REFILLED
This is the code of CVPR 2020 oral paper "Distilling Cross-Task Knowledge via Relationship Matching". If you use any content of this repo for your work, please cite the following bib entry:
@inproceedings{ye2020refilled,
author = {Han-Jia Ye and
Su Lu and
De-Chuan Zhan},
title = {Cross-Task Knowledge Distillation via Relationship Matching},
booktitle = {Computer Vision and Pattern Recognition (CVPR)},
year = {2020}
}
Cross-Task Knowledge Distillation
It is intuitive to take advantage of the learning experience from related pre-trained models to facilitate model training in the current task. Different from fine-tuning or parameter regularization, knowledge distillation/knowledge reuse extracts kinds of dark knowledge/privileged information from a fixed strong model (a.k.a. "teacher"), and enrich the target model (a.k.a. "student") training with more signals. Owing to the strong correspondence between classifier and class,it is difficult to reuse the classification knowledge from a cross-task teacher model.
Two-Stage Solution - REFILLED
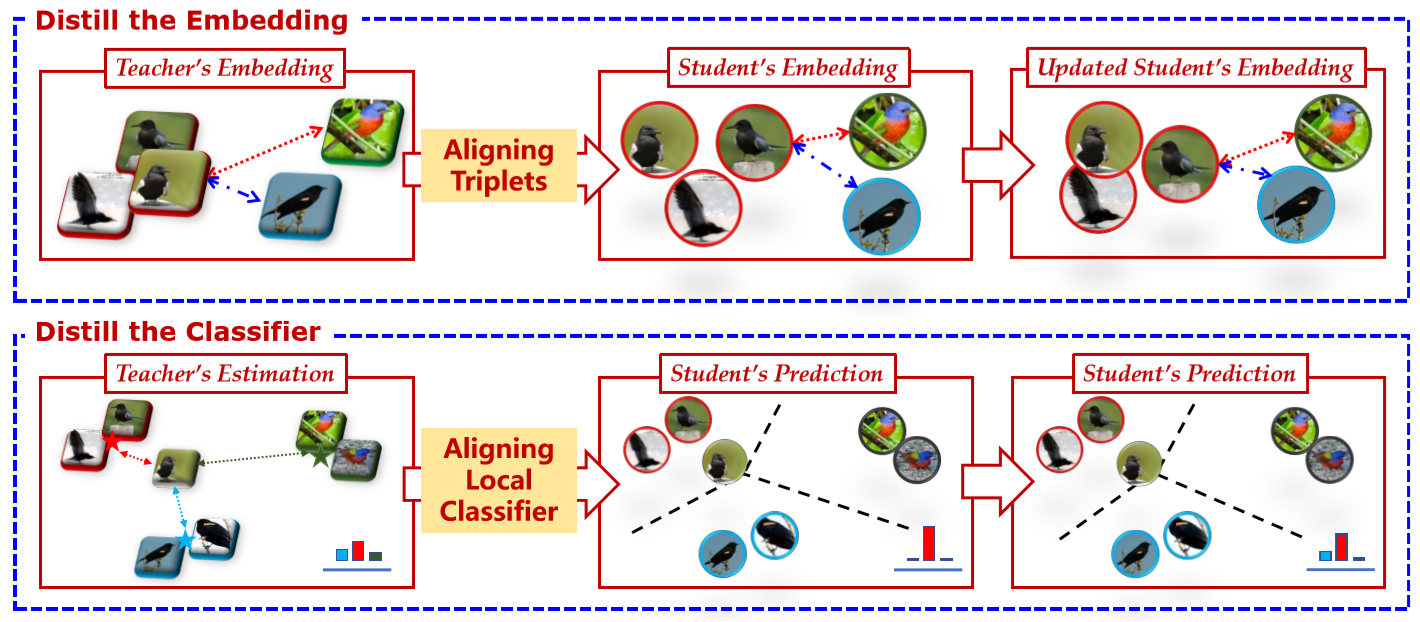
We propose the RElationship FacIlitated Local cLassifiEr Distillation (REFILLED), which decomposes the knowledge distillation flow for embedding and the top-layer classifier respectively. REFILLED contains two stages. First, the discriminative ability of features is emphasized. For those hard triplets determined by the embedding of the student model, the teacher’s comparison between them is used as the soft supervision. A teacher enhances the discriminative embedding of the student by specifying the proportion for each object how much a dissimilar impostor should be far away from a target nearest neighbor. Furthermore, the teacher constructs the soft supervision for each instance by measuring its similarity to a local center. By matching the "instance-label" predictions across models, the cross-task teacher improves the learning efficacy of the student.
Experiment Results
REFILLED can be used in several applications, e.g., standard knowledge distillation, cross-task knowledge distillation and middle-shot learning. Standard knowledge distillation is widely used and we show the results under this setting below. Experiment results of cross-task knowledge distillation and middle-shot learning can be found in the paper.
Dataset:CIFAR100 Teacher:WRN-(40-2) Student:WRN-{(40,2),(16,2),(40,1),(16,1)}
| (depth, width) | (40,2) | (16,2) | (40,1) | (16,1) |
|---|---|---|---|---|
| Teacher | 74.44 | |||
| Student | 74.44 | 70.15 | 68.97 | 65.44 |
| KD | 75.47 | 71.87 | 70.46 | 66.54 |
| FitNet | 74.29 | 70.89 | 68.66 | 65.38 |
| AT | 74.76 | 71.06 | 69.85 | 65.31 |
| NST | 74.81 | 71.19 | 68.00 | 64.95 |
| VID-I | 75.25 | 73.31 | 71.51 | 66.32 |
| KD + VID-1 | 76.11 | 73.69 | 72.16 | 67.19 |
| RKD | 76.62 | 72.56 | 72.18 | 65.22 |
| REFILLED | 77.49 | 74.01 | 72.72 | 67.56 |
Code and Arguments
This code implements REFILLED under the setting where a source task and a target task is given. main.py is the main file and the arguments it take are listed below.
data_name: name of dataset ('CIFAR100', 'CUB200'), defautl to 'CIFAR100'model_name: name of student model ('WideResNet', 'ResNet', 'MobileNet'), default to 'WideResNet'depth: depth of WideResNet and ResNet, default to 16width: width of WideResNet, default to 1ca: channel parameter of MobileNet, default to 0.25number_of_classes: just as name, default to 100dropout_rate: just as name, default to 0.3train_batch_size: just as name, default to 512validate_batch_size: just as name, default to 128test_batch_size: just as name, default to 128learning_rate_in_stage1: initial learning rate used in stage1, default to 0.1learning_rate_in_stage2: initial learning rate used in stage2, default to 0.1momentum: just as name, default to 0.9weight_decay: just as name, default to 0.0005nesterov: just as name, default to Truenumber_of_epochs_in_stage1: just as name, default to 2number_of_epochs_in_stage2: just as name, default to 2flag_gpu: a boolean variable indicating whether the model is trained on a GPU, default to Truemodel_path_stage1: where to save the model trained in stage1, default to 'saves/trained_models/ReFilled_stage1/'model_path_stage2: where to save the model trained in stage2, default to 'saves/trained_models/ReFilled_stage2/'result_path_stage1: where to save the training results in stage1, default to 'saves/results/ReFilled_stage1/'result_path_stage2: where to save the training results in stage2, default to 'saves/results/ReFilled_stage2/'teacher_model_file_path: a file containing the parameters of the well-trained teacher model, default to 'my_teacher'



