LAMA: LAnguage Model Analysis
LAMA is a set of connectors to pre-trained language models.
LAMA exposes a transparent and unique interface to use:
- Transformer-XL (Dai et al., 2019)
- BERT (Devlin et al., 2018)
- ELMo (Peters et al., 2018)
- GPT (Radford et al., 2018)
Actually, LAMA is also a beautiful animal.
What can you do with LAMA?
1. Encode a list of sentences
and use the vectors in your downstream task!
pip install -e git+https://github.com/facebookresearch/LAMA#egg=LAMA
import argparse
from lama.build_encoded_dataset import encode, load_encoded_dataset
PARAMETERS= {
"lm": "bert",
"bert_model_name": "bert-large-cased",
"bert_model_dir":
"pre-trained_language_models/bert/cased_L-24_H-1024_A-16",
"bert_vocab_name": "vocab.txt",
"batch_size": 32
}
args = argparse.Namespace(**PARAMETERS)
sentences = [
["The cat is on the table ."], # single-sentence instance
["The dog is sleeping on the sofa .", "He makes happy noises ."], # two-sentence
]
encoded_dataset = encode(args, sentences)
print("Embedding shape: %s" % str(encoded_dataset[0].embedding.shape))
print("Tokens: %r" % encoded_dataset[0].tokens)
# save on disk the encoded dataset
encoded_dataset.save("test.pkl")
# load from disk the encoded dataset
new_encoded_dataset = load_encoded_dataset("test.pkl")
print("Embedding shape: %s" % str(new_encoded_dataset[0].embedding.shape))
print("Tokens: %r" % new_encoded_dataset[0].tokens)
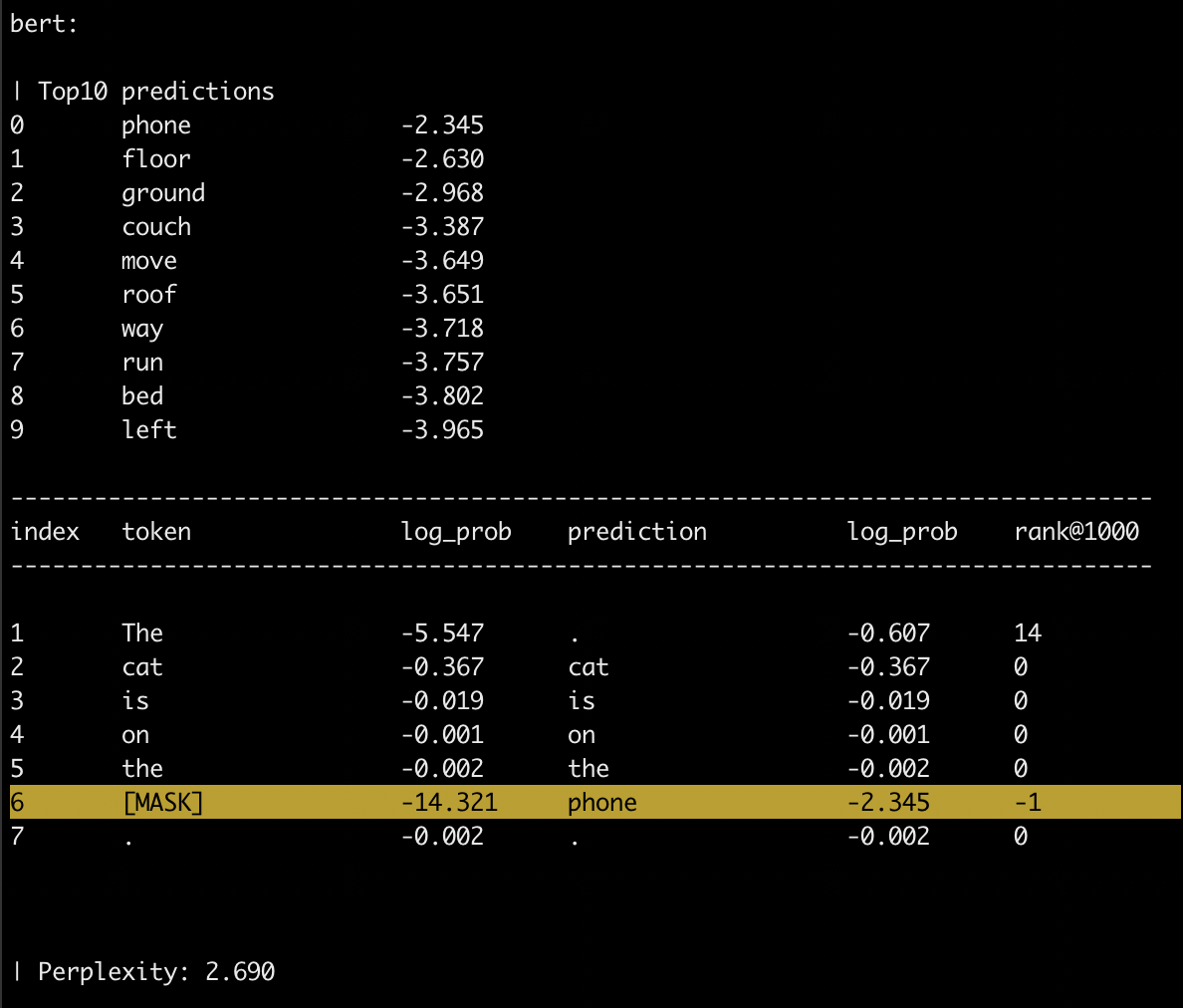
2. Fill a sentence with a gap.
You should use the symbol [MASK] to specify the gap.
Only single-token gap supported - i.e., a single [MASK].
python lama/eval_generation.py \
--lm "bert" \
--t "The cat is on the [MASK]."

source: https://commons.wikimedia.org/wiki/File:Bluebell_on_the_phone.jpg
Note that you could use this functionality to answer cloze-style questions, such as:
python lama/eval_generation.py \
--lm "bert" \
--t "The theory of relativity was developed by [MASK] ."
Dependencies
(optional) It might be a good idea to use a separate conda environment. It can be created by running:
conda create -n lama36 python=3.6 && conda activate lama36
Clone the repo
git clone [email protected]:facebookresearch/LAMA.git && cd LAMA
Install as an editable package:
pip install --editable .
If you get an error in mac os x, please try running this instead
CFLAGS="-Wno-deprecated-declarations -std=c++11 -stdlib=libc++" pip install --editable .
Finally, install spacy model
python3 -m spacy download en
Download the models
DISCLAIMER: ~55 GB on disk
chmod +x download_models.sh
./download_models.sh
The script will create and populate a pre-trained_language_models folder.
If you are interested in a particular model please edit the script.
Language Model(s) options
Option to indicate which language model(s) to use:
- --language-models/--lm : comma separated list of language models (REQUIRED)
BERT
BERT pretrained models can be loaded both: (i) passing the name of the model and using huggingface cached versions or (ii) passing the folder containing the vocabulary and the PyTorch pretrained model (look at convert_tf_checkpoint_to_pytorch in here to convert the TensorFlow model to PyTorch).
- --bert-model-dir/--bmd : directory that contains the BERT pre-trained model and the vocabulary
- --bert-model-name/--bmn : name of the huggingface cached versions of the BERT pre-trained model (default = 'bert-base-cased')
- --bert-vocab-name/--bvn : name of vocabulary used to pre-train the BERT model (default = 'vocab.txt')
ELMo
- --elmo-model-dir/--emd : directory that contains the ELMo pre-trained model and the vocabulary (REQUIRED)
- --elmo-model-name/--emn : name of the ELMo pre-trained model (default = 'elmo_2x4096_512_2048cnn_2xhighway')
- --elmo-vocab-name/--evn : name of vocabulary used to pre-train the ELMo model (default = 'vocab-2016-09-10.txt')
fairseq
- --fairseq-model-dir/--fmd : directory that contains the fairseq pre-trained model and the vocabulary (REQUIRED)
- --fairseq-model-name/--fmn : name of the fairseq pre-trained model (default = 'wiki103.pt')
Transformer-XL
- --transformerxl-model-dir/--tmd : directory that contains the pre-trained model and the vocabulary (REQUIRED)
- --transformerxl-model-name/--tmn : name of the pre-trained model (default = 'transfo-xl-wt103')
GPT
- --gpt-model-dir/--gmd : directory that contains the gpt pre-trained model and the vocabulary (REQUIRED)
- --gpt-model-name/--gmn : name of the gpt pre-trained model (default = 'openai-gpt')
Evaluate Language Model(s) Generation
options:
- --text/--t : text to compute the generation for
- --i : interactive mode
one of the two is required
example considering both BERT and ELMo:
python lama/eval_generation.py \
--lm "bert,elmo" \
--bmd "pre-trained_language_models/bert/cased_L-24_H-1024_A-16/" \
--emd "pre-trained_language_models/elmo/original/" \
--t "The cat is on the [MASK]."
example considering only BERT with the default pre-trained model, in an interactive fashion:
python lamas/eval_generation.py \
--lm "bert" \
--i
Get Contextual Embeddings
python lama/get_contextual_embeddings.py \
--lm "bert,elmo" \
--bmn bert-base-cased \
--emd "pre-trained_language_models/elmo/original/"
Acknowledgements
- https://github.com/huggingface/pytorch-pretrained-BERT
- https://github.com/allenai/allennlp
- https://github.com/pytorch/fairseq
References
-
(Dai et al., 2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc V. Le, and Ruslan Salakhutdi. Transformer-xl: Attentive language models beyond a fixed-length context. CoRR, abs/1901.02860.
-
(Peters et al., 2018) Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. NAACL-HLT 2018
-
(Devlin et al., 2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805.
-
(Radford et al., 2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.





{kind=link}