Automatic Summarization of Resumes with NER
Shameless plugin: We are a data annotation platform to make it super easy for you to build ML datasets. Just upload data, invite your team and build datasets super quick.
This blog speaks about a field in Natural language Processing and Information Retrieval called Named Entity Recognition and how we can apply it for automatically generating summaries of resumes by extracting only chief entities like name, education background, skills, etc..
It is often observed that resumes may be populated with excess information, often irrelevant to what the evaluator is looking for in it. Therefore, the process of evaluation of resumes in bulk often becomes tedious and hectic. Through our NER model, we could facilitate evaluation of resumes at a quick glance, thereby simplifying the effort required in shortlisting candidates among a pile of resumes.
What is Named Entity Recognition?
Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a sub-task of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
NER systems have been created that use linguistic grammar-based techniques as well as statistical models such as machine learning. Hand-crafted grammar-based systems typically obtain better precision, but at the cost of lower recall and months of work by experienced computational linguists . Statistical NER systems typically require a large amount of manually annotated training data. Semisupervised approaches have been suggested to avoid part of the annotation effort
NER For Resume Summarization
Dataset :
The first task at hand of course is to create manually annotated training data to train the model. For this purpose, 220 resumes were downloaded from an online jobs platform. These documents were uploaded to our online annotation tool and manually annotated.
The tool automatically parses the documents and allows for us to create annotations of important entities we are interested in and generates json formatted training data with each line containing the text corpus along with the annotations.
A snapshot of the dataset can be seen below :
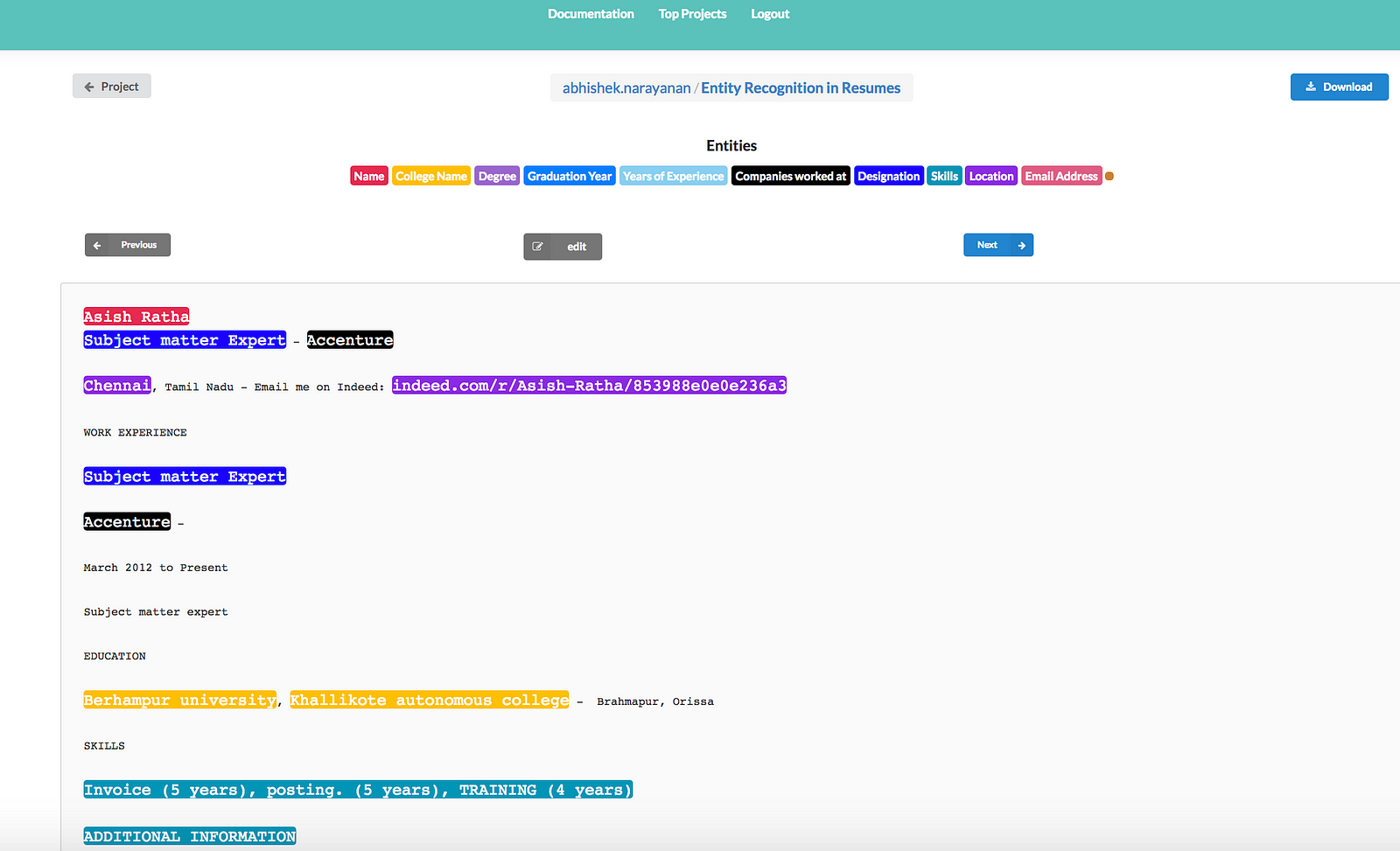
A sample of the generated json formatted data is as follows :

The above dataset consisting of 220 annotated resumes can be found
[here](https://dataturks.com/projects/abhishek.narayanan/Entity Recognition in
Resumes). We train the model with 200 resume data and test it on 20 resume data.
Training the Model :
We use python’s spaCy module for training the NER model. spaCy’s models are
statistical and every “decision” they make — for example, which
part-of-speech tag to assign, or whether a word is a named entity — is a
prediction. This prediction is based on the examples the model has seen
during training.
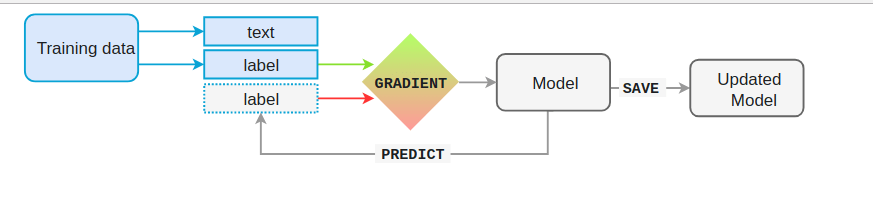
The model is then shown the unlabelled text and will make a prediction. Because
we know the correct answer, we can give the model feedback on its prediction in
the form of an error gradient of the loss function that calculates the
difference between the training example and the expected output. The greater the
difference, the more significant the gradient and the updates to our model.
When training a model, we don’t just want it to memorise our examples — we want
it to come up with theory that can be generalised across other examples.
After all, we don’t just want the model to learn that this one instance of
“Amazon” right here is a company — we want it to learn that “Amazon”, in
contexts like this, is most likely a company. In order to tune the accuracy,
we process our training examples in batches, and experiment with minibatch
sizes and dropout rates.
Of course, it’s not enough to only show a model a single example once.
Especially if you only have few examples, you’ll want to train for a number of
iterations. At each iteration, the training data is shuffled to ensure the
model doesn’t make any generalisations based on the order of examples.
Another technique to improve the learning results is to set a dropout rate,
a rate at which to randomly “drop” individual features and representations. This
makes it harder for the model to memorise the training data. For example, a
0.25dropout means that each feature or internal representation has a 1/4
likelihood of being dropped. We train the model for 10 epochs and keep the
dropout rate as 0.2.
Results and Evaluation of the model :
The model is tested on 20 resumes and the predicted summarized resumes are
stored as separate .txt files for each resume.
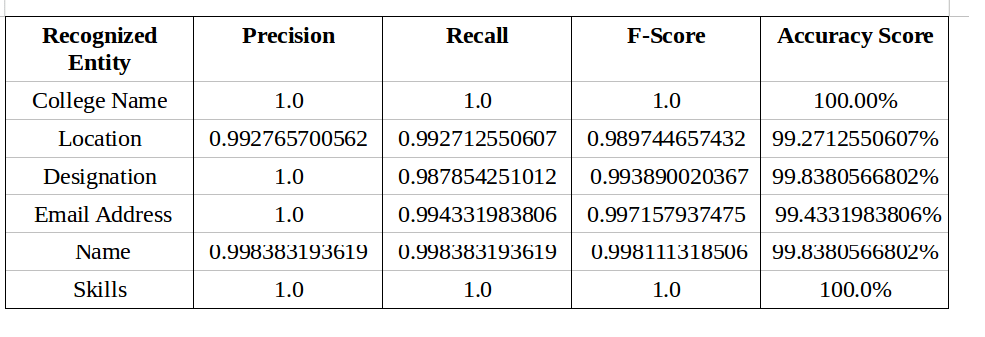
For each resume on which the model is tested, we calculate the accuracy score,
precision, recall and f-score for each entity that the model recognizes. The
values of these metrics for each entity are summed up and averaged to generate
an overall score to evaluate the model on the test data consisting of 20
resumes. The entity wise evaluation results can be observed below . It is
observed that the results obtained have been predicted with a commendable
accuracy.
A sample summary of an unseen resume of an employee from indeed.com obtained by
prediction by our model is shown below :



Resume of an Employee of Microsoft from indeed.com

Summary of the above Resume
If you have any queries or suggestions, I would love to hear about it. Please
write to me at [email protected].




