wdsr_ntire2018
Wide Activation for Efficient and Accurate Image Super-Resolution.
Run
- Requirements:
- Install PyTorch (tested on release 0.4.0 and 0.4.1).
- Clone EDSR-Pytorch as backbone training framework.
- Training and Validation:
- Copy wdsr_a.py, wdsr_b.py into
EDSR-PyTorch/src/model/. - Modify
EDSR-PyTorch/src/option.pyandEDSR-PyTorch/src/demo.shto support--n_feats, --block_featsoption. - Launch training with EDSR-Pytorch as backbone training framework.
- Copy wdsr_a.py, wdsr_b.py into
Overall Performance
| Network | Parameters | DIV2K (val) PSNR |
|---|---|---|
| EDSR Baseline | 1,372,318 | 34.61 |
| WDSR Baseline | 1,190,100 | 34.77 |
We measured PSNR using DIV2K 0801 ~ 0900 (trained on 0000 ~ 0800) on RGB channels without self-ensemble which is identical to EDSR baseline model settings. Both baseline models have 16 residual blocks.
More results:
| Number of Residual Blocks | 1 | 3 | ||||
|---|---|---|---|---|---|---|
| SR Network | EDSR | WDSR-A | WDSR-B | EDSR | WDSR-A | WDSR-B |
| Parameters | 2.6M | 0.8M | 0.8M | 4.1M | 2.3M | 2.3M |
| DIV2K (val) PSNR | 33.210 | 33.323 | 33.434 | 34.043 | 34.163 | 34.205 |
| Number of Residual Blocks | 5 | 8 | ||||
|---|---|---|---|---|---|---|
| SR Network | EDSR | WDSR-A | WDSR-B | EDSR | WDSR-A | WDSR-B |
| Parameters | 5.6M | 3.7M | 3.7M | 7.8M | 6.0M | 6.0M |
| DIV2K (val) PSNR | 34.284 | 34.388 | 34.409 | 34.457 | 34.541 | 34.536 |
Comparisons of EDSR and our proposed WDSR-A, WDSR-B for image bicubic x2 super-resolution on DIV2K dataset.
WDSR Network Architecture

Left: vanilla residual block in EDSR. Middle: wide activation. Right: wider activation with linear low-rank convolution. The proposed wide activation WDSR-A, WDSR-B have similar merits with MobileNet V2 but different architectures and much better PSNR.
Weight Normalization vs. Batch Normalization and No Normalization
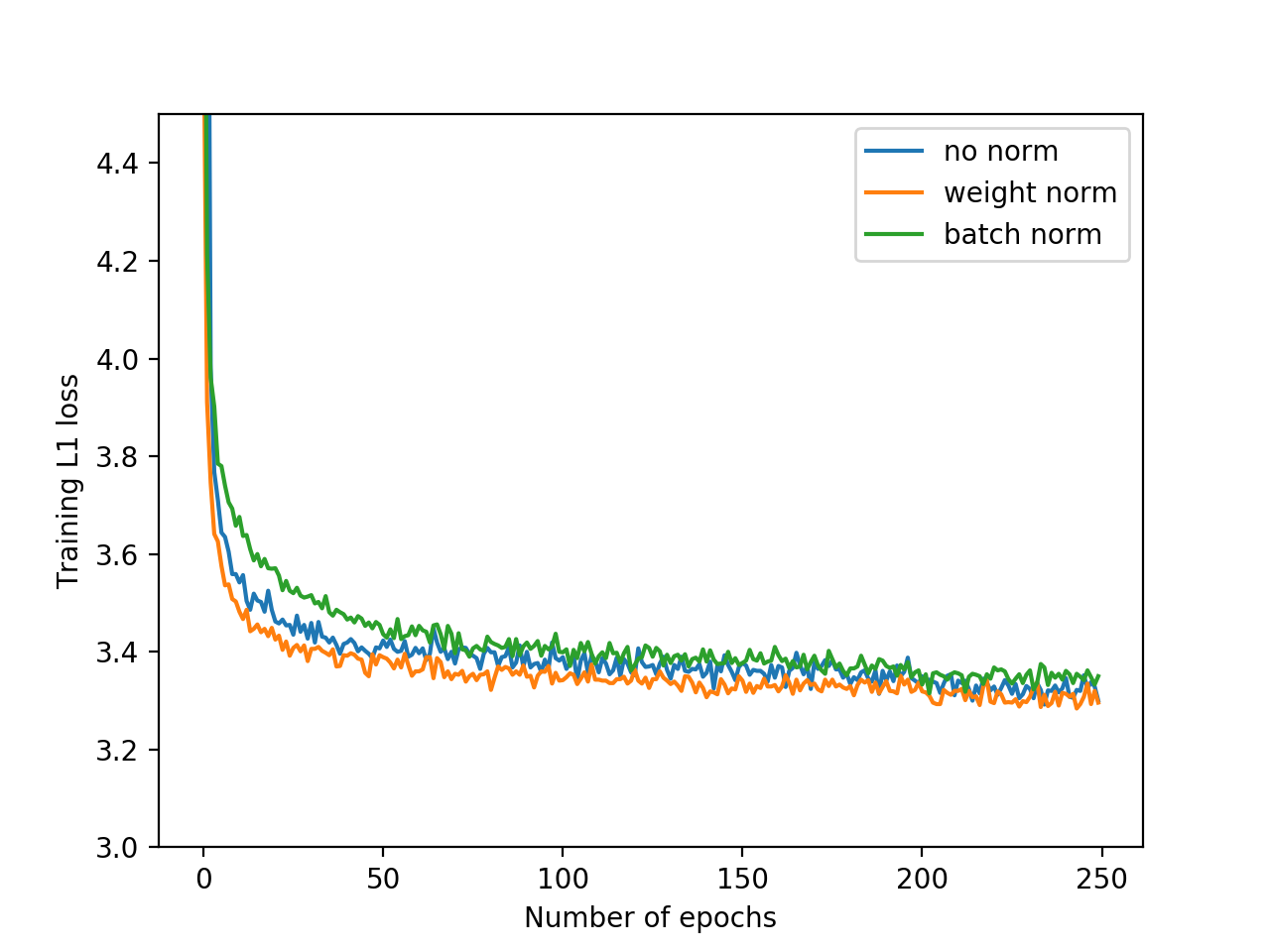
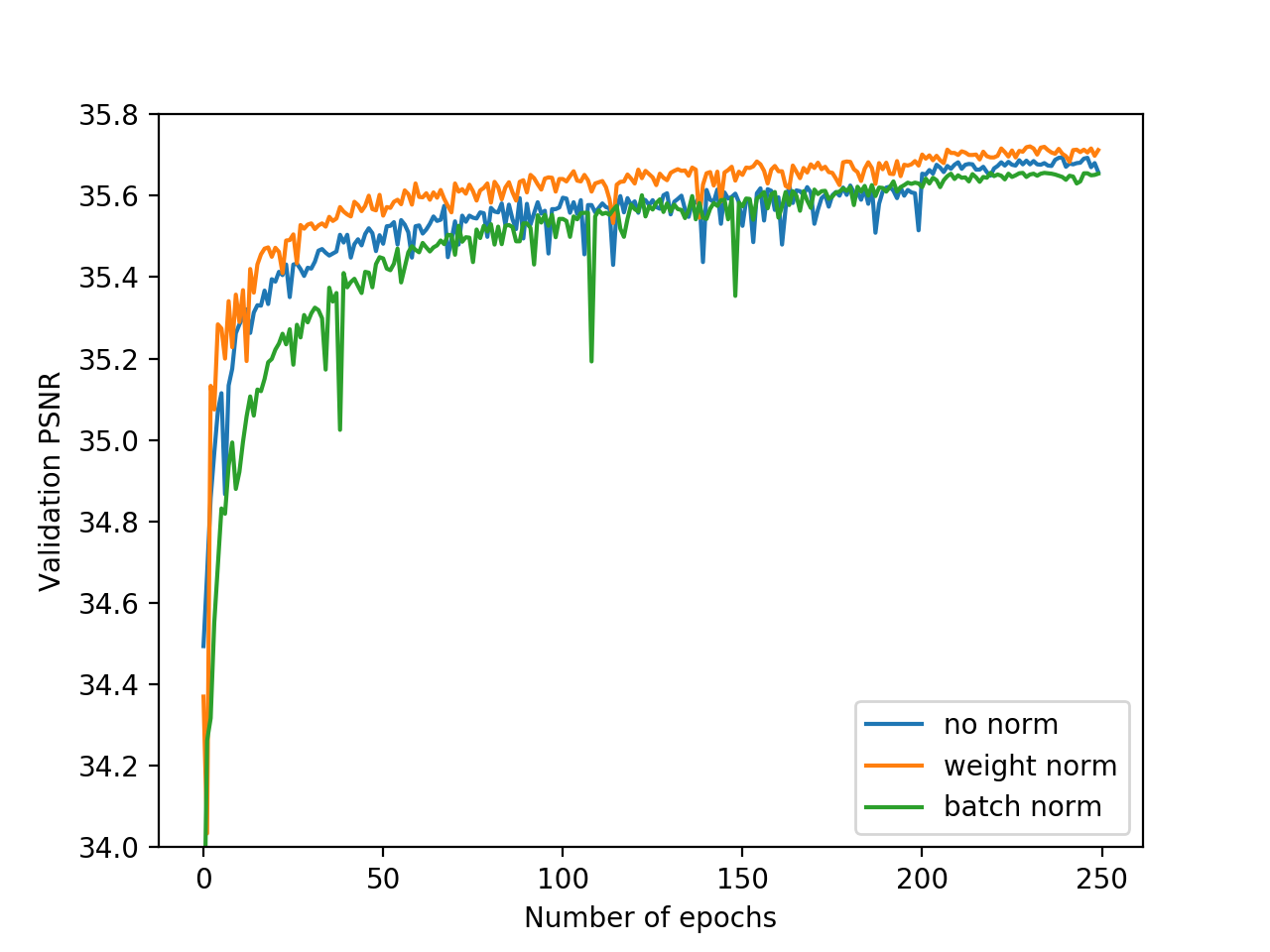
Training loss and validation PSNR with weight normalization, batch normalization or no normalization. Training with weight normalization has faster convergence and better accuracy.



