A Unified Objective for Novel Class Discovery
This is the official repository for the paper:
A Unified Objective for Novel Class Discovery
Enrico Fini, Enver Sangineto Stéphane Lathuilière, Zhun Zhong Moin Nabi, Elisa Ricci
ICCV 2021 (Oral)
Abstract: In this paper, we study the problem of Novel Class Discovery (NCD). NCD aims at inferring novel object categories in an unlabeled set by leveraging from prior knowledge of a labeled set containing different, but related classes. Existing approaches tackle this problem by considering multiple objective functions, usually involving specialized loss terms for the labeled and the unlabeled samples respectively, and often requiring auxiliary regularization terms. In this paper we depart from this traditional scheme and introduce a UNified Objective function (UNO) for discovering novel classes, with the explicit purpose of favoring synergy between supervised and unsupervised learning. Using a multi-view self-labeling strategy, we generate pseudo-labels that can be treated homogeneously with ground truth labels. This leads to a single classification objective operating on both known and unknown classes. Despite its simplicity, UNO outperforms the state of the art by a significant margin on several benchmarks (+10% on CIFAR-100 and +8% on ImageNet).
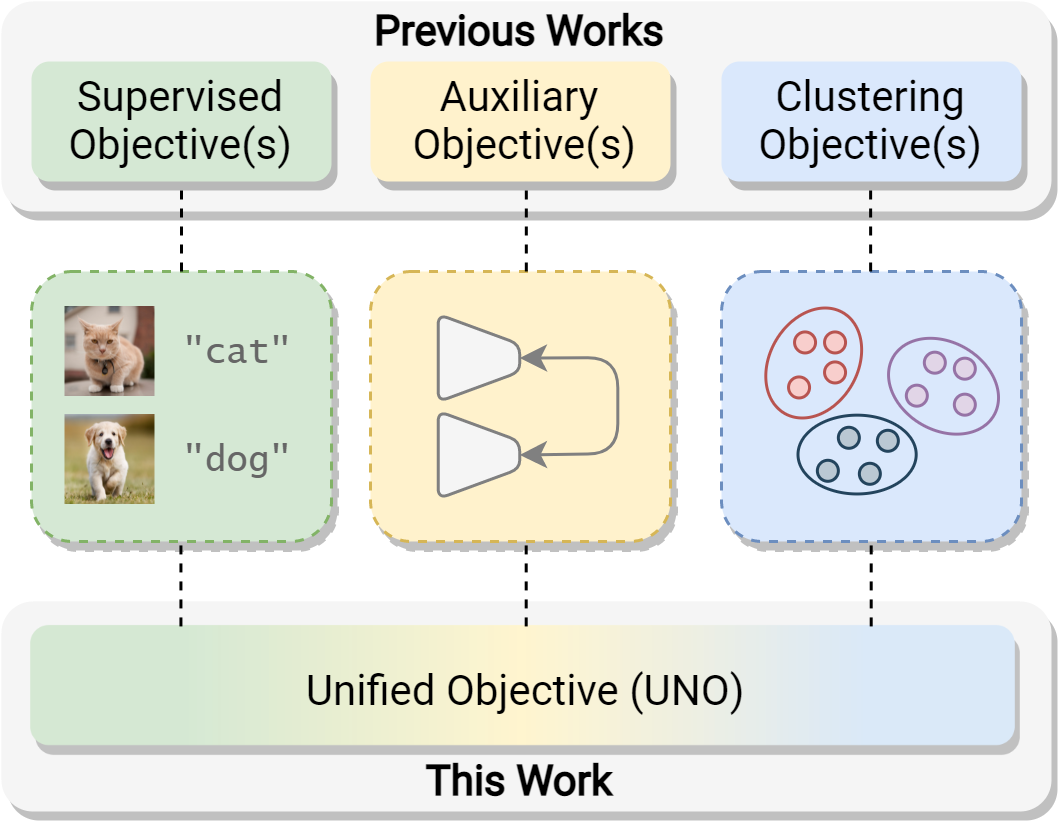
A visual comparison of our UNified Objective (UNO) with previous works.
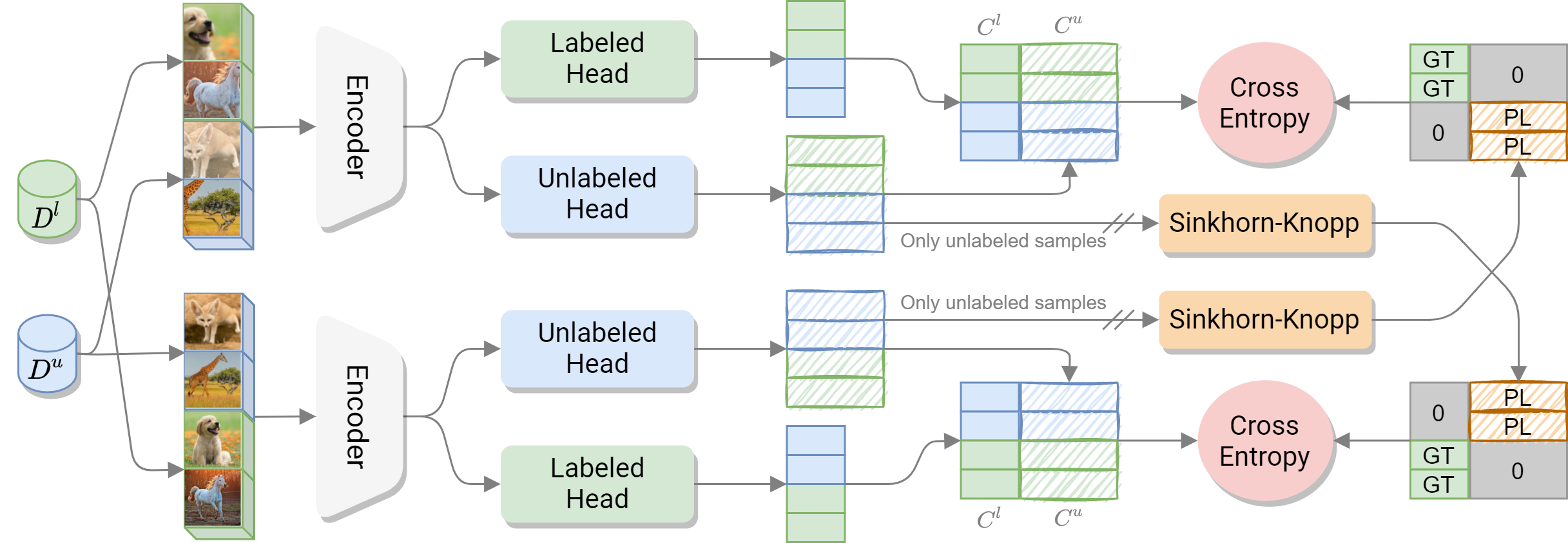
Overview of the proposed architecture.
Installation
Our implementation is based on PyTorch and PyTorch Lightning. Logging is performed using Wandb. We recommend using conda to create the environment and install dependencies:
conda create --name uno python=3.8
conda activate uno
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=XX.X -c pytorch
pip install pytorch-lightning==1.1.3 lightning-bolts==0.3.0 wandb sklearn
mkdir -p logs/wandb checkpoints
Select the appropriate cudatoolkit version according to your system. Optionally, you can also replace pillow with pillow-simd (if your machine supports it) for faster data loading:
pip uninstall pillow
CC="cc -mavx2" pip install -U --force-reinstall pillow-simd
Datasets
For CIFAR10 and CIFAR100 you can just pass --download and the datasets will be automatically downloaded in the directory specified with --data_dir YOUR_DATA_DIR.
For ImageNet you will need to follow the instructions on this website.
Checkpoints
All checkpoints (after the pretraining phase) are available on Google Drive. We recommend using gdown to download them directly to your server. First, install gdown with the following command:
pip install gdown
Then, open the Google Drive folder, choose the checkpoint you want to download, do right click and select Get link > Copy link. For instance, for CIFAR10 the link will look something like this:
https://drive.google.com/file/d/1Pa3qgHwK_1JkA-k492gAjWPM5AW76-rl/view?usp=sharing
Now, remove /view?usp=sharing and replace file/d/ with uc?id=. Finally, download the checkpoint running the following command:
gdown https://drive.google.com/uc?id=1Pa3qgHwK_1JkA-k492gAjWPM5AW76-rl
Logging
Logging is performed with Wandb. Please create an account and specify your --entity YOUR_ENTITY and --project YOUR_PROJECT. For debugging, or if you do not want all the perks of Wandb, you can disable logging by passing --offline.
Commands
Pretraining
Running pretraining on CIFAR10 (5 labeled classes):
python main_pretrain.py --dataset CIFAR10 --gpus 1 --precision 16 --max_epochs 200 --batch_size 256 --num_labeled_classes 5 --num_unlabeled_classes 5 --comment 5_5
Running pretraining on CIFAR100-80 (80 labeled classes):
python main_pretrain.py --dataset CIFAR100 --gpus 1 --precision 16 --max_epochs 200 --batch_size 256 --num_labeled_classes 80 --num_unlabeled_classes 20 --comment 80_20
Running pretraining on CIFAR100-50 (50 labeled classes):
python main_pretrain.py --dataset CIFAR100 --gpus 1 --precision 16 --max_epochs 200 --batch_size 256 --num_labeled_classes 50 --num_unlabeled_classes 50 --comment 50_50
Running pretraining on ImageNet (882 labeled classes):
python main_pretrain.py --gpus 2 --num_workers 8 --distributed_backend ddp --sync_batchnorm --precision 16 --dataset ImageNet --data_dir PATH/TO/IMAGENET --max_epochs 100 --warmup_epochs 5 --batch_size 256 --num_labeled_classes 882 --num_unlabeled_classes 30 --comment 882_30
Discovery
Running discovery on CIFAR10 (5 labeled classes, 5 unlabeled classes):
python main_discover.py --dataset CIFAR10 --gpus 1 --precision 16 --max_epochs 200 --batch_size 256 --num_labeled_classes 5 --num_unlabeled_classes 5 --pretrained PATH/TO/CHECKPOINTS/pretrain-resnet18-CIFAR10.cp --num_heads 4 --comment 5_5
Running discovery on CIFAR100-20 (80 labeled classes, 20 unlabeled classes):
python main_discover.py --dataset CIFAR100 --gpus 1 --max_epochs 200 --batch_size 256 --num_labeled_classes 80 --num_unlabeled_classes 20 --pretrained PATH/TO/CHECKPOINTS/pretrain-resnet18-CIFAR100-80_20.cp --num_heads 4 --comment 80_20 --precision 16
Running discovery on CIFAR100-50 (50 labeled classes, 50 unlabeled classes):
python main_discover.py --dataset CIFAR100 --gpus 1 --max_epochs 200 --batch_size 256 --num_labeled_classes 50 --num_unlabeled_classes 50 --pretrained PATH/TO/CHECKPOINTS/pretrain-resnet18-CIFAR100-50_50.cp --num_heads 4 --comment 50_50 --precision 16
Running discovery on ImageNet (882 labeled classes, 30 unlabeled classes)
python main_discover.py --dataset ImageNet --gpus 2 --num_workers 8 --distributed_backend ddp --sync_batchnorm --precision 16 --data_dir PATH/TO/IMAGENET --max_epochs 60 --base_lr 0.02 --warmup_epochs 5 --batch_size 256 --num_labeled_classes 882 --num_unlabeled_classes 30 --num_heads 3 --pretrained PATH/TO/CHECKPOINTS/pretrain-resnet18-ImageNet.cp --imagenet_split A --comment 882_30-A
NOTE: to run ImageNet split B/C just pass --imagenet_split B/C.
Citation
If you like our work, please cite our paper:
@InProceedings{fini2021unified,
author = {Fini, Enrico and Sangineto, Enver and Lathuilière, Stéphane and Zhong, Zhun and Nabi, Moin and Ricci, Elisa},
title = {A Unified Objective for Novel Class Discovery},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2021}
}







