mrc-for-flat-nested-ner
The repository contains the code of the recent research advances in Shannon.AI.
A Unified MRC Framework for Named Entity Recognition
Xiaoya Li*, Jingrong Feng*, Yuxian Meng, Qinghong Han, Fei Wu, Jiwei Li
Preprint. arXiv
If you find this repo helpful, please cite the following:
@article{li2019unified,
title={A Unified MRC Framework for Named Entity Recognition},
author={Li, Xiaoya and Feng, Jingrong and Meng, Yuxian and Han, Qinghong and Wu, Fei and Li, Jiwei},
journal={arXiv preprint arXiv:1910.11476},
year={2019}
}
For any question, please feel free to contact [email protected] or post Github issue.
Overview
The task of NER is normally divided into nested NER and flat NER depending on whether named entities are nested or not. Instead of treating the task of NER as a sequence labeling problem, we propose to formulate it as a SQuAD-style machine reading comprehension (MRC) task.
For example, the task of assigning the [PER] label to "[Washington] was born into slavery on the farm of James Burroughs" is formalized as answering the question "Which person is mentioned in the text?".
By unifying flat and nested NER under an MRC framework, we're able to gain a huge improvement on both flat and nested NER datasets, which achives SOTA results.
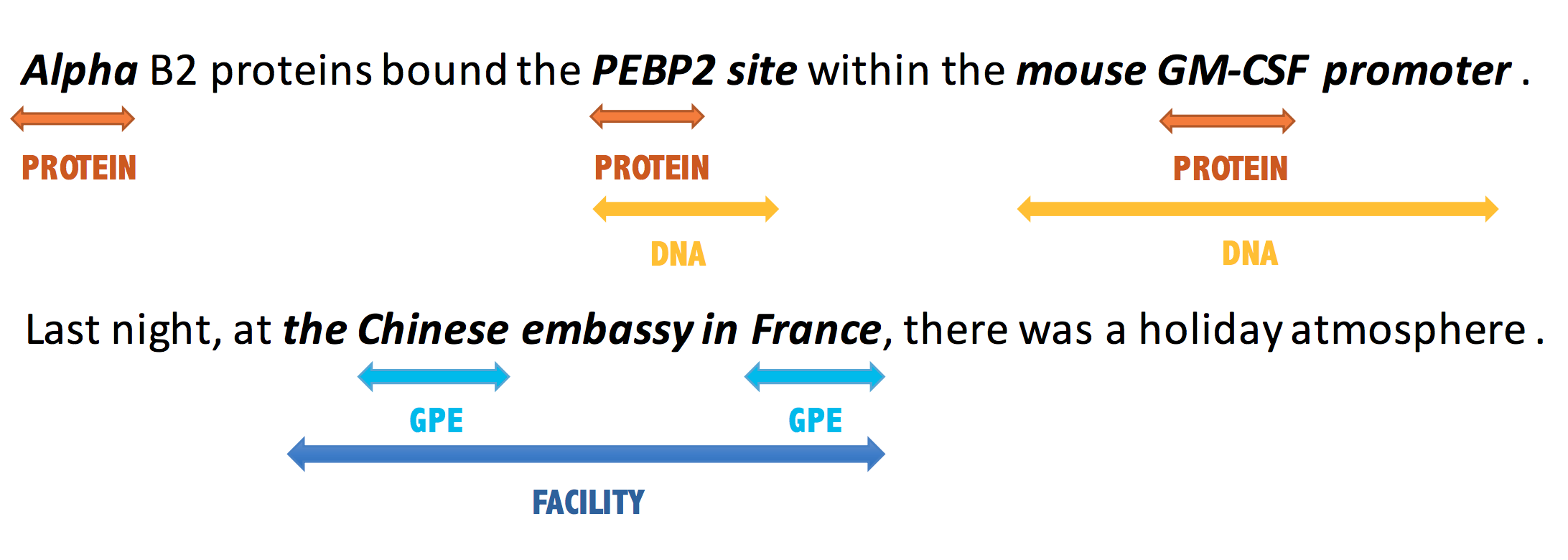
We use MRC-NER to denote the proposed framework.
Here are some of the highlights:
1. MRC-NER works better than BERT-Tagger with less training data.
2. MRC-NER is capable of handling both flat and nested NER tasks.
3. MRC-NER has zero-shot learning ability which can predict labels unseen from the training set.
4. The query encodes significant prior information about the entity category to extract and has the potential to disambiguate similar classes.
Experimental Results on Flat/Nested NER Datasets
Experiments are conducted on both Flat and Nested NER datasets. The proposed method achieves vast amount of performance boost over current SOTA models.
We only list comparisons between our proposed method and previous SOTA in terms of span-level micro-averaged F1-score here.
For more comparisons and span-level micro Precision/Recall scores, please check out our paper.
Flat NER Datasets
Evaluations are conducted on the widely-used bechmarks: CoNLL2003, OntoNotes 5.0 for English; MSRA, OntoNotes 4.0 for Chinese.
| Dataset | Eng-CoNLL03 | Eng-OntoNotes5.0 | Zh-MSRA | Zh-OntoNotes4.0 |
|---|---|---|---|---|
| Previous SOTA | 92.8 | 89.16 | 95.54 | 80.62 |
| Our method | 93.04 | 91.11 | 95.75 | 82.11 |
| (+0.24) | (+1.95) | (+0.21) | (+1.49) |
Previous SOTA:
- BERT-Tagger for CoNLL 2003 and OntoNotes5.0.
- Glyce-BERT for MSRA and OntoNotes 4.0.
Nested NER Datasets
Evaluations are conducted on the widely-used ACE 2004, ACE 2005, GENIA, KBP-2017 English datasets.
| Dataset | ACE 2004 | ACE 2005 | GENIA | KBP-2017 |
|---|---|---|---|---|
| Previous SOTA | 84.7 | 84.33 | 78.31 | 74.6 |
| Our method | 85.98 | 86.88 | 83.75 | 80.97 |
| (+1.28) | (+2.55) | (+5.44) | (+6.37) |
Previous SOTA:
- DYGIE for ACE 2004.
- Seq2Seq-BERT for ACE 2005 and GENIA.
- ARN for KBP2017.
Data Preparation
We release preprocessed and source data files for both flat and nested NER benchmarks.
You can download the preprocessed datasets and source data files from Google Drive.
For data processing, you can follow the guidance to generate your own MRC-based entity recognition training files.
Dependencies
- Packages dependencies:
python >= 3.6
PyTorch == 1.1.0
pytorch-pretrained-bert == 0.6.1
- Download and unzip
BERT-Large, Cased EnglishandBERT-Base, Chinesepretrained checkpoints. Then follow the guideline from huggingface to convert TF checkpoints to PyTorch.
Usage
Training commands could be found under the folder of scripts.
As an example, the following command trains the BERT-MRC on OntoNotes5.0:
base_path=/home/work/mrc-for-flat-nested-ner
bert_model=/data/BERT_BASE_DIR/cased_L-24_H-1024_A-16
data_dir=/data/english_ontonotes
config_path=mrc-for-flat-nested-ner/configs/eng_large_case_bert.json
task_name=ner
max_seq_length=150
num_train_epochs=4
warmup_proportion=-1
seed=3306
data_sign=en_onto
checkpoint=28000
gradient_accumulation_steps=4
learning_rate=6e-6
train_batch_size=36
dev_batch_size=72
test_batch_size=72
export_model=/data/export_folder/${train_batch_size}_lr${learning_rate}
output_dir=${export_model}
CUDA_VISIBLE_DEVICES=2 python3 ${base_path}/run/run_mrc_ner.py \
--config_path ${config_path} \
--data_dir ${data_dir} \
--bert_model ${bert_model} \
--max_seq_length ${max_seq_length} \
--train_batch_size ${train_batch_size} \
--dev_batch_size ${dev_batch_size} \
--test_batch_size ${test_batch_size} \
--checkpoint ${checkpoint} \
--learning_rate ${learning_rate} \
--num_train_epochs ${num_train_epochs} \
--warmup_proportion ${warmup_proportion} \
--export_model ${export_model} \
--output_dir ${output_dir} \
--data_sign ${data_sign} \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--allow_impossible 1




