DMControl Generalization Benchmark
Benchmark for generalization in continuous control from pixels, based on DMControl.
Also contains an official implementation of
Generalization in Reinforcement Learning by Soft Data Augmentation (SODA)
by Nicklas Hansen and Xiaolong Wang.
Test environments
This repository provides two distinct benchmarks for visual generalization, random colors and video backgrounds:

Both benchmarks are offered in easy and hard variants. Samples are shown below.
color_easy

color_hard

video_easy

video_hard

By default, algorithms are trained for 500k frames and are continuously evaluated in both training and test environments. Environment randomization is seeded to promote reproducibility.
Algorithms
This repository contains implementations of the following papers in a unified framework:
- SODA (Hansen and Wang, 2020)
- PAD (Hansen et al., 2020)
- RAD (Laskin et al., 2020)
- CURL (Srinivas et al., 2020)
- SAC (Haarnoja et al., 2018)
using standardized architecture and hyper-parameters, wherever applicable. If you want to add an algorithm, feel free to send a pull request.
Citation
If you find our work useful in your research, please consider citing the paper as follows:
@article{hansen2020softda,
title={Generalization in Reinforcement Learning by Soft Data Augmentation},
author={Nicklas Hansen and Xiaolong Wang},
year={2020},
eprint={2011.13389},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Setup
We assume that you have access to a GPU with CUDA >=9.2 support. All dependencies can then be installed with the following commands:
conda env create -f setup/conda.yml
conda activate dmcgen
sh setup/install_envs.sh
Datasets
Part of this repository relies on external datasets. SODA uses the Places dataset for data augmentation, which can be downloaded by running
wget http://data.csail.mit.edu/places/places365/places365standard_easyformat.tar
You should familiarize yourself with their terms before downloading. After downloading and extracting the data, add your dataset directory to the data_dirs list in src/augmentations.py.
The video_easy environment was proposed in PAD, and the video_hard environment uses a subset of the RealEstate10K dataset for background rendering. All test environments (including video files) are included in this repository, namely in the src/env/ directory.
Training & Evaluation
The scripts directory contains training and evaluation bash scripts for all the included algorithms. Alternatively, you can call the python scripts directly, e.g. for training call
python3 src/train.py \
--algorithm soda \
--aux_lr 3e-4 \
--seed 0
to run SODA on the default task, walker_walk. This should give you an output of the form:
Working directory: logs/walker_walk/soda/0
Evaluating: logs/walker_walk/soda/0
| eval | S: 0 | ER: 26.2285 | ERTEST: 25.3730
| train | E: 1 | S: 250 | D: 70.1 s | R: 0.0000 | ALOSS: 0.0000 | CLOSS: 0.0000 | AUXLOSS: 0.0000
where ER and ERTEST corresponds to the average return in the training and test environments, respectively. You can select the test environment used in evaluation with the --eval_mode argument, which accepts one of (train, color_easy, color_hard, video_easy, video_hard).
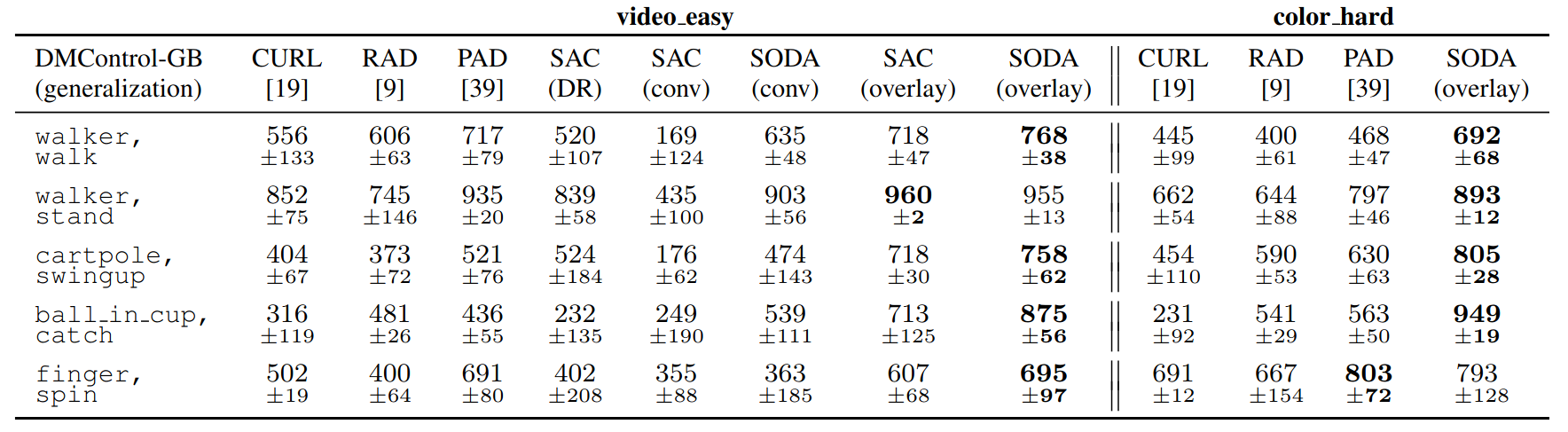
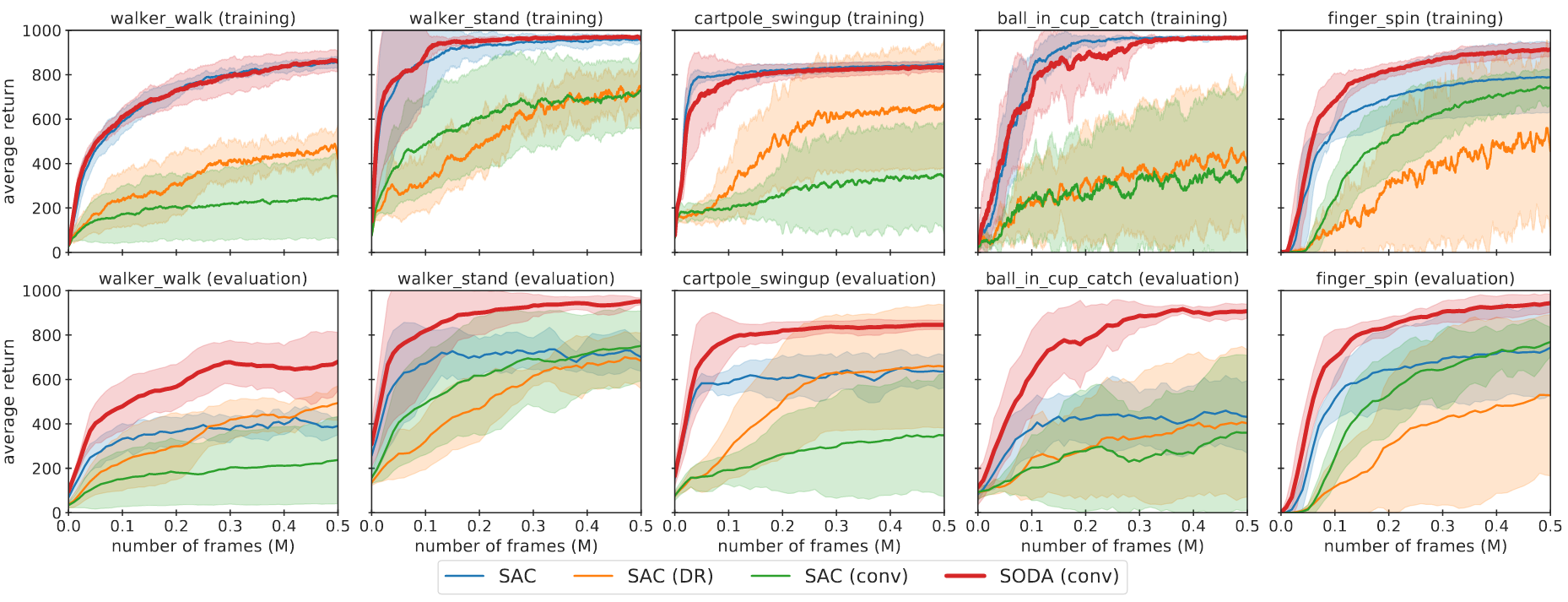
Results
SODA demonstrates significantly improved generalization over previous methods, exhibits stable training, and has a sample efficiency that is comparable to the baseline SAC. Average return of SODA and baselines in the train and color_hard environments is shown below.
We also provide a full comparison of the SODA, PAD, RAD, and CURL methods on all four test environments. Results for video_easy and color_hard are shown below: