MOTR
This repository is an official implementation of the paper MOTR: End-to-End Multiple-Object Tracking with TRansformer.
Introduction
TL; DR. MOTR is a fully end-to-end multiple-object tracking framework based on Transformer. It directly outputs the tracks within the video sequences without any association procedures.
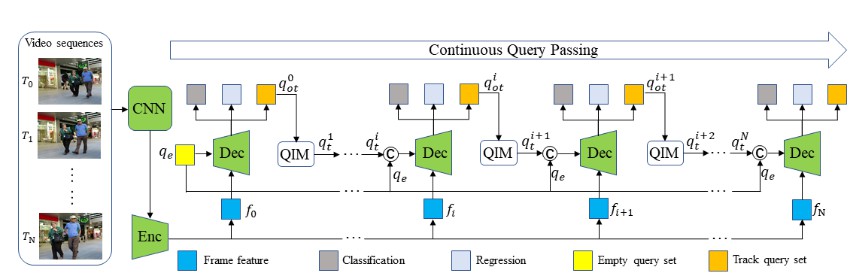
Abstract. The key challenge in multiple-object tracking (MOT) task is temporal modeling of the object under track. Existing tracking-by-detection methods adopt simple heuristics, such as spatial or appearance similarity. Such methods, in spite of their commonality, are overly simple and insufficient to model complex variations, such as tracking through occlusion. Inherently, existing methods lack the ability to learn temporal variations from data. In this paper, we present MOTR, the first fully end-to-end multiple-object tracking framework. It learns to model the long-range temporal variation of the objects. It performs temporal association implicitly and avoids previous explicit heuristics. Built on Transformer and DETR, MOTR introduces the concept of “track query”. Each track query models the entire track of an object. It is transferred and updated frame-by-frame to perform object detection and tracking, in a seamless manner. Temporal aggregation network combined with multi-frame training is proposed to model the long-range temporal relation. Experimental results show that MOTR achieves state-of-the-art performance.
Main Results
| Method | Dataset | Train Data | MOTA | IDF1 | IDS | URL |
|---|---|---|---|---|---|---|
| MOTR | MOT16 | MOT17+CrowdHuman Val | 65.8 | 67.1 | 547 | model |
| MOTR | MOT17 | MOT17+CrowdHuman Val | 66.5 | 67.0 | 1884 | model |
Note:
- All models of MOTR are trained on 8 NVIDIA Tesla V100 GPUs.
- The training time is about 2.5 days for 200 epochs;
- The inference speed is about 7.5 FPS for resolution 1536x800;
- All models of MOTR are trained with ResNet50 with pre-trained weights on COCO dataset.
Installation
The codebase is built on top of Deformable DETR.
Requirements
-
Linux, CUDA>=9.2, GCC>=5.4
-
Python>=3.7
We recommend you to use Anaconda to create a conda environment:
conda create -n deformable_detr python=3.7 pipThen, activate the environment:
conda activate deformable_detr -
PyTorch>=1.5.1, torchvision>=0.6.1 (following instructions here)
For example, if your CUDA version is 9.2, you could install pytorch and torchvision as following:
conda install pytorch=1.5.1 torchvision=0.6.1 cudatoolkit=9.2 -c pytorch -
Other requirements
pip install -r requirements.txt -
Build MultiScaleDeformableAttention
cd ./models/ops sh ./make.sh
Usage
Dataset preparation
Please download MOT17 dataset and CrowdHuman dataset and organize them like FairMOT as following:
.
├── crowdhuman
│ ├── images
│ └── labels_with_ids
├── MOT15
│ ├── images
│ ├── labels_with_ids
│ ├── test
│ └── train
├── MOT17
│ ├── images
│ ├── labels_with_ids
Training and Evaluation
Training on single node
You can download COCO pretrained weights from Deformable DETR. Then training MOTR on 8 GPUs as following:
sh configs/r50_motr_train.sh
Evaluation on MOT15
You can download the pretrained model of MOTR (the link is in "Main Results" session), then run following command to evaluate it on MOT15 train dataset:
sh configs/r50_motr_eval.sh
For visual in demo video, you can enable 'vis=True' in eval.py like:
det.detect(vis=True)
Evaluation on MOT17
You can download the pretrained model of MOTR (the link is in "Main Results" session), then run following command to evaluate it on MOT17 test dataset (submit to server):
sh configs/r50_motr_submit.sh
Citing MOTR
If you find MOTR useful in your research, please consider citing:
@article{zeng2021motr,
title={MOTR: End-to-End Multiple-Object Tracking with TRansformer},
author={Zeng, Fangao and Dong, Bin and Wang, Tiancai and Chen, Cheng and Zhang, Xiangyu and Wei, Yichen},
journal={arXiv preprint arXiv:2105.03247},
year={2021}
}








