Apache Submarine
Apache Submarine is a unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster.
Goals of Submarine:
- It allows jobs easy access data/models in HDFS and other storages.
- Can launch services to serve TensorFlow/PyTorch/MXNet models.
- Support run distributed TensorFlow jobs with simple configs.
- Support run user-specified Docker images.
- Support specify GPU and other resources.
- Support launch TensorBoard for training jobs if user specified.
- Support customized DNS name for roles (like TensorBoard.$user.$domain:6006)
Architecture
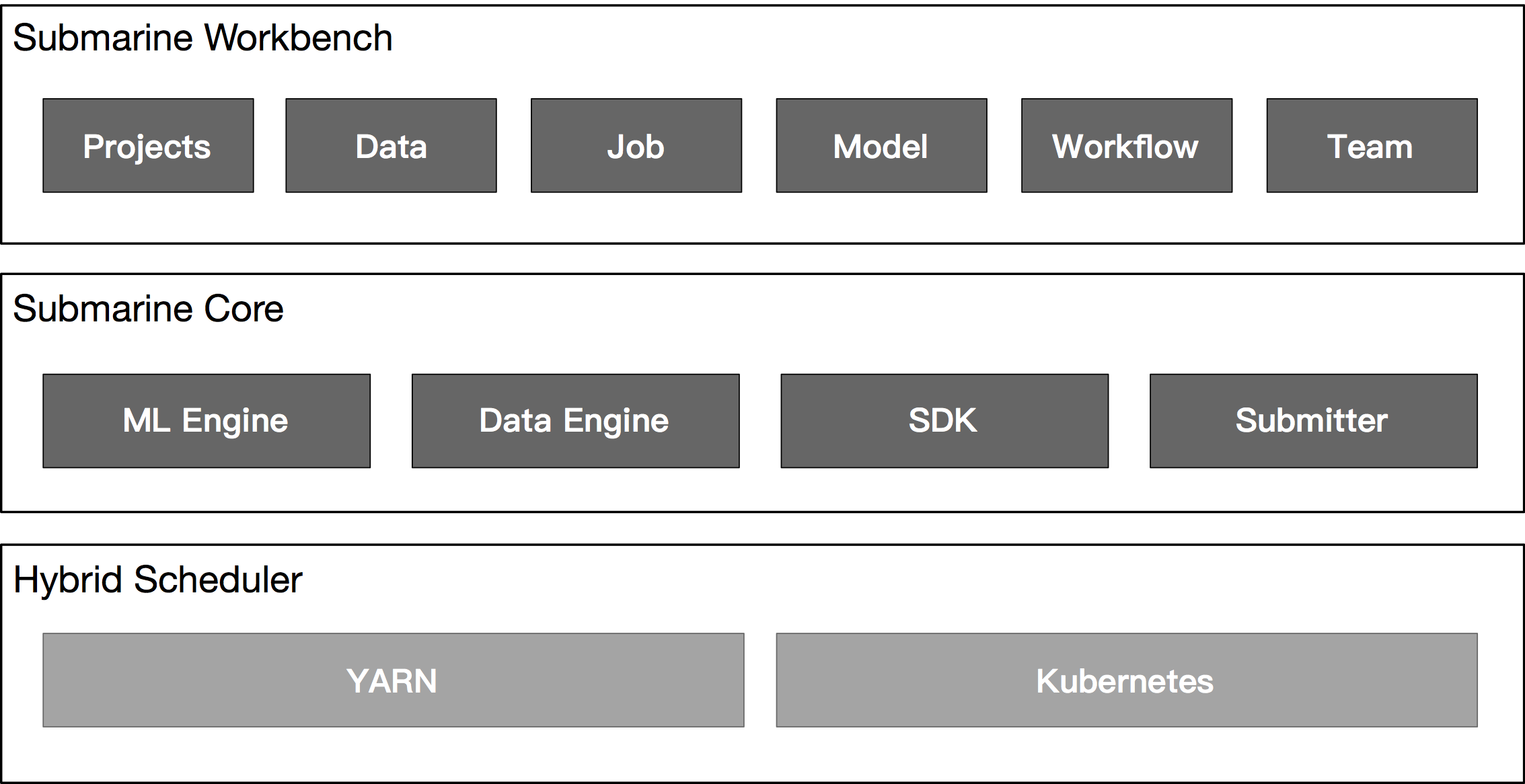
Components
Submarine Workbench
Submarine Workbench is a WEB system. Algorithm engineers can perform complete lifecycle management of machine learning jobs in the Workbench.
-
Projects
Manage machine learning jobs through project.
-
Data
Data processing, data conversion, feature engineering, etc. in the workbench.
-
Job
Data processing, algorithm development, and model training in machine learning jobs as a job run.
-
Model
Algorithm selection, parameter adjustment, model training, model release, model Serving.
-
Workflow
Automate the complete life cycle of machine learning operations by scheduling workflows for data processing, model training, and model publishing.
-
Team
Support team development, code sharing, comments, code and model version management.
Submarine Core
The submarine core is the execution engine of the system and has the following features:
-
ML Engine
Support for multiple machine learning framework access, such as tensorflow, pytorch, mxnet.
-
Data Engine
Docking the externally deployed Spark calculation engine for data processing.
-
SDK
Support Python, Scala, R language for algorithm development, The SDK is provided to help developers use submarine's internal data caching, data exchange, and task tracking to more efficiently improve the development and execution of machine learning tasks.
-
Submitter
Compatible with the underlying hybrid scheduling system of yarn and k8s for unified task scheduling and resource management, so that users are not aware.
- Hybrid Scheduler
- YARN
- Kubernetes



