CredData
CredData (Credential Dataset) is a set of files including credentials in open source projects.
CredData includes suspicious lines with manual review results and more information such as credential types for each suspicious line.
CredData can be used to develop new tools or improve existing tools.
Furthermore, using the benchmark result of the CredData, users can choose a proper tool among open source credential scanning tools according to their use case.
We sincerely hope that CredData will help minimize credential leaks.
How To Use
We offer the dataset for download as metadata files and script that would collect required code files based on the metadata.
To download data please use:
- Linux based OS
- Python 3.7.10 or higher version
Then run:
pip install PyYAML
python download_data.py --data_dir data
That Linux based OS is required due to NTFS filenames issue.
Some files that would be downloaded and processed have names that are
invalid in Windows/NTFS systems (such asversion->1.2.js).
Using python with lower versions may result in
OSError: [Errno 40] Too many levels of symbolic linksexception.
Resulting dataset has no invalid filenames and can be used on Windows OS.
tmpdirectory can be removed after dataset generated.
Data Overview
Data Statistics
Dataset consists of 19,459,282 lines of code extracted from 11,408 files in 297 different repositories.
Total 59,907 lines of code are labeled, of which 5,882 (9.82%) labeled as True.
Labeled data divided into 8 major categories according to their properties.
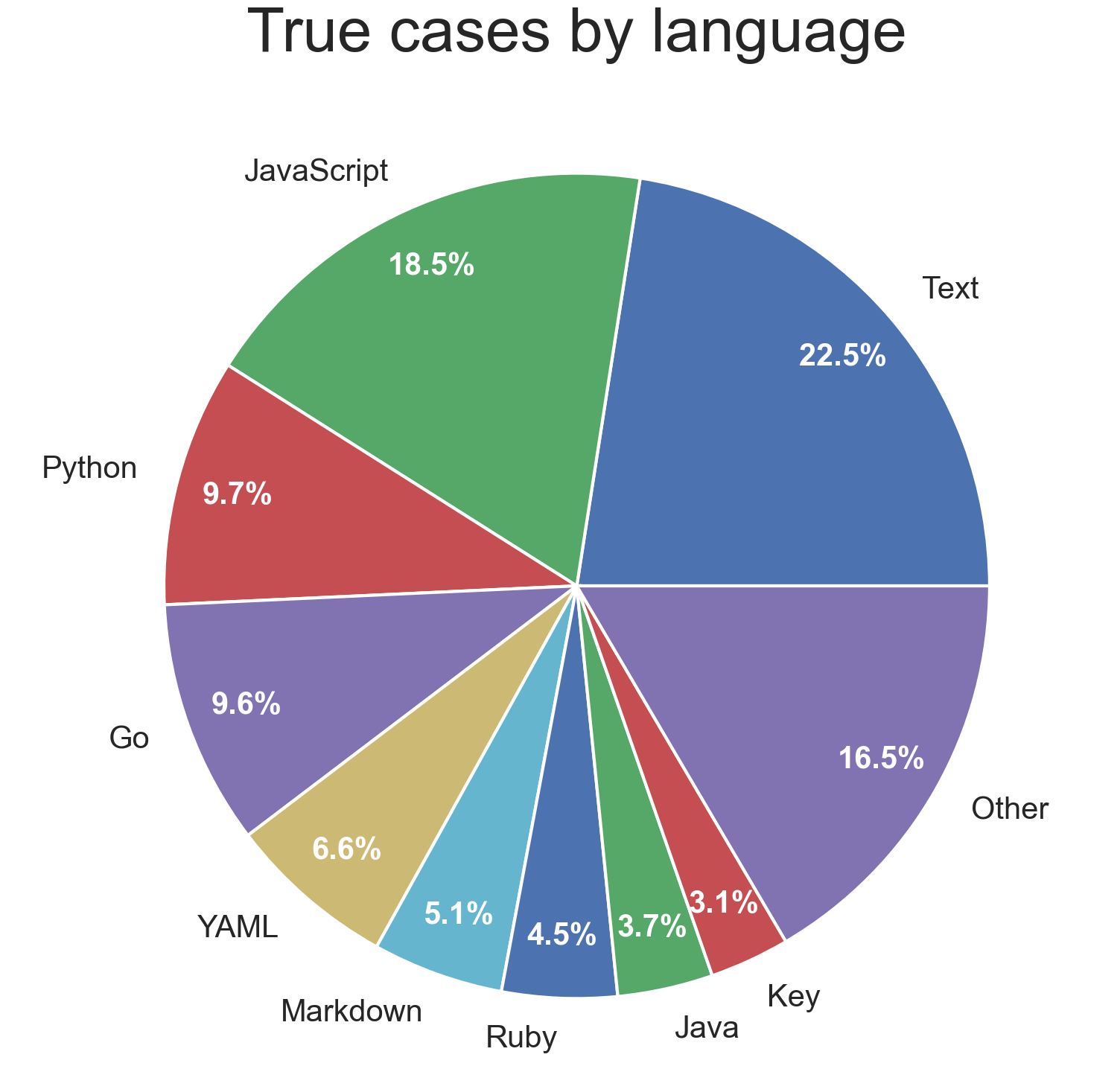
Lines of code by language
| Language | Total | Labeled | True | Language | Total | Labeled | True |
|---|---|---|---|---|---|---|---|
| Text | 85,144 | 8,718 | 1,634 | Config | 7,920 | 308 | 68 |
| JavaScript | 742,704 | 4,478 | 1,339 | No Extension | 48,645 | 991 | 55 |
| Python | 351,494 | 4,996 | 704 | Shell | 42,019 | 1,207 | 52 |
| Go | 838,816 | 5,814 | 696 | Java Properties | 1,878 | 111 | 38 |
| YAML | 74,643 | 2,521 | 479 | AsciiDoc | 27,803 | 418 | 37 |
| Markdown | 186,099 | 3,065 | 372 | XML | 57,377 | 1,312 | 30 |
| Ruby | 186,196 | 4,006 | 327 | Haskell | 5,127 | 67 | 30 |
| Java | 178,326 | 1,614 | 271 | SQLPL | 16,808 | 594 | 26 |
| Key | 8,803 | 598 | 227 | reStructuredText | 38,267 | 401 | 21 |
| PHP | 113,865 | 1,767 | 209 | Smalltalk | 92,284 | 777 | 18 |
| JSON | 15,036,863 | 9,304 | 194 | TOML | 2,566 | 235 | 17 |
| TypeScript | 151,832 | 2,357 | 155 | Objective-C | 19,840 | 115 | 14 |
| Other | 1,143,963 | 5,637 | 235 |
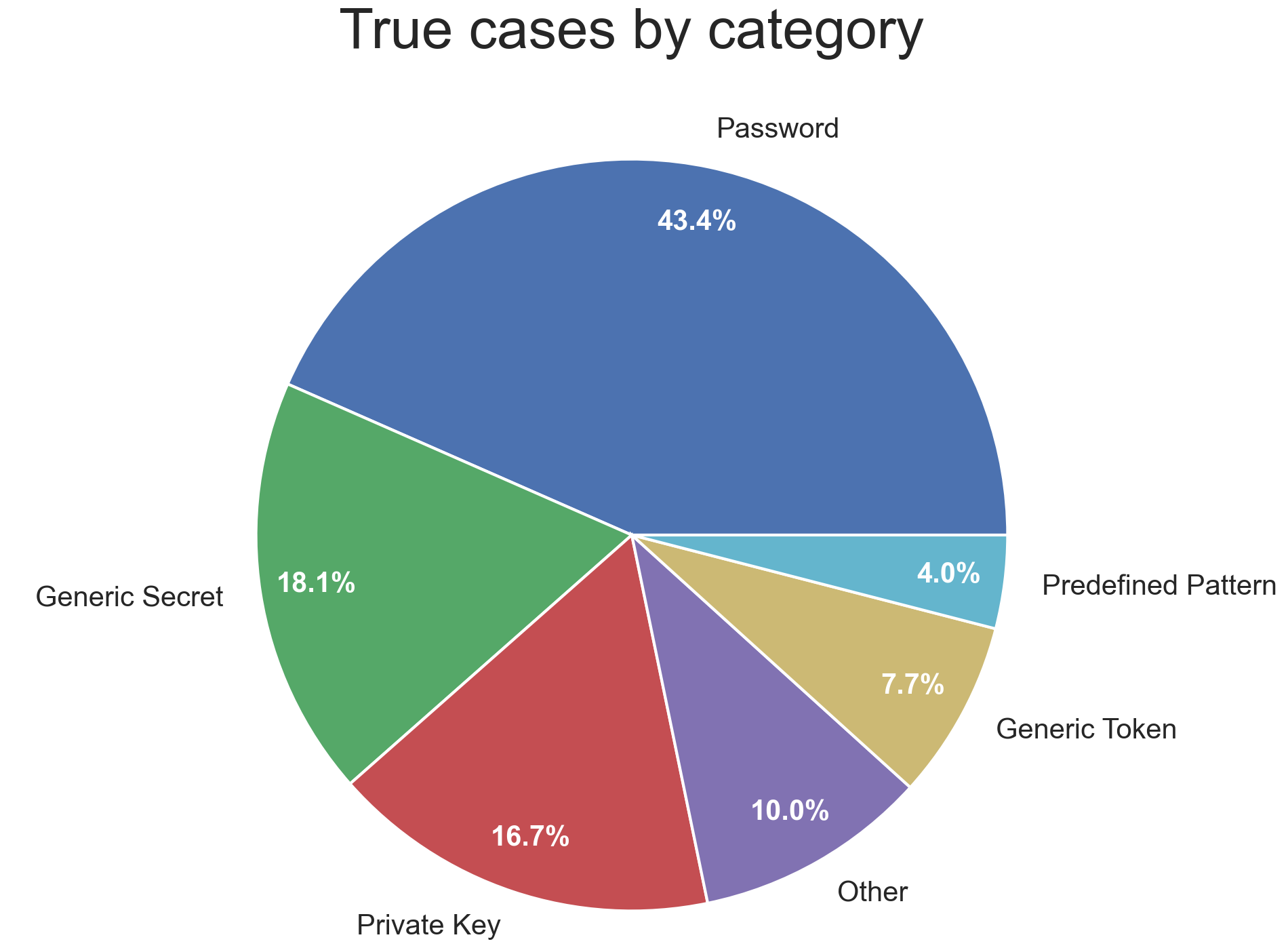
True credentials by category
| Category | True credentials |
|---|---|
| Password | 2,554 |
| Generic Secret | 1,064 |
| Private Key | 984 |
| Generic Token | 453 |
| Predefined Pattern | 236 |
| Authentication Key & Token | 47 |
| Seed, Salt, Nonce | 35 |
| Other | 509 |
Data
Selecting Target Repositories
In order to collect various cases in which credentials exist, we selected publicly accessible repositories on Github through the following process:
-
We wanted to collect credentials from repositories for various languages, frameworks, and topics, so we primarily collected 181 topics on Github.
In this process, to select widely known repositories for each topic, we limited repositories with more than a certain number of stars. 19,486 repositories were selected in this process.
-
We filtered repositories which have the license that can not be used for dataset according to the license information provided by Github.
In some cases, the provided license was inaccurate. So we conducted with manual review.
-
Filtering was carried out by checking whether strings related to the most common credentials such as 'password' and 'secret' among the result repositories are included and how many are included. After that, we executed several open source credential scanning tools.
-
For the results of No.3, we manually reviewed the detection results of all tools. Please check Ground Rules for Labeling Suspected Credential Information for the method used in the review.
As a result, we selected 297 repositories containing lines that we suspect had at least one credential value.
Ground Rules for Labeling Suspected Credential Information
It is difficult to know whether a line included in the source code is a real credential.
However, based on human cognitive abilities, we can expect the possibility that the detected result contains actual credential information.
We classify the detection results to the three credential type.
- True : It looks like a real credential value.
- False : It looks like a false positive case, not the actual credential value.
- Template : It seems that it is not an actual credential, but it is a placeholder. It might be helpful in cases such as ML.
In order to compose an accurate Ground Truth set, we proceed data review based on the following 'Ground Rules':
-
All credentials in test (example) directories should be labeled as True.
-
Credentials with obvious placeholders (
password = <YOUR_PASSWORD>;) should be labeled as Template. -
Function calls without string literals (
password=getPass();) and environmental variable assignments (password=${pass}) should be labeled as False. -
Base64 and other encoded data should be labeled as False. If it is a plaintext credential just encoded to Base64, that should be labeled as True.
-
Package and resource version hash is not a credential, so common hash string (
integrity sha512-W7s+uC5bikET2twEFg==) is False. -
Be careful about filetype when checking variable assignment:
In .yaml file row (
password=my_password) can be a credential
but in .js or .py it cannot. This languages require quotations (' or ") for string declaration (password="my_password"). -
Check if the file you are labeling is not a localization file. For example
config/locales/pt-BR.ymlis not a credentials, just a translation. So those should be labeled as False.
We could see that many credentials exist in directories/files that have the same test purpose as test/tests.
In the case of these values, people often judge that they contain a real credential, but we do not know whether this value is an actual usable credential or a value used only for testing purposes.
We classify those values as True in order to prevent the case of missing real usable credentials.
Since it may be necessary to separate the values in the future, we have separated the files for testing and the files that are not. (Check metadata or data set)
Metadata
Metadata includes Ground Truth values and additional information for credential lines detected by various tools.
Properties on the Metadata
| Name of property | Data Type | Description |
|---|---|---|
| ID | Integer | Credential ID |
| FileID | String | Filename hash. Used to download correct file from a external repo |
| Domain | String | Domain of repository. (ex. Github) |
| RepoName | String | Project name that credential was found |
| FilePath | String | File path where credential information was included |
| LineStart:LineEnd | Integer:Integer | Line information, it can be single(2:2) or multiple(ex. 2:4 means 2 to 4 inclusive) |
| GroundTruth | String | Ground Truth of this credential. True / False or Template |
| ValueStart | Integer | Index of value on the line. always nan if GroundTruth is False. |
| ValueEnd | Integer | Index of character right after value ends in the line. |
| InURL | Boolean | Flag to indicate if credential is a part of a URL, such as "http://user:[email protected]" |
| CharacterSet | String | Characters used in the credential (NumberOnly, CharOnly, Any) |
| CryptographyKey | String | Type of a key: Private or Public |
| PredefinedPattern | String | Credential with defined regex patterns (AWS token with AKIA... pattern) |
| VariableNameType | String | Categorize credentials by variable name into Secret, Key, Token, SeedSalt and Auth |
| Entropy | Float | Shanon entropy of a credential |
| WithWords | Boolean | Flag to indicate word(https://github.com/first20hours/google-10000-english) is included on the credential |
| Length | Integer | Value length, similar to ValueEnd - ValueStart |
| Base64Encode | Boolean | Is credential a base64 string? |
| HexEncode | Boolean | Is credential a hex encoded string? (like \xFF or FF 02 33) |
| URLEncode | Boolean | Is credential a url encoded string? (like one%20two) |
| Category | String | Labeled data divided into 8 major categories according to their properties. see Category. |
Category
Labeled data divided into 8 major categories according to their properties.
| Name | Description |
|---|---|
| Password | Short secret with entropy <3.5 or Password keyword in variable name |
| Generic Secret | Secret of any length with high entropy |
| Private Key | Private cryptographic key |
| Predefined Pattern | Credential detected based on defined regex, such as Google API Key/JWT/AWS Client ID |
| Seed, Salt, Nonce | Credential with seed, salt or nonce in variable name |
| Generic Token | Credential with Token in VariableNameType and not covered by other categories |
| Authentication Key & Token | Credential with Auth in VariableNameType and not covered by other categories |
| Other | Any credentials that is not covered by categories above |
Relationship between Data and Metadata
You can see metadata files in the meta directory.
A single metadata file contains rows including line location, value index and GT(GroundTruth) information about the suspect credential information for a specific repository.
Let's look at the meta/02dfa7ec.csv. file as an example.
Id,FileID,Domain,RepoName,FilePath,LineStart:LineEnd,GroundTruth,WithWords,ValueStart,ValueEnd,...
34024,61ed9af5,GitHub,02dfa7ec,data/02dfa7ec/test/n.example,83:83,True,Secret,HighEntropy,0,31,73,...
Convert the above line with only essential columns into a table format:
| ... | RepoName | FilePath | LineStart:LineEnd | GroundTruth | ... | ValueStart | ValueEnd | ... |
|---|---|---|---|---|---|---|---|---|
| ... | 02dfa7ec | data/02dfa7ec/test/n.example | 83:83 | True | ... | 31 | 73 | ... |
This line means that the credential line exists in the 83th line of the data/02dfa7ec/test/n.example file that downloaded and obfuscated output after running the download_data.py script.
You can find the n.example file in the output generated by the download_data.py script execution by referring to the above path.
When you check the 83th line of the file, you can see that the following line exists.
GITHUB_ENTERPRISE_ORG_SECRET=hfbpozfhvuwgtfosmo2imqskc73w04jf3313309829
In here, you can see the credential based on the values of ValueStart and ValueEnd in the metadata.
hfbpozfhvuwgtfosmo2imqskc73w04jf3313309829
That the corresponding value is an obfuscated value, not an actual credential value. For that part, please refer to the following Obfuscation section.
Obfuscation
If the suspicious lines are included in the dataset as it is, the credential values actually used in real may be leaked, which is not a desirable result.
To avoid such cases we proceeded:
- Credential values obfuscation in files.
- Directory & file name and directory hierarchy obfuscation.
Credential values obfuscation in files
To prevent leakage of the actual credential value in the file, we can mask the line that is supposed to be credential or change it to a random string.
However, this masking and changing to a random string can make the side effects to the detection performance of several tools.
We have applied other methods to substitute the actual credential values within the limits of ensuring the detectability of these various tools.
- Replacing the real value to a example value for a case where a fixed pattern is clear (ex. AWS Access Key)
- Replacing the entire file with credential information to a example file. (ex. X.509 Key)
- Random key generation using regex pattern from the character set of real string and length.
Directory & file name and directory hierarchy obfuscation
Even if the line suspected of having a credential in the file is obfuscated, you can easily check the original credential value and where it came from by the information of the repository (repo name, directory structure, file name).
To prevent this from happening, we obfuscated the directory structure and file names.
Files with lines suspected of being credential / detected by the tool.
It is saved in the form of data/RepoID/(src|test)/FileID.FILE_EXTENSION.
RepoID and FileID are not opened separately, but original repository information can be provided only for research purposes and the actual repository owner through separate contact.
For contact information, please refer to the How to Contact section.
License
Each file is under the existing project's license.
It may be difficult to check the license of an existing project due to obfuscation of file and directory structure, etc., but you can check the actual license through the license corresponding to the RepoID in the license directory.
Directory Structure
?CredData
┃
┣ ?benchmark
┃
┣ ?data ---- To be generated by `download_data.py`
┃ ┗ ?A
┃ ┣ ?src
┃ ┃ ┗ ?a.c ---- Source File
┃ ┃
┃ ┣ ?test
┃ ┃ ┗ ?b.c ---- Source File but in the test/tests.
┃ ┃
┃ ┣ ?other
┃ ┃ ┗ ?c ---- File has no extension or Readme
┃ ┃
┃ ┗ ?LICENSE(COPYING) ---- License File for repo A
┃
┣ ?meta
┃ ┗ ?A.csv
┃
┣ ?snapshot.yaml ---- URL and commit info for used repositories
┃
┣ ?README.md
┃
┣ ?download_data.py
┃
┗ ?CredData.pdf
Benchmark Result
A table of performance metrics for each tool tested based on CredData.
The content will be updated in detail with the release of our tool in October.
For the tools used, see the Used Tools for Benchmarking section below.
| Name | TP | FP | TN | FN | FPR | FNR | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|---|
| ours (to be released) | 4,231 | 1,592 | 52,511 | 1,771 | 0.0294 | 0.29506 | 0.7266 | 0.7049 | 0.7156 |
| detect-secrets | 2,862 | 10,467 | 44,508 | 3,140 | 0.1903 | 0.5231 | 0.2147 | 0.4768 | 0.2961 |
| gitleaks | 1,064 | 1,068 | 52,838 | 4,938 | 0.0198 | 0.8227 | 0.49906 | 0.1772 | 0.2616 |
| shhgit | 324 | 277 | 53,629 | 5,678 | 0.0051 | 0.94601 | 0.5391 | 0.0539 | 0.0981 |
| truffleHog | 1,756 | 129,343 | 41,622 | 4,246 | 0.7565 | 0.7074 | 0.0133 | 0.2925 | 0.0256 |
| credential-digger | 637 | 25,532 | 49,997 | 5,365 | 0.33804 | 0.8938 | 0.0243 | 0.1061 | 0.0396 |
| wraith(gitrob) | 1,504 | 3,062 | 52,149 | 4,498 | 0.0554 | 0.7494 | 0.3293 | 0.2505 | 0.2846 |
Used Tools for Benchmarking
| Name | URL |
|---|---|
| truffleHog | https://github.com/trufflesecurity/truffleHog |
| shhgit | https://github.com/eth0izzle/shhgit |
| wraith(gitrob) | https://gitlab.com/gitlab-com/gl-security/security-operations/gl-redteam/gitrob |
| credential-digger | https://github.com/SAP/credential-digger |
| gitLeaks | https://github.com/zricethezav/gitleaks |
| detect-secrets | https://github.com/Yelp/detect-secrets |
Citation
You can use CredData on your research.
@misc{sr-cred21,
author = {JaeKu Yun, ShinHyung Choi, YuJeong Lee, Oleksandra Sokol, WooChul Shim},
title = {Project CredData: A Dataset of Credentials for Research},
howpublished ={ \url{https://github.com/Samsung/CredData}},
year = {2021}
}
How to Get Involved
In addition to developing under an Open Source license, A use an Open Source Development approach, welcoming everyone to participate, contribute, and engage with each other through the project.
Project Roles
A recognizes the following formal roles: Contributor and Maintainer. Informally, the community may organize itself and give rights and responsibilities to the necessary people to achieve its goals.
Contributor
A Contributor is anyone who wishes to contribute to the project, at any level. Contributors are granted the following rights, to:
- Can suggest
- Change in Ground Truth for currently added/ newly added codes
- New open repository to be included
- Report defects (bugs) and suggestions for enhancement;
- Participate in the process of reviewing contributions by others;
Contributors are required to:
- Must follow below rules when updating additional credential dataset
- Additional data must be individual from the original data; they must not effect(change/remove/conflict) with the original data
- Additional data must not include valid/real credential data to prevent further exposure of the credential; they must be transformed by the obfuscation rule guided in README.md, or changed through other process which has similar obfuscation effect.
- To contribute and reflect changes, Contributors receive the approval of the maintainer.
Contributors who show dedication and skill are rewarded with additional rights and responsibilities. Their opinions weigh more when decisions are made, in a fully meritocratic fashion.
Maintainer
A Maintainer is a Contributor who is also responsible for knowing, directing and anticipating the needs of a given a Module. As such, Maintainers have the right to set the overall organization of the source code in the Module, and the right to participate in the decision-making. Maintainers are required to review the contributor’s requests and decide whether to accept or not the contributed data.
How to Contact
Please post questions, issues, or suggestions into Issues. This is the best way to communicate with the developer.




