You Don't Need a Bigger Boat
An end-to-end (Metaflow-based) implementation of an intent prediction flow for kids who can't MLOps good and wanna learn to do other stuff good too.
This is a WIP - check back often for updates.
Philosophical Motivations
There is plenty of tutorials and blog posts around the Internet on data pipelines and tooling. However:
- they (for good pedagogical reasons) tend to focus on one tool / step at a time, leaving us to wonder how
the rest of the pipeline works; - they (for good pedagogical reasons) tend to work in a toy-world fashion, leaving us to wonder what would happen
when a real dataset and a real-world problem enter the scene.
This repository (and soon-to-be-drafted written tutorial) aims to fill these gaps. In particular:
- we provide open-source working code that glues together what we believe are some of the best tools in the ecosystem,
going all the way from raw data to a deployed endpoint serving predictions; - we run the pipeline under a realistic load for companies at "reasonable scale", leveraging
a huge open dataset we released in 2021; moreover, we train a model for a real-world
use case, and show how to monitor it after deployment.
The repo may also be seen as a (very opinionated) introduction to modern, PaaS-like pipelines; while there is obviously
room for disagreement over tool X or tool Y, we believe the general principles to be sound for companies at
"reasonable scale": in-between bare-bone infrastructure for Tech Giants, and ready-made solutions for low-code/simple
scenarios, there is a world of exciting machine learning at scale for sophisticated practitioners who don't want to
waste their time managing cloud resources.
Overview
The repo shows how several (mostly open-source) tools can be effectively combined together to run data pipelines. The
project current features:
- Metaflow for ML DAGs (Alternatives: Luigi (?))
- Snowflake as a data warehouse solution (Alternatives: Redshift)
- Prefect as a general orchestrator (Alternatives: Airflow)
- dbt for data transformation (Alternatives: ?)
- Great Expectations for data quality (Alternatives: dbt-expectations plugin)
- Weights&Biases for experiment tracking (Alternatives: Comet)
- Gantry for ML monitoring (Alternatives: Aporia)
- Sagemaker / Lambda for model serving (Alternatives: many)
The following picture from our Recsys paper (forthcoming) gives a quick overview of such a pipeline:
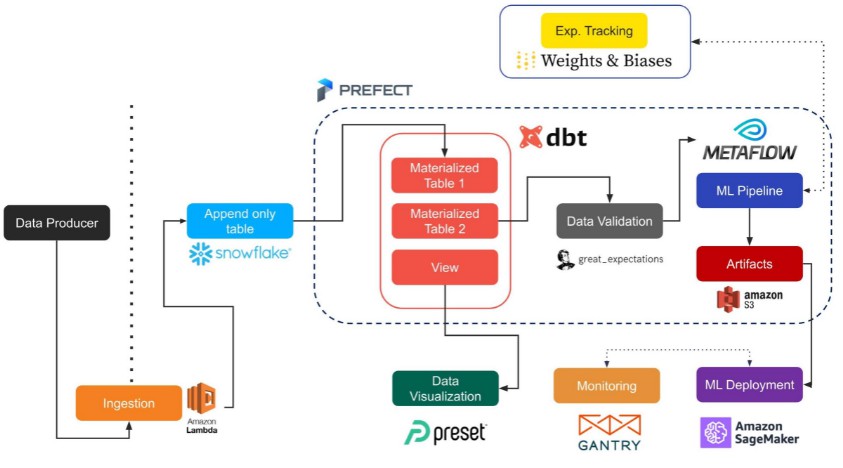
We provide two versions of the pipeline, depending on the sophistication of the setup:
- a Metaflow-only version, which runs from static data files (see below) to Sagemaker as a single Flow, and can be run
from a Metaflow-enabled laptop without much additional setup; - a data warehouse version, which runs in a more realistic setup, reading data from Snowflake and using an external
orchestrator to run the steps. In this setup, the downside is that a Snowflake and a Prefect Cloud accounts are required
(nonetheless, both are veasy to get); the upside is that the pipeline reflects almost perfectly a real setup, and Metaflow
can be used specifically for the ML part of the process.
The parallelism between the two scenarios should be pretty clear by looking at the two projects: if you are familiarizing with
all the tools for the first time, we suggest you to start from the Metaflow version and then move to the full-scale one
when all the pieces of the puzzle are well understood.
Relevant Material
If you want to know more, you can give a look at the following material:
- "Serverless MLOps for Reasonable Companies" (video),
Data Science Meetup, June 2021; - "You Do Not Need a Bigger Boat: Recommendations at Reasonable Scale in a (Mostly) Serverless and Open Stack"
(preprint),RecSys 2021.
TBC
Status Update
July 2021
End-2-end flow working for remote and local projects; started standardizing Prefect agents with Docker and
adding other services (monitoring, feature store etc.).
TO-DOs:
- dockerize the local flow;
- write-up all of this as a blog post;
- improve code / readability / docs, add potentially some more pics and some videos;
- providing an orchestrator-free version, by using step functions to manage the steps;
- finish feature store and gantry integration;
- add Github Action flow;
- continue improving the DAG card project.
Setup
General Prerequisites (do this first!)
Irrespectively of the flow you wish to run, some general tools need to be in place: Metaflow of course,
as the heart of our ML practice, but also data and AWS users/roles. Please go through the general items below before
tackling the flow-specific instructions.
After you finish the prerequisites below, you can run the flow you desire: each folder - remote and local - contains
a specific README which should allow you to quickly run the project end-to-end: please refer to that documentation for
flow-specific instructions (check back often for updates).
Dataset
The project leverages the open dataset from the 2021 Coveo Data Challenge:
the dataset can be downloaded directly from here (refer to the
full README for terms and conditions).
Data is freely available under a research-friendly license - for background information on the dataset,
the use cases and relevant work in the ML literature, please refer to the
accompanying paper.
Once you download and unzip the dataset in a local folder of your choice
(the zip contains 3 files, browsing_train.csv, search_train.csv, sku_to_content.csv),
write down their location as an absolute path (e.g. /Users/jacopo/Documents/data/train/browsing_train.csv):
both projects need to know where the dataset is.
AWS
Both projects - remote and local - use AWS services extensively - and by design: this ties back to our philosophy
of PaaS-whenever-possible, and play nicely with our core adoption of Metaflow. While you can setup your users in many
functionally equivalent ways, note that if you want to run the pipeline from ingestion to serving you need to be
comfortable with the following AWS interactions:
- Metaflow stack (see below): we assume you installed the Metaflow stack and can run it with an AWS profile of your choice;
- Serverless stack (see below): we assume you can run
serverless deployin your AWS stack; - Sagemaker user: we assume you have an AWS user with permissions to manage Sagemaker endpoints (it may be totally
distinct from any other Metaflow user).
TBC
Serverless
We wrap Sagemaker predictions in a serverless REST endpoint provided by AWS Lambda and API Gateway. To manage the lambda
stack we use Serverless as a wrapper around AWS infrastructure.
TBC
Metaflow
Metaflow: Configuration
If you have an AWS profile configured with a metaflow-friendly user, and you created
metaflow stack with CloudFormation, you can run the following command with the resources
created by CloudFormation to set up metaflow on AWS:
metaflow configure aws --profile metaflow
Remember to use METAFLOW_PROFILE=metaflow to use this profile when running a flow. Once
you completed the setup, you can run flow_playground.py to test the AWS setup is working
as expected (in particular, GPU batch jobs can run correctly). To run the flow with the
custom profile created, you should do:
METAFLOW_PROFILE=metaflow python flow_playground.py run
Metaflow: Tips & Tricks
- Parallelism Safe Guard
- The flag
--max-workersshould be used to limit the maximum number of parallel steps - For example
METAFLOW_PROFILE=metaflow python flow_playground.py run --max-workers 8limits
the maximum number of parallel tasks to 8
- The flag
- Environment Variables in AWS Batch
- The
@environmentdecorator is used in conjunction with@batchto pass environment variables to
AWS Batch, which will not directly have access to env variables on your local machine - In the
localexample, we use@environemntto pass the Weights & Biases API Key (amongst other things)
- The
- Resuming Flows
- Resuming flows is useful during development to avoid re-running compute/time intensive steps
such as data preparation METAFLOW_PROFILE=metaflow python flow_playground.py resume <STEP_NAME> --origin-run-id <RUN_ID>
- Resuming flows is useful during development to avoid re-running compute/time intensive steps
- Local-Only execution
- It may sometimes be useful to debug locally (i.e to avoid Batch startup latency), we introduce a wrapper
enable_decoratoraround the@batchdecorator which enables or disables a decorator's functionality - We use this in conjunction with an environment variable
EN_BATCHto toggle the functionality
of all@batchdecorators.
- It may sometimes be useful to debug locally (i.e to avoid Batch startup latency), we introduce a wrapper
GitHub
https://github.com/jacopotagliabue/you-dont-need-a-bigger-boat



