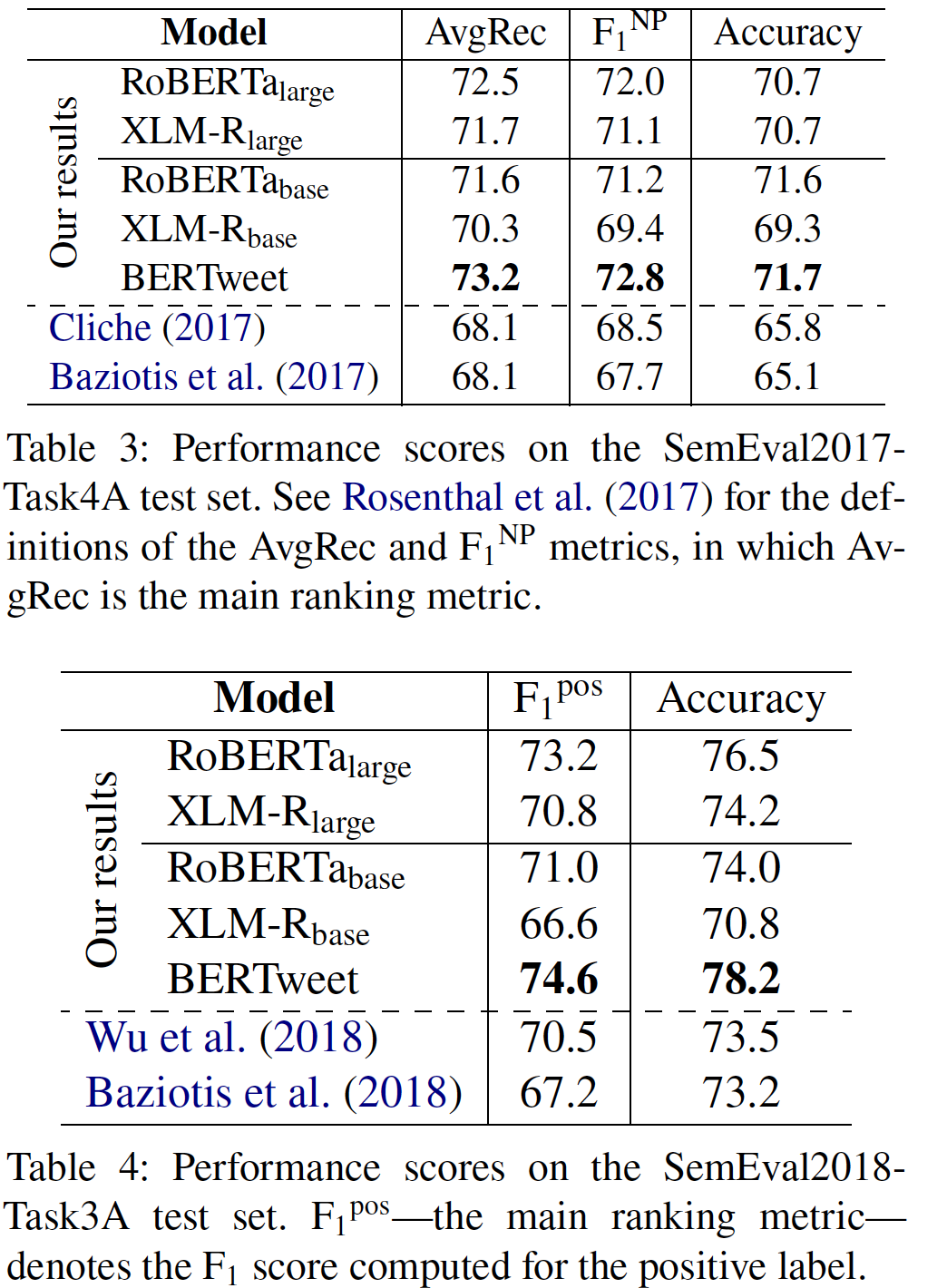
- BERTweet does better than its competitors RoBERTa-base and XLM-R-base and outperforms previous state-of-the-art models on three downstream Tweet NLP tasks of Part-of-speech tagging, Named entity recognition and text classification.
The general architecture and experimental results of BERTweet can be found in our paper:
@article{BERTweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen},
journal = {arXiv preprint},
volume = {arXiv:2005.10200},
year = {2020}
}
Please CITE our paper when BERTweet is used to help produce published results or incorporated into other software.
Main results
Using BERTweet in fairseq
Installation
Pre-trained model
| Model | #params | size | Download |
|---|---|---|---|
BERTweet-base |
135M | 1.2GB | BERTweet_base_fairseq.tar.gz (md5sum 692cd647e630c9f5de5d3a6ccfea6eb2) |
wget https://public.vinai.io/BERTweet_base_fairseq.tar.gztar -xzvf BERTweet_base_fairseq.tar.gz
Example usage
import torch
# Load BERTweet-base in fairseq
from fairseq.models.roberta import RobertaModel
BERTweet = RobertaModel.from_pretrained('/Absolute-path-to/BERTweet_base_fairseq', checkpoint_file='model.pt')
BERTweet.eval() # disable dropout (or leave in train mode to finetune)
# Incorporate the BPE encoder into BERTweet-base
from fairseq.data.encoders.fastbpe import fastBPE
from fairseq import options
parser = options.get_preprocessing_parser()
parser.add_argument('--bpe-codes', type=str, help='path to fastBPE BPE', default="/Absolute-path-to/BERTweet_base_fairseq/bpe.codes")
args = parser.parse_args()
BERTweet.bpe = fastBPE(args) #Incorporate the BPE encoder into BERTweet
# INPUT TEXT IS TOKENIZED!
line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
# Extract the last layer's features
subwords = BERTweet.encode(line)
last_layer_features = BERTweet.extract_features(subwords)
assert last_layer_features.size() == torch.Size([1, 21, 768])
# Extract all layer's features (layer 0 is the embedding layer)
all_layers = BERTweet.extract_features(subwords, return_all_hiddens=True)
assert len(all_layers) == 13
assert torch.all(all_layers[-1] == last_layer_features)
# Filling marks
masked_line = 'SC has first two presumptive cases of <mask> , DHEC confirms HTTPURL via @USER :cry:'
topk_filled_outputs = BERTweet.fill_mask(masked_line, topk=5)
for candidate in topk_filled_outputs:
print(candidate)
# ('SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:', 0.8643638491630554, 'coronavirus')
# ('SC has first two presumptive cases of Coronavirus , DHEC confirms HTTPURL via @USER :cry:', 0.04520644247531891, 'Coronavirus')
# ('SC has first two presumptive cases of #coronavirus , DHEC confirms HTTPURL via @USER :cry:', 0.035870883613824844, '#coronavirus')
# ('SC has first two presumptive cases of #COVID19 , DHEC confirms HTTPURL via @USER :cry:', 0.029708299785852432, '#COVID19')
# ('SC has first two presumptive cases of #Coronavirus , DHEC confirms HTTPURL via @USER :cry:', 0.005226477049291134, '#Coronavirus')
Using BERTweet in HuggingFace's transformers
Installation
- Prerequisite: Installation w.r.t.
fairseq transformers:pip3 install transformers
Pre-trained model
| Model | #params | size | Download |
|---|---|---|---|
BERTweet-base |
135M | 0.3GB | BERTweet_base_transformers.tar.gz (md5sum defd97f13fe176835fa74495b1da7f00) |
wget https://public.vinai.io/BERTweet_base_transformers.tar.gztar -xzvf BERTweet_base_transformers.tar.gz
Example usage
import torch
import argparse
from transformers import RobertaConfig
from transformers import RobertaModel
from fairseq.data.encoders.fastbpe import fastBPE
from fairseq.data import Dictionary
# Load model
config = RobertaConfig.from_pretrained(
"/Absolute-path-to/BERTweet_base_transformers/config.json"
)
BERTweet = RobertaModel.from_pretrained(
"/Absolute-path-to/BERTweet_base_transformers/model.bin",
config=config
)
# Load BPE encoder
parser = argparse.ArgumentParser()
parser.add_argument('--bpe-codes',
default="/Absolute-path-to/BERTweet_base_transformers/bpe.codes",
required=False,
type=str,
help='path to fastBPE BPE'
)
args = parser.parse_args()
bpe = fastBPE(args)
# Load the dictionary
vocab = Dictionary()
vocab.add_from_file("/Absolute-path-to/BERTweet_base_transformers/dict.txt")
# INPUT TEXT IS TOKENIZED!
line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
# Encode the line using fastBPE & Add prefix <s> and suffix </s>
subwords = '<s> ' + bpe.encode(line) + ' </s>'
# Map subword tokens to corresponding indices in the dictionary
input_ids = vocab.encode_line(subwords, append_eos=False, add_if_not_exist=False).long().tolist()
# Convert into torch tensor
all_input_ids = torch.tensor([input_ids], dtype=torch.long)
# Extract features
with torch.no_grad():
features = BERTweet(all_input_ids)
# Represent each word by the contextualized embedding of its first subword token
# i. Get indices of the first subword tokens of words in the input sentence
listSWs = subwords.split()
firstSWindices = []
for ind in range(1, len(listSWs) - 1):
if not listSWs[ind - 1].endswith("@@"):
firstSWindices.append(ind)
# ii. Extract the corresponding contextualized embeddings
words = line.split()
assert len(firstSWindices) == len(words)
vectorSize = features[0][0, 0, :].size()[0]
for word, index in zip(words, firstSWindices):
print(word + " --> " + " ".join([str(features[0][0, index, :][_ind].item()) for _ind in range(vectorSize)]))
# print(word + " --> " + listSWs[index] + " --> " + " ".join([str(features[0][0, index, :][_ind].item()) for _ind in range(vectorSize)]))
A script to pre-process raw input Tweets
Before applying fastBPE to the pre-training corpus of 850M English Tweets, we tokenized these Tweets using TweetTokenizer from the NLTK toolkit and used the emoji package to translate emotion icons into text strings (here, each icon is referred to as a word token). We also normalized the Tweets by converting user mentions and web/url links into special tokens @USER and HTTPURL, respectively. Thus it is recommended to also apply the same pre-processing step for BERTweet-based downstream applications w.r.t. the raw input Tweets.
- Installation:
pip3 install nltk emoji
from TweetNormalizer import normalizeTweet
print(normalizeTweet("SC has first two presumptive cases of coronavirus, DHEC confirms https://postandcourier.com/health/covid19/sc-has-first-two-presumptive-cases-of-coronavirus-dhec-confirms/article_bddfe4ae-5fd3-11ea-9ce4-5f495366cee6.html?utm_medium=social&utm_source=twitter&utm_campaign=user-share… via @postandcourier"))




