RandLA-Net
This is the official implementation of RandLA-Net (CVPR2020), a simple and efficient neural architecture for semantic segmentation of large-scale 3D point clouds. For technical details, please refer to:
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Qingyong Hu, Bo Yang*, Linhai Xie, Stefano Rosa, Yulan Guo, Zhihua Wang, Niki Trigoni, Andrew Markham.
(1) Setup
This code has been tested with Python 3.5, Tensorflow 1.11, CUDA 9.0 and cuDNN 7.4.1 on Ubuntu 16.04.
- Clone the repository
git clone https://github.com/QingyongHu/RandLA-Net && cd RandLA-Net
- Setup python environment
conda create -n randlanet python=3.5
source activate randlanet
pip install -r helper_requirements.txt
sh compile_op.sh
(2) S3DIS
S3DIS dataset can be found
here.
Download the files named "Stanford3dDataset_v1.2_Aligned_Version.zip". Uncompress the folder and move it to
/data/S3DIS.
- Preparing the dataset:
python utils/data_prepare_s3dis.py
- Start 6-fold cross validation:
sh jobs_6_fold_cv_s3dis.sh
- Move all the generated results (*.ply) in
/testfolder to/data/S3DIS/results, calculate the final mean IoU results:
python utils/6_fold_cv.py
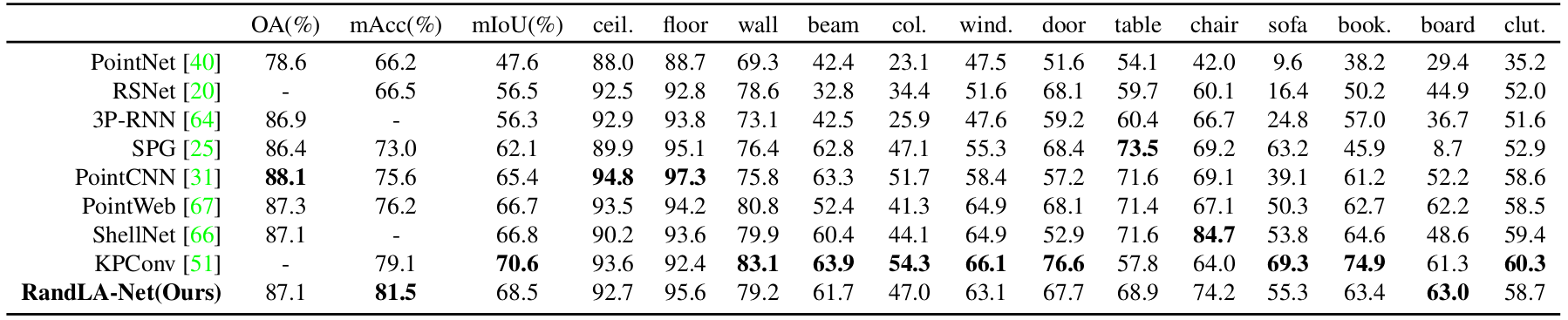
Quantitative results of different approaches on S3DIS dataset (6-fold cross-validation):
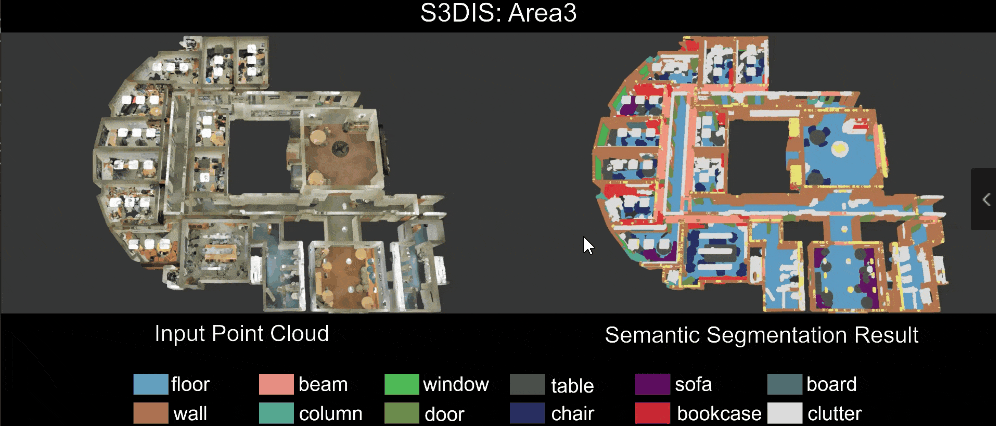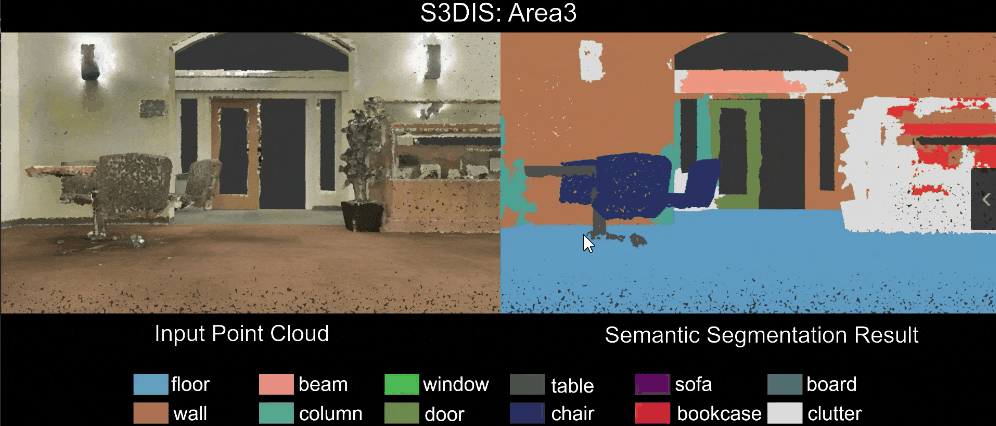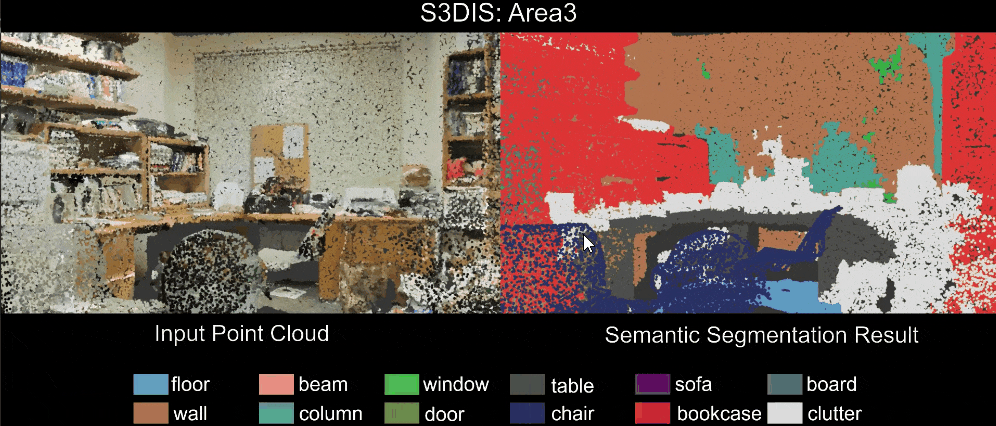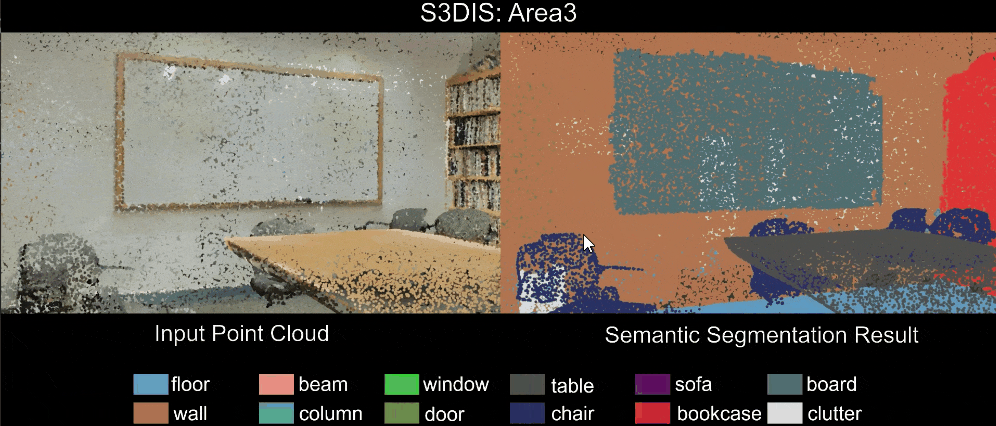
Qualitative results of our RandLA-Net:
 |
 |
|---|
(3) Semantic3D
7zip is required to uncompress the raw data in this dataset, to install p7zip:
sudo apt-get install p7zip-full
- Download and extract the dataset. First, please specify the path of the dataset by changing the
BASE_DIRin "download_semantic3d.sh"
sh utils/download_semantic3d.sh
- Preparing the dataset:
python utils/data_prepare_semantic3d.py
- Start training:
python main_Semantic3D.py --mode train --gpu 0
- Evaluation:
python main_Semantic3D.py --mode test --gpu 0
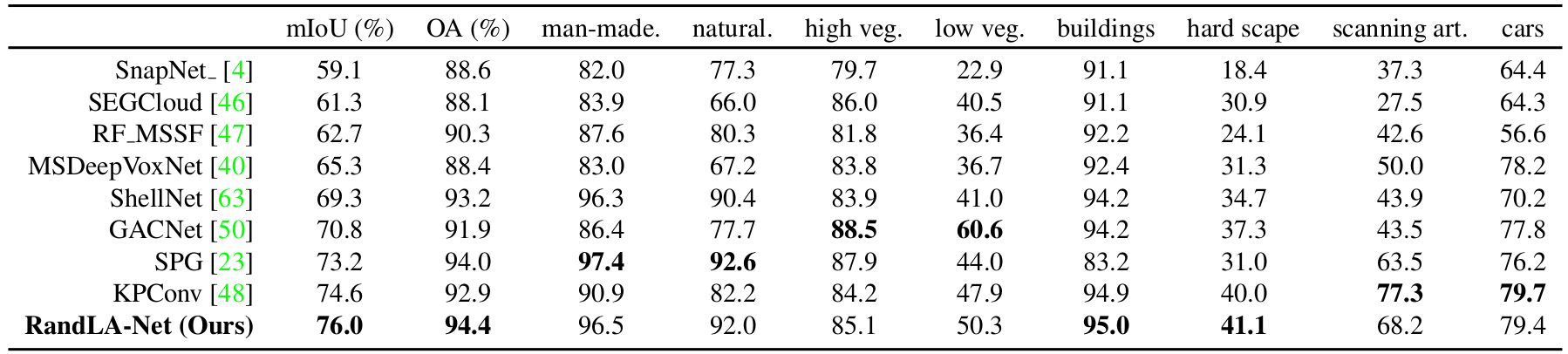
Quantitative results of different approaches on Semantic3D (reduced-8):
Qualitative results of our RandLA-Net:
 |
 |
|---|
Note:
- Preferably with more than 64G RAM to process this dataset due to the large volume of point cloud
(4) SemanticKITTI
SemanticKITTI dataset can be found here. Download the files
related to semantic segmentation and extract everything into the same folder. Uncompress the folder and move it to
/data/semantic_kitti/dataset.
- Preparing the dataset:
python utils/data_prepare_semantickitti.py
- Start training:
python main_SemanticKITTI.py --mode train --gpu 0
- Evaluation:
sh jobs_test_semantickitti.sh
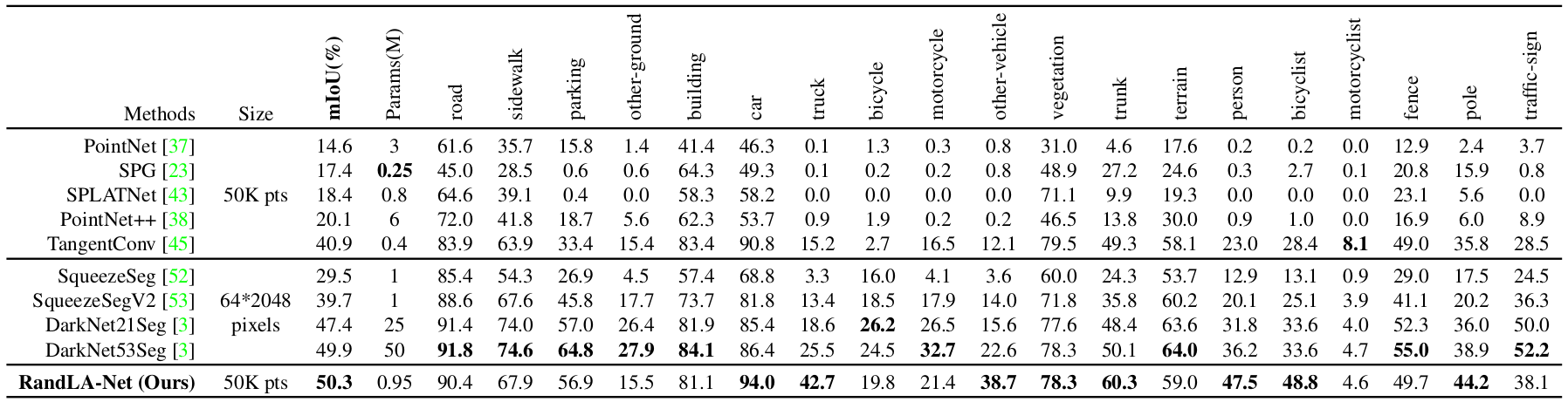
Quantitative results of different approaches on SemanticKITTI dataset:
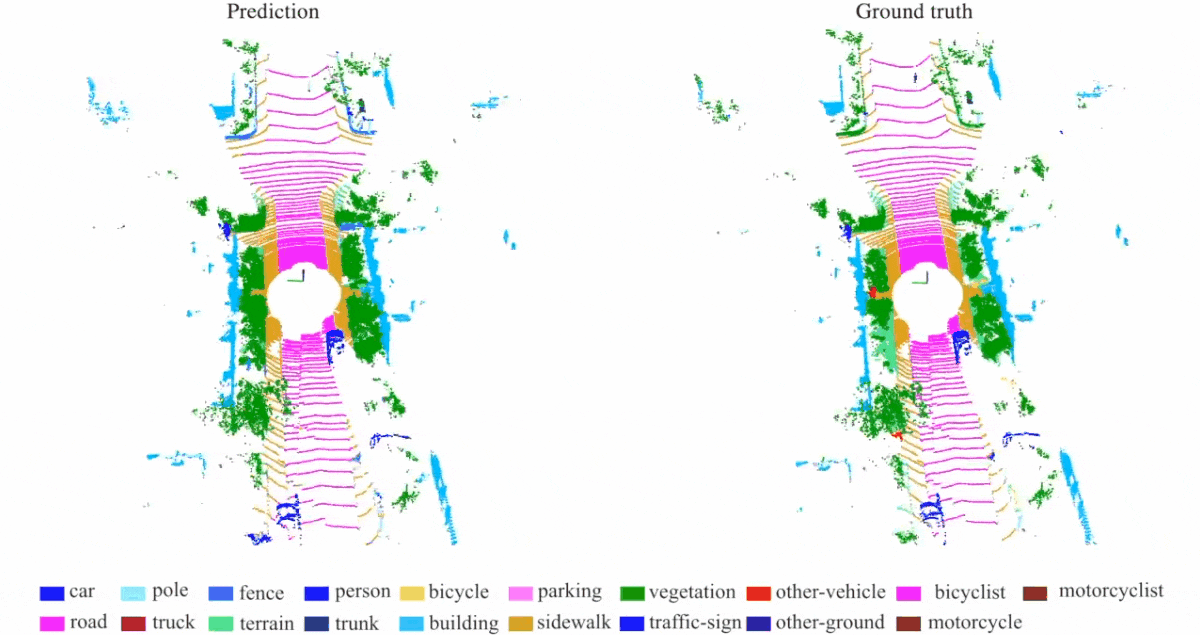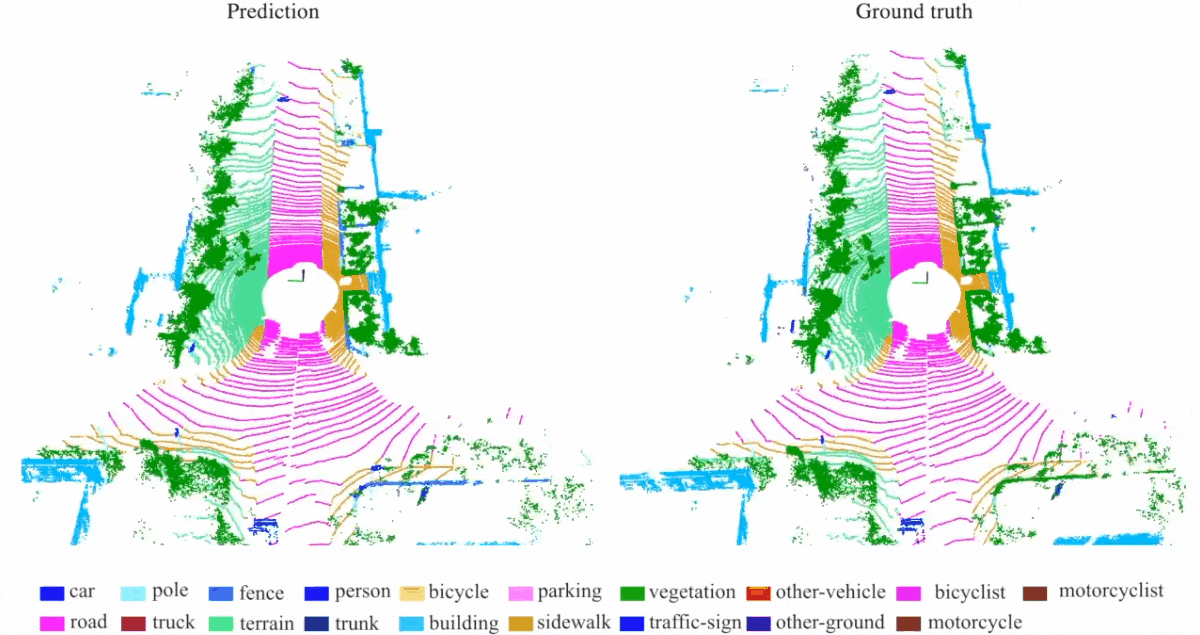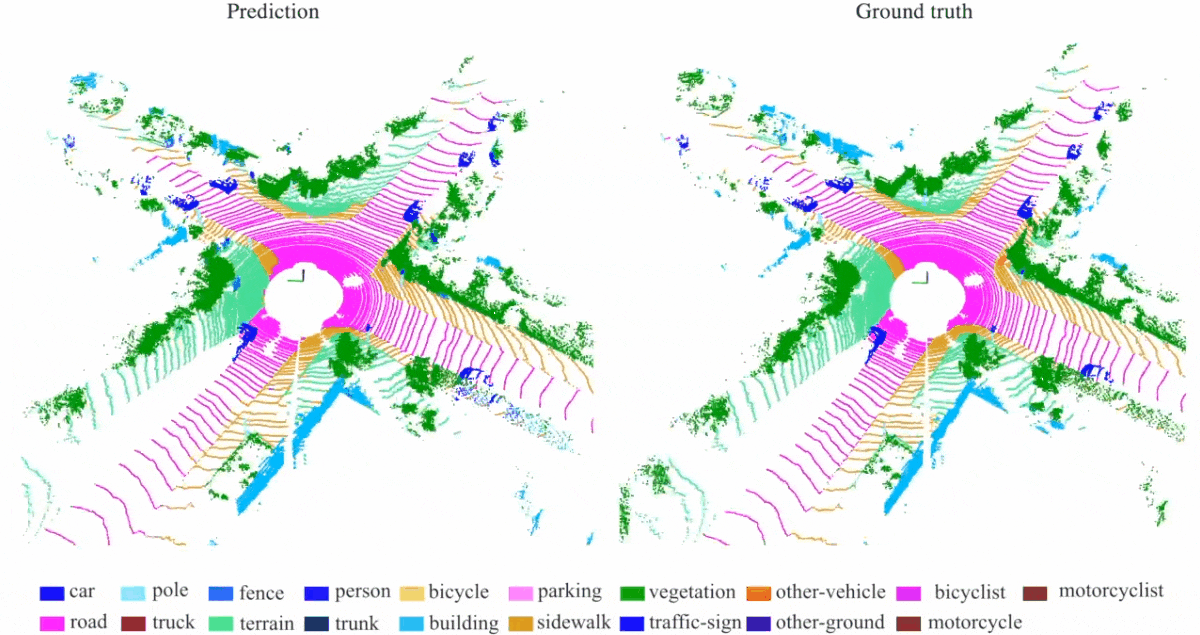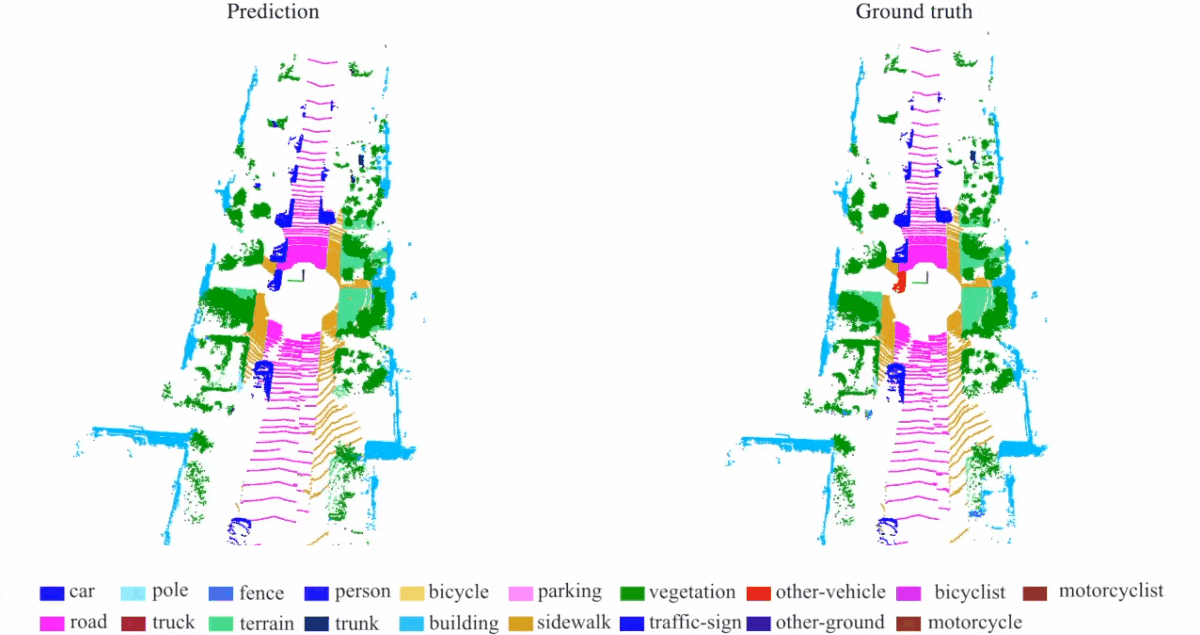
Qualitative results of our RandLA-Net:
(5) Demo
Citation
If you find our work useful in your research, please consider citing:
@article{hu2019randla,
title={RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds},
author={Hu, Qingyong and Yang, Bo and Xie, Linhai and Rosa, Stefano and Guo, Yulan and Wang, Zhihua and Trigoni, Niki and Markham, Andrew},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
Acknowledgment
- Part of our code refers to nanoflann library and the the recent work KPConv.
- We use blender to make the video demo.



