Conditional DETR
This repository is an official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.

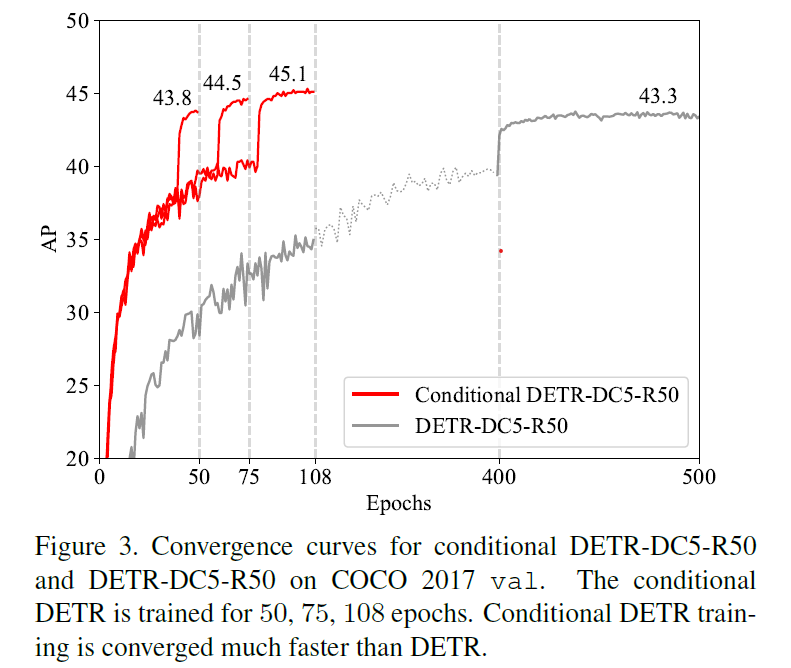
Our conditional DETR learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box (Figure 1). This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7x faster for the backbones R50 and R101 and 10x faster for stronger backbones DC5-R50 and DC5-R101.
Model Zoo
We provide conditional DETR and conditional DETR-DC5 models.
AP is computed on COCO 2017 val.
| Method | Epochs | Params (M) | FLOPs (G) | AP | APS | APM | APL | URL |
|---|---|---|---|---|---|---|---|---|
| DETR-R50 | 500 | 41 | 86 | 42.0 | 20.5 | 45.8 | 61.1 | model log |
| DETR-R50 | 50 | 41 | 86 | 34.8 | 13.9 | 37.3 | 54.4 | model log |
| DETR-DC5-R50 | 500 | 41 | 187 | 43.3 | 22.5 | 47.3 | 61.1 | model log |
| DETR-R101 | 500 | 60 | 152 | 43.5 | 21.0 | 48.0 | 61.8 | model log |
| DETR-R101 | 50 | 60 | 152 | 36.9 | 15.5 | 40.6 | 55.6 | model log |
| DETR-DC5-R101 | 500 | 60 | 253 | 44.9 | 23.7 | 49.5 | 62.3 | model log |
| Conditional DETR-R50 | 50 | 44 | 90 | 41.0 | 20.6 | 44.3 | 59.3 | model log |
| Conditional DETR-DC5-R50 | 50 | 44 | 195 | 43.7 | 23.9 | 47.6 | 60.1 | model log |
| Conditional DETR-R101 | 50 | 63 | 156 | 42.8 | 21.7 | 46.6 | 60.9 | model log |
| Conditional DETR-DC5-R101 | 50 | 63 | 262 | 45.0 | 26.1 | 48.9 | 62.8 | model log |
Note:
- The numbers in the table are slightly differently
from the numbers in the paper. We re-ran some experiments when releasing the codes. - "DC5" means removing the stride in C5 stage of ResNet and add a dilation of 2 instead.
Installation
Requirements
- Python >= 3.7, CUDA >= 10.1
- PyTorch >= 1.7.0, torchvision >= 0.6.1
- Cython, COCOAPI, scipy, termcolor
The code is developed using Python 3.8 with PyTorch 1.7.0.
First, clone the repository locally:
git clone https://github.com/Atten4Vis/ConditionalDETR.git
Then, install PyTorch and torchvision:
conda install pytorch=1.7.0 torchvision=0.6.1 cudatoolkit=10.1 -c pytorch
Install other requirements:
cd ConditionalDETR
pip install -r requirements.txt
Usage
Data preparation
Download and extract COCO 2017 train and val images with annotations from
http://cocodataset.org.
We expect the directory structure to be the following:
path/to/coco/
├── annotations/ # annotation json files
└── images/
├── train2017/ # train images
├── val2017/ # val images
└── test2017/ # test images
Training
To train conditional DETR-R50 on a single node with 8 gpus for 50 epochs run:
bash scripts/conddetr_r50_epoch50.sh
or
python -m torch.distributed.launch \
--nproc_per_node=8 \
--use_env \
main.py \
--resume auto \
--coco_path /path/to/coco \
--output_dir output/conddetr_r50_epoch50
The training process takes around 30 hours on a single machine with 8 V100 cards.
Same as DETR training setting, we train conditional DETR with AdamW setting learning rate in the transformer to 1e-4 and 1e-5 in the backbone.
Horizontal flips, scales and crops are used for augmentation.
Images are rescaled to have min size 800 and max size 1333.
The transformer is trained with dropout of 0.1, and the whole model is trained with grad clip of 0.1.
Evaluation
To evaluate conditional DETR-R50 on COCO val with 8 GPUs run:
python -m torch.distributed.launch \
--nproc_per_node=8 \
--use_env \
main.py \
--batch_size 2 \
--eval \
--resume <checkpoint.pth> \
--coco_path /path/to/coco \
--output_dir output/<output_path>
Note that numbers vary depending on batch size (number of images) per GPU.
Non-DC5 models were trained with batch size 2, and DC5 with 1,
so DC5 models show a significant drop in AP if evaluated with more
than 1 image per GPU.
Citation
@inproceedings{meng2021-CondDETR,
title = {Conditional DETR for Fast Training Convergence},
author = {Meng, Depu and Chen, Xiaokang and Fan, Zejia and Zeng, Gang and Li, Houqiang and Yuan, Yuhui and Sun, Lei and Wang, Jingdong},
booktitle = {Proceedings of the IEEE International Conference on Computer Vision (ICCV)},
year = {2021}
}






