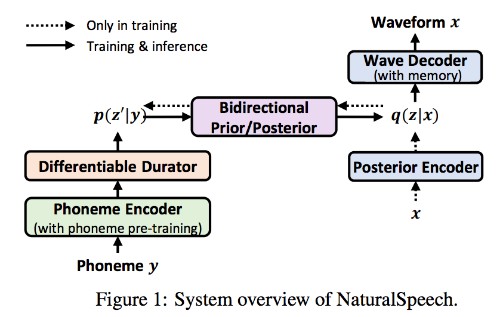
Bidirectional Variational Inference for Non-Autoregressive Text-to-Speech (BVAE-TTS)
Yoonhyung Lee, Joongbo Shin, Kyomin Jung
Abstract: Although early text-to-speech (TTS) models such as Tacotron 2 have succeeded in generating human-like speech, their autoregressive architectures have several limitations: (1) They require a lot of time to generate a mel-spectrogram consisting of hundreds of steps. (2) The autoregressive speech generation shows a lack of robustness due to its error propagation property. In this paper, we propose a novel non-autoregressive TTS model called BVAE-TTS, which eliminates the architectural limitations and generates a mel-spectrogram in parallel. BVAE-TTS adopts a bidirectional-inference variational autoencoder (BVAE) that learns hierarchical latent representations using both bottom-up and top-down paths to increase its expressiveness. To apply BVAE to TTS, we design our model to utilize text information via an attention mechanism. By using attention maps that BVAE-TTS generates, we train a duration predictor so that the model uses the predicted duration of each phoneme at inference. In experiments conducted on LJSpeech dataset, we show that our model generates a mel-spectrogram 27 times faster than Tacotron 2 with similar speech quality. Furthermore, our BVAE-TTS outperforms Glow-TTS, which is one of the state-of-the-art non-autoregressive TTS models, in terms of both speech quality and inference speed while having 58% fewer parameters. One-sentence Summary: In this paper, a novel non-autoregressive text-to-speech model based on bidirectional-inference variational autoencoder called BVAE-TTS is proposed.
Training
- Download and extract the LJ Speech dataset
- Make
preprocessedfolder in the LJSpeech directory and do preprocessing of the data usingprepare_data.ipynb - Set the
data_pathinhparams.pyto thepreprocessedfolder - Train your own BVAE-TTS model
python train.py --gpu=0 --logdir=baseline
Pre-trained models
We provide a pre-trained BVAE-TTS model, which is a model that you would obtain with the current setting (e.g. hyperparameters, dataset split). Also, we provide a pre-trained WaveGlow model that is used to obtain the audio samples. After downloading the models, you can generate audio samples using inference.ipynb.
Audio Samples
You can hear the audio samples here
Reference
1.NVIDIA/tacotron2: https://github.com/NVIDIA/tacotron2
2.NVIDIA/waveglow: https://github.com/NVIDIA/waveglow
3.pclucas/iaf-vae: https://github.com/pclucas14/iaf-vae