Simpler is Better
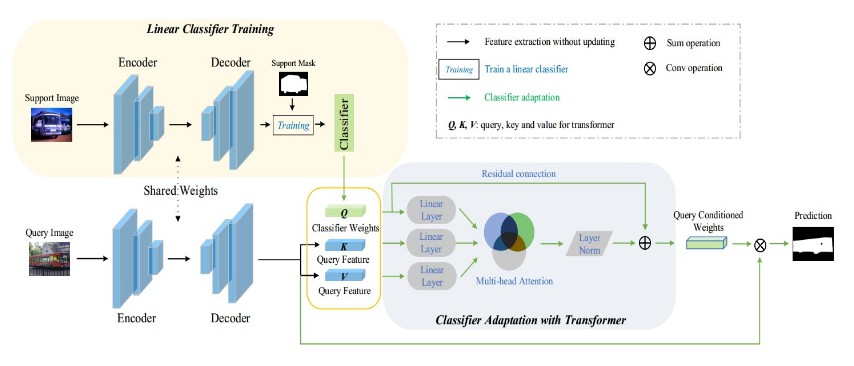
We proposed a novel model training paradigm for few-shot semantic segmentation. Instead of meta-learning the whole, complex segmentation model, we focus on the simplest classifier part to make new-class adaptation more tractable. Also, a novel meta-learning algorithm that leverages a Classifier Weight Transformer (CWT) for adapting dynamically the classifier weights to every query sample is introduced to eliminate the impact of intra-class discripency.
Architecture
Environment
Other configurations can also work, but the results may be slightly different.
- torch==1.6.0
- numpy==1.19.1
- cv2==4.4.0
- pyyaml==5.3.1
Dataset
We follow the same rule to download and process dataset as that in https://github.com/Jia-Research-Lab/PFENet. After processing, please change the "data_root" and "train/val_list" in config files accordingly.
Pre-trained models in the first stage
For convenience, we provide the pre-trained models on base classes for each split. Download it here: https://drive.google.com/file/d/1yHUNI1iTwF5U_HqCQ4kF6ti8lepcrBBY/view?usp=sharing, and change "resume_weights" to this folder.
Episodic training and inference
- The general training script
sh scripts/train.sh {data} {split} {[gpu_ids]} {layers} {shots}
- This is an example with 1-shot, ResNet-50, split-0 on PASCAL and GPU device [0].
sh scripts/train.sh pascal 0 [0] 50 1
- Inference script
sh scripts/test.sh {data} {shot} {[gpu_ids]} {layers} {split}
Contact
Please write down issues or contact me via zhihe.lu [at] surrey.ac.uk if you have any questions.
Citation
If you feel helpful of this work, please cite it. Will update this when it is officially published on ICCV.
@misc{lu2021simpler,
title={Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer},
author={Zhihe lu and Sen He and Xiatian Zhu and Li Zhang and Yi-Zhe Song and Tao Xiang},
year={2021},
eprint={2108.03032},
archivePrefix={arXiv},
primaryClass={cs.CV}
}







