Object Detection on Taiwanese Traffic using YOLOv4 Tiny
In this project, we trained and fine-tuned the YOLOv4 Tiny model on a custom dataset of Taiwanese traffic provided by the Embedded Deep Learning Object Detection Model Compression Competition for Traffic in Asian Countries as training data.
Released in April 2020 by AlexeyAB and his team, respectively, YOLOv4 became one of the fastest object recognition system on the market. It was even deployed as real-time object detection systems as a solution to traffic flow problems in Taiwanese cities such as Taoyuan City and in Hsinchu City.
The project explores the capability of YOLOv4 Tiny, the lightweight version of YOLOv4 developed by the same research team. Moreover, as there has been little publicly available object detection datasets on Taiwanese and Asian traffic (where large numbers of scooters and bicycles are present compared to most Western countries), we took the chance to utilize the dataset provided by Embedded Deep Learning Object Detection Model Compression Competition for Traffic in Asian Countries.
We achieved an 87.2% [email protected] at about 18-23 average FPS with Nvidia Tesla P100 GPU.
DISCLAIMER: This project is an application, not an implementation/modification, of YOLOv4 Tiny. Most of the code is from the original YOLOv4 repository.
Framework and Model
Both YOLOv4 and YOLOv4 Tiny are implemented by AlexeyAB and his team, based on the
forked repository from Joseph Redmon's
original work on YOLOv1, YOLOv2, and YOLOv3. While there are many implementations
of the models in other frameworks such as Tensorflow and PyTorch, we decided to familiarize ourselves with the original
Darknet framework.
Visit the original Darknet repo to learn more about the models themselves as well
as implementations in other frameworks.
Dataset
The dataset consists of 89002 images of size 1920*1080. There are 4 annotated classes: vehicle, scooter,
pedestrian, bicycle. All the images are provided with annotations as training data for the participants of the
Embedded Deep Learning Object Detection Model Compression Competition for Traffic in Asian Countries. We used 80% of
it as training data and 20% as validation (and test) data.
Mandated by the host of the competition, the data is kept confidential. However, we do provide the weights trained and
demonstrations of the model's performance as provided below.
Results
Setting the model resolution 1280*704, we were able to achieve an 87.2% [email protected] at 18-23 FPS on average.
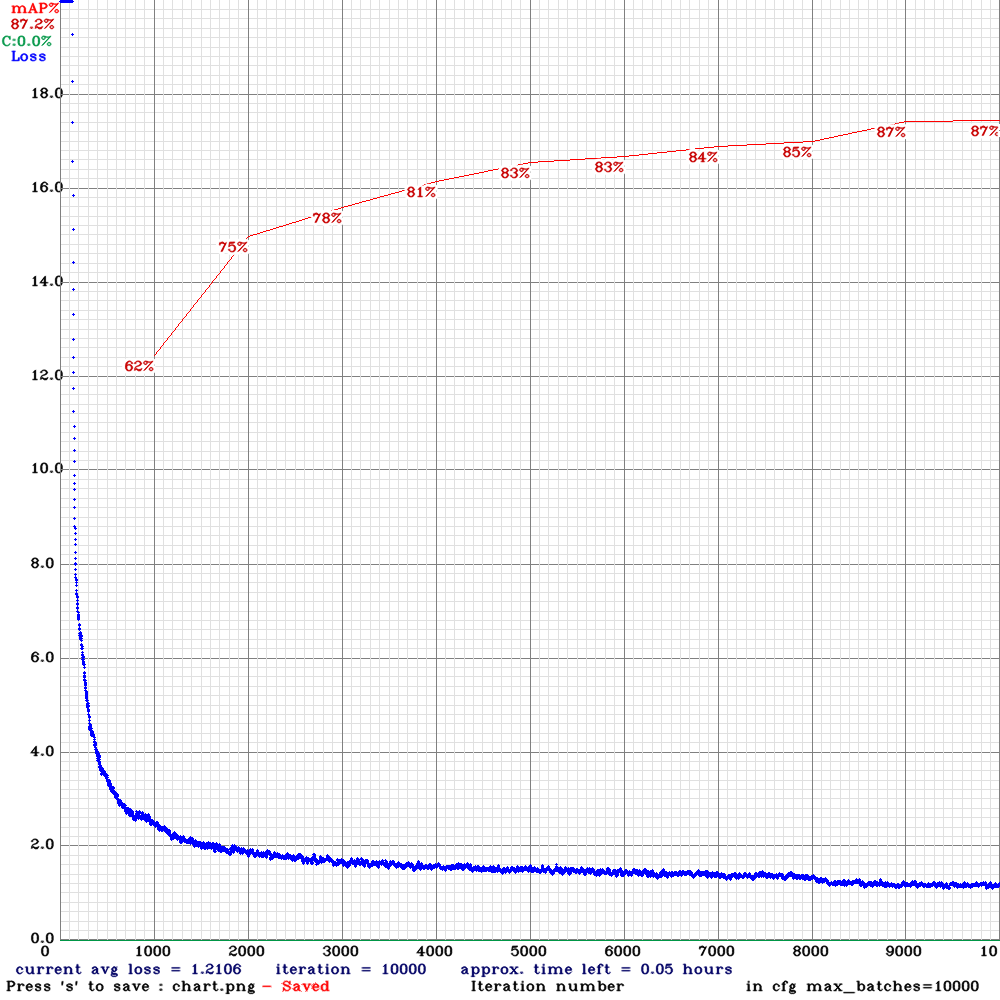
On the validation data:
detections_count = 435135, unique_truth_count = 147062
class_id = 0, name = vehicle, ap = 91.48% (TP = 86140, FP = 8549)
class_id = 1, name = scooter, ap = 88.69% (TP = 25877, FP = 2760)
class_id = 2, name = pedestrian, ap = 84.81% (TP = 11759, FP = 1900)
class_id = 3, name = bicycle, ap = 83.77% (TP = 1542, FP = 241)
for conf_thresh = 0.25, precision = 0.90, recall = 0.85, F1-score = 0.88
for conf_thresh = 0.25, TP = 125318, FP = 13450, FN = 21744, average IoU = 76.20 %
Setup
- Open your terminal,
cdinto where you'd like to clone this project, and clone the project:
$ git clone https://github.com/achen353/Taiwan-Traffic-Object-Detection.git
- Follow the steps in this article.
It has very detailed instructions of setting up the environment for training YOLO models.
Note: Make sure your CUDA, cuDNN, CUDA driver and your hardware are compatible. Check compatibility here.
It is highly suggested that you run YOLO with a GPU. If you don't have a GPU, you can use the following free resources
Google provides:
- In the US: You can run on Google Colab with free Tesla K80 GPU. Check out these tutorials:
- Outside the US: If you've never used Google Cloud Platform, you can start a free-trial with $300 credits. Some
articles are helpful in setting up your own deep learning VM instance:
If you're training on a remote server via SSH session, this article
will help you in keeping the terminal session alive even if you disconnect the SSH session.
How to Run
To train your own model on a custom dataset
The original repository has very
detailed steps for training on a custom dataset
To inference using the pre-trained model provided by this project
- Get any
.avi/.mp4video file (preferably not more than 1920*1080 to avoid bottlenecks in CPU performance) and
place them in where you prefer (we hadsample_videosfolder for this). - Run
makeif you haven't and run (assume the file name istest.mp4):
$ ./darknet detector demo data/obj.data cfg/yolov4-tiny-obj.cfg yolov4-tiny-obj_best.weights sample_videos/test.mp4 -out_filename predictions/test.mp4
We have prediction folder made to keep the prediction outputs. If you don't want the video to pop up as the model
makes inferences, add -dont_show flag in your command.


