demo2program
Neural Program Synthesis from Diverse Demonstration Videos.
An official TensorFlow implementation of "Neural Program Synthesis from Diverse Demonstration Videos" (ICML 2018) by Shao-Hua Sun, Hyeonwoo Noh, Sriram Somasundaram, and Joseph J. Lim
As interpreting decision making logic in demonstration videos is key to collaborating with and mimicking humans, our goal is to empower machines with this ability. To this end, we propose a neural program synthesizer that is able to explicitly synthesize underlying programs from behaviorally diverse and visually complicated demonstration videos, as illustrated in the following figure.
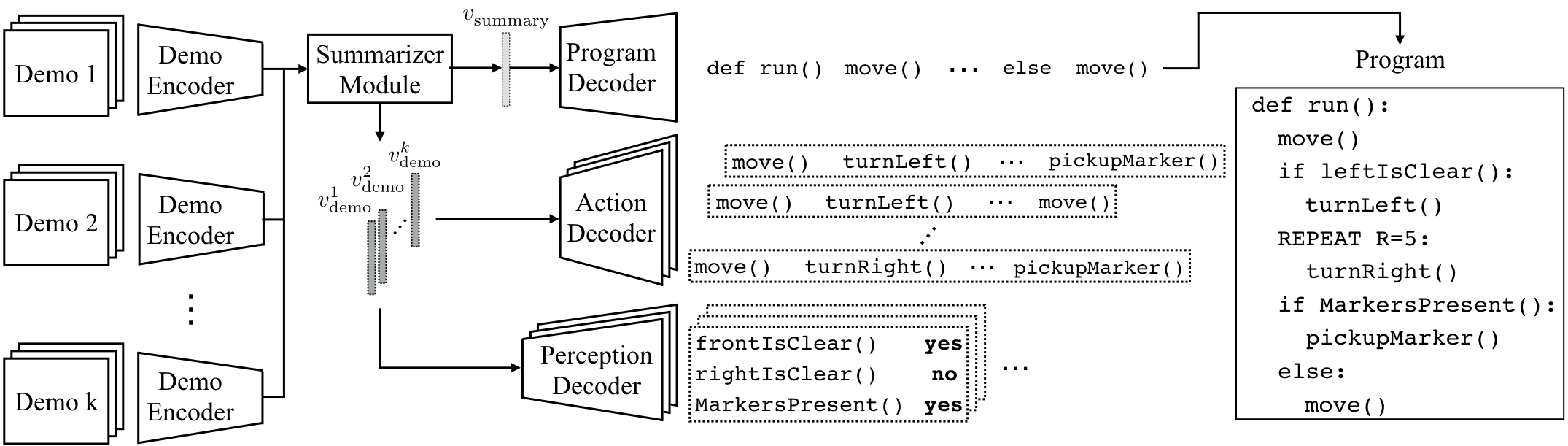
We introduce a summarizer module as part of our model to improve the network’s ability to integrate multiple demonstrations varying in behavior. We also employ a multi-task objective to encourage the model to learn meaningful intermediate representations for end-to-end training. Our proposed model consists three components:
- Demonstration Encoder receives a demonstration video as input and produces an embedding that captures an agent’s actions and perception.
- Summarizer Module discovers and summarizes where actions diverge between demonstrations and upon which branching conditions subsequent actions are taken.
- Program Decoder represents the summarized understanding of demonstrations as a code sequence.
The illustration of the overall architecture is as follows. For more details, please refer to the paper.
Our method is evaluated on a fully observable, third-person environment (Karel environment) and a partially observable, egocentric game (ViZDoom environment). We show that our model is able to reliably synthesize underlying programs as well as capture diverse behaviors exhibited in demonstrations.
*This code is still being developed and subject to change.
Directories
The structure of the repository:
- ./: training and evaluation scripts
- ./models: network models used for the experiments
- ./karel_env: karel environment including dsl, interpreter and dataset generator / loader
- ./vizdoom_env: vizdoom environment including dsl, interpreter and dataset generator / loader
Prerequisites
- Python 2.7
- Tensorflow 1.3.0
- SciPy
- NumPy
- colorlog
- cv2
- h5py
- Pillow
- progressbar
- ply
- ViZDoom Deterministic
Datasets
Karel environment
- You can find the codes for the Karel environments in this directory
- To generate a dataset for Karel environments including programs and demonstrations, use the following script.
./karel_env/generate_dataset.sh
Default arguments are identical to the settings described in the paper.
ViZDoom environment
- To reproduce experiments in our paper, you need to install our deterministic ViZDoom envrionment
- You can find the codes for the ViZDoom environments and detailed instructions in this directory
- To generate a dataset (vizdoom_dataset, vizdoom_dataset_ifelse) for the ViZDoom environment including programs and demonstrations, use the following script.
./vizdoom_env/generate_dataset.sh
Usage
Training
- Train the full model (with the summarizer module and the multi-task objective)
python trainer.py --model full --dataset_path /path/to/the/dataset/ --dataset_type [karel/vizdoom]
- Train the summarizer model (with the summarizer module but without multi-task objective)
python trainer.py --model summarizer --dataset_path /path/to/the/dataset/ --dataset_type [karel/vizdoom]
- Train the baseline program synthesis model (without the summarizer module and multi-task objective)
python trainer.py --model synthesis_baseline --dataset_path /path/to/the/dataset/ --dataset_type [karel/vizdoom]
- Train the baseline program induction model
python trainer.py --model induction_baseline --dataset_path /path/to/the/dataset/ --dataset_type [karel/vizdoom]
- Arguments
- --debug: set to
Trueto see debugging visualization (LSTM masks, etc.) - --prefix: a nickname for the training
- --model: specify which type of models to train/test
- --dataset_type: choose between
karelandvizdoom. You can also add your own datasets. - --dataset_path: specify the path to the dataset where you can find a HDF5 file and a .txt file
- --checkpoint: specify the path to a pre-trained checkpoint
- Logging
- --log_setp: the frequency of outputing log info ([train step 681] Loss: 0.51319 (1.896 sec/batch, 16.878 instances/sec))
- --write_summary_step: the frequency of writing TensorBoard summaries (default 100)
- --test_sample_step: the frequency of performing testing inference during training (default 100)
- Hyperparameters
- --num_k: the number of seen demonstrations (default 10)
- --batch_size: the mini-batch size (default 32)
- --learning_rate: the learning rate (default 1e-3)
- --lr_weight_decay: set to
Trueto perform expotential weight decay on the learning rate - --scheduled_sampling: set to
Trueto train models with scheduled sampling
- Architecture
- --encoder_rnn_type: the recurrent model of the demonstration encoder. Choices include RNN, GRU, and LSTM
- --num_lstm_cell_units: the size of RNN/GRU/LSTM hidden layers (default 512)
- --demo_aggregation: how to aggregate the demo features (default average pooling) for synthesis and induction baseline
- --debug: set to
Testing
- Evaluate trained models
python evaler.py --model [full/synthesis_baseline/summarizer/induction_baseline] --dataset_path /path/to/the/dataset/ --dataset_type [karel/vizdoom] [--train_dir /path/to/the/training/dir/ OR --checkpoint /path/to/the/trained/model]
Results
Karel environment
| Methods | Execution | Program | Sequence |
|---|---|---|---|
| Induction baseline | 62.8% | - | - |
| Synthesis baseline | 64.1% | 42.4% | 35.7% |
| + summarizer (ours) | 68.6% | 45.3% | 38.3% |
| + multi-task loss (ours-full) | 72.1% | 48.9% | 41.0% |
- Effect of the summarizer module
To verify the effectiveness of our proposed summarizer module, we conduct experiments where models are trained on varying numbers of demonstrations (k) and compare the execution accuracy.
| Methods | k=3 | k=5 | k=10 |
|---|---|---|---|
| Synthesis baseline | 58.5% | 60.1% | 64.1% |
| + summarizer (ours) | 60.6% | 63.1% | 68.6% |
ViZDoom environment
| Methods | Execution | Program | Sequence |
|---|---|---|---|
| Induction baseline | 35.1% | - | - |
| Synthesis baseline | 48.2% | 39.9% | 33.1% |
| Ours-full | 78.4% | 62.5% | 53.2% |
- If-else experiment:
To verify the importance of inferring underlying conditions, we perform evaluation only with programs containing a single if-else statement with two branching consequences. This setting is sufficiently simple to isolate other diverse factors that might affect the evaluation result.
| Methods | Execution | Program | Sequence |
|---|---|---|---|
| Induction baseline | 26.5% | - | - |
| Synthesis baseline | 59.9% | 44.4% | 36.1% |
| Ours-full | 89.4% | 69.1% | 58.8% |
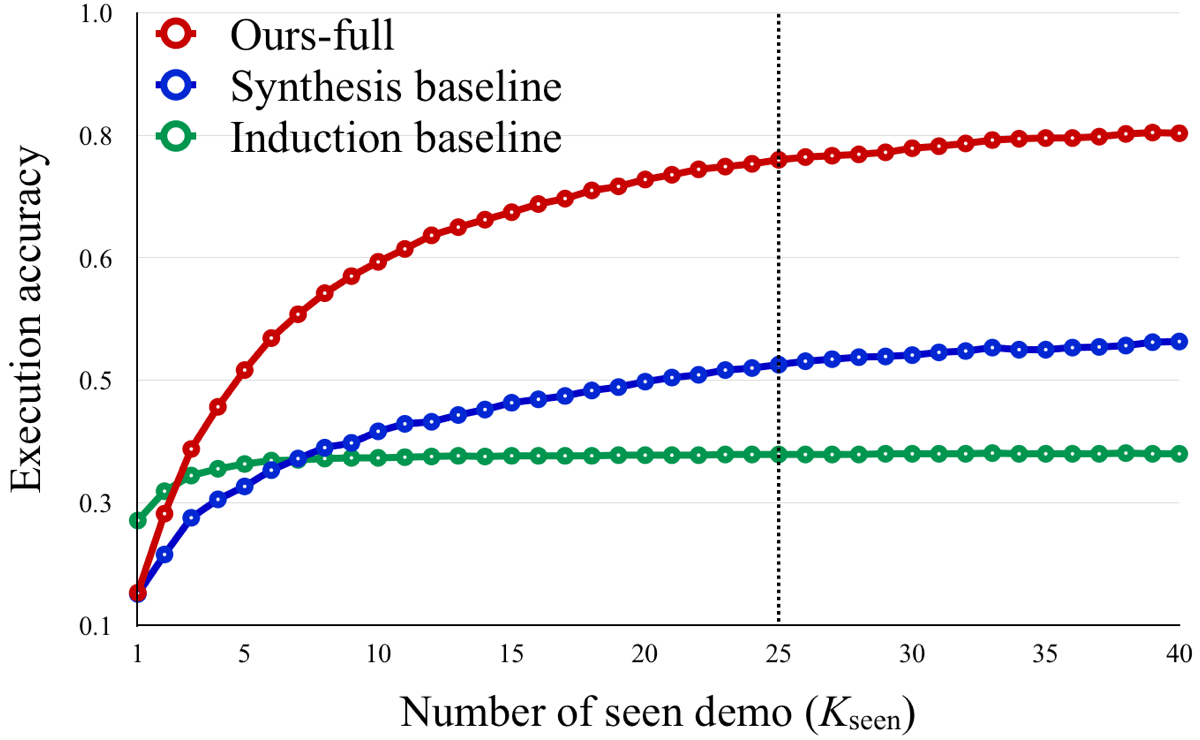
- Generalization over different number of seen demonstrations
The baseline models and our model trained with 25 seen demonstration are evaluated with fewer or more seen demonstrations.