NeuralClassifier
NeuralClassifier is designed for quick implementation of neural models for hierarchical multi-label classification task, which is more challenging and common in real-world scenarios. A salient feature is that NeuralClassifier currently provides a variety of text encoders, such as FastText, TextCNN, TextRNN, RCNN, VDCNN, DPCNN, DRNN, AttentiveConvNet and Transformer encoder, etc. It also supports other text classification scenarios, including binary-class and multi-class classification. It is built on PyTorch. Experiments show that models built in our toolkit achieve comparable performance with reported results in the literature.
Support tasks
- Binary-class text classifcation
- Multi-class text classification
- Multi-label text classification
- Hiearchical (multi-label) text classification (HMC)
Support text encoders
TextCNN (Kim, 2014)
RCNN (Lai et al., 2015)
TextRNN (Liu et al., 2016)
FastText (Joulin et al., 2016)
VDCNN (Conneau et al., 2016)
DPCNN (Johnson and Zhang, 2017)
AttentiveConvNet (Yin and Schutze, 2017)
DRNN (Wang, 2018)
Region embedding (Qiao et al., 2018)
Transformer encoder (Vaswani et al., 2017)
Star-Transformer encoder (Guo et al., 2019)
Requirement
- Python 3
- PyTorch 0.4+
- Numpy 1.14.3+
System Architecture
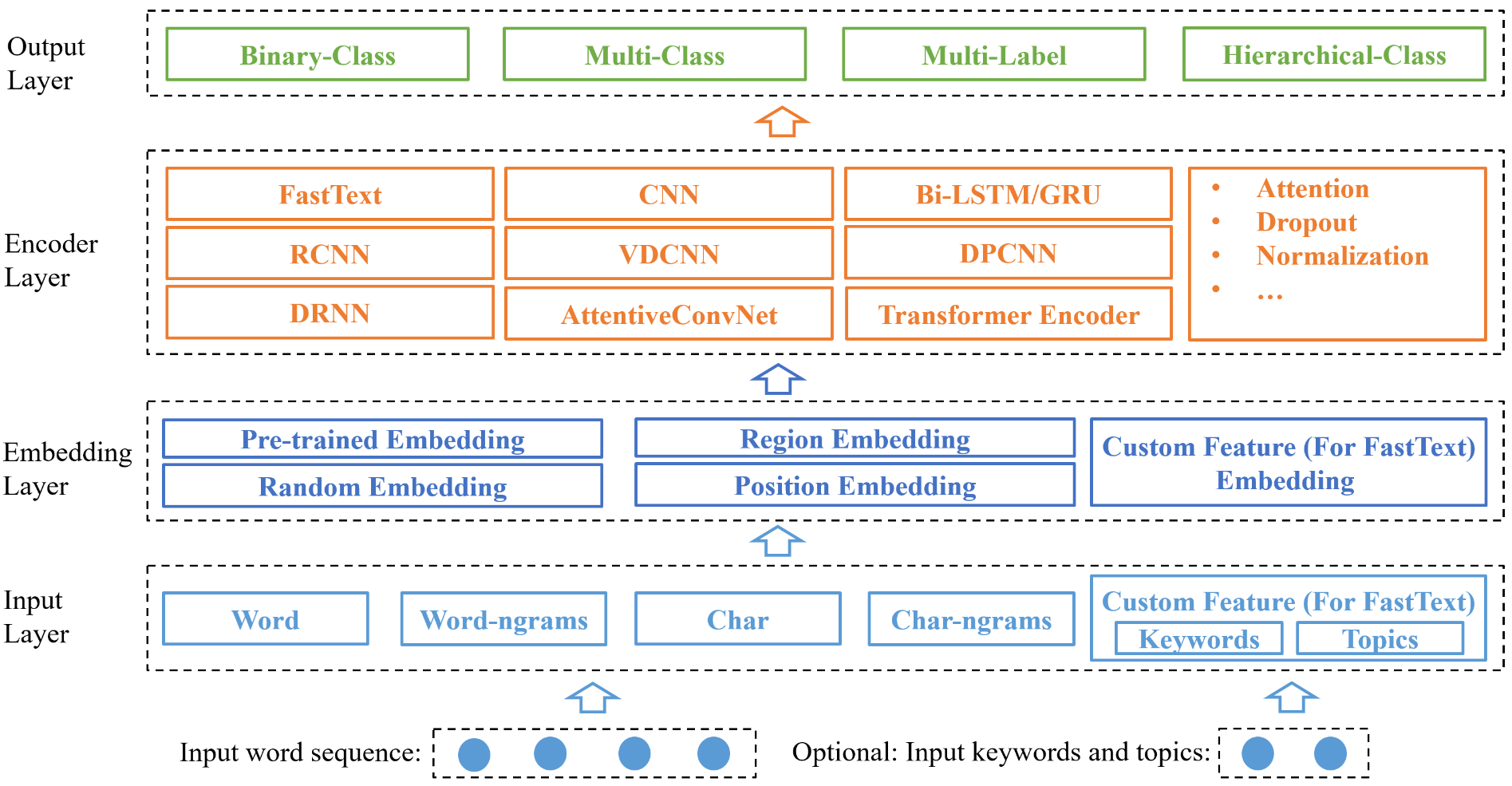
Usage
Training
python train.py conf/train.json
Detail configurations and explanations see Configuration.
The training info will be outputted in standard output and log.logger_file.
Evaluation
python eval.py conf/train.json
- if eval.is_flat = false, hierarchical evaluation will be outputted.
- eval.model_dir is the model to evaluate.
- data.test_json_files is the input text file to evaluate.
The evaluation info will be outputed in eval.dir.
Input Data Format
JSON example:
{
"doc_label": ["Computer--MachineLearning--DeepLearning", "Neuro--ComputationalNeuro"],
"doc_token": ["I", "love", "deep", "learning"],
"doc_keyword": ["deep learning"],
"doc_topic": ["AI", "Machine learning"]
}
"doc_keyword" and "doc_topic" are optional.
Performance
0. Dataset
| Dataset | Taxonomy | #Label | #Training | #Test |
|---|---|---|---|---|
| RCV1 | Tree | 103 | 23,149 | 781,265 |
| Yelp | DAG | 539 | 87,375 | 37,265 |
- RCV1: Lewis et al., 2004
- Yelp: Yelp
1. Compare with state-of-the-art
| Text Encoders | Micro-F1 on RCV1 | Micro-F1 on Yelp |
|---|---|---|
| HR-DGCNN (Peng et al., 2018) | 0.7610 | - |
| HMCN (Wehrmann et al., 2018) | 0.8080 | 0.6640 |
| Ours | 0.8313 | 0.6704 |
- HR-DGCNN: Peng et al., 2018
- HMCN: Wehrmann et al., 2018
2. Different text encoders
| Text Encoders | RCV1 | Yelp | ||
|---|---|---|---|---|
| Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | |
| TextCNN | 0.7717 | 0.5246 | 0.6281 | 0.3657 |
| TextRNN | 0.8152 | 0.5458 | 0.6704 | 0.4059 |
| RCNN | 0.8313 | 0.6047 | 0.6569 | 0.3951 |
| FastText | 0.6887 | 0.2701 | 0.6031 | 0.2323 |
| DRNN | 0.7846 | 0.5147 | 0.6579 | 0.4401 |
| DPCNN | 0.8220 | 0.5609 | 0.5671 | 0.2393 |
| VDCNN | 0.7263 | 0.3860 | 0.6395 | 0.4035 |
| AttentiveConvNet | 0.7533 | 0.4373 | 0.6367 | 0.4040 |
| RegionEmbedding | 0.7780 | 0.4888 | 0.6601 | 0.4514 |
| Transformer | 0.7603 | 0.4274 | 0.6533 | 0.4121 |
| Star-Transformer | 0.7668 | 0.4840 | 0.6482 | 0.3895 |
3. Hierarchical vs Flat
| Text Encoders | Hierarchical | Flat | ||
|---|---|---|---|---|
| Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | |
| TextCNN | 0.7717 | 0.5246 | 0.7367 | 0.4224 |
| TextRNN | 0.8152 | 0.5458 | 0.7546 | 0.4505 |
| RCNN | 0.8313 | 0.6047 | 0.7955 | 0.5123 |
| FastText | 0.6887 | 0.2701 | 0.6865 | 0.2816 |
| DRNN | 0.7846 | 0.5147 | 0.7506 | 0.4450 |
| DPCNN | 0.8220 | 0.5609 | 0.7423 | 0.4261 |
| VDCNN | 0.7263 | 0.3860 | 0.7110 | 0.3593 |
| AttentiveConvNet | 0.7533 | 0.4373 | 0.7511 | 0.4286 |
| RegionEmbedding | 0.7780 | 0.4888 | 0.7640 | 0.4617 |
| Transformer | 0.7603 | 0.4274 | 0.7602 | 0.4339 |
| Star-Transformer | 0.7668 | 0.4840 | 0.7618 | 0.4745 |




