MixHop and N-GCN
A PyTorch implementation of "MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing" (ICML 2019) and "A Higher-Order Graph Convolutional Layer" (NeurIPS 2018).
Abstract
Recent methods generalize convolutional layers from Euclidean domains to graph-structured data by approximating the eigenbasis of the graph Laplacian. The computationally-efficient and broadly-used Graph ConvNet of Kipf & Welling, over-simplifies the approximation, effectively rendering graph convolution as a neighborhood-averaging operator. This simplification restricts the model from learning delta operators, the very premise of the graph Laplacian. In this work, we propose a new Graph Convolutional layer which mixes multiple powers of the adjacency matrix, allowing it to learn delta operators. Our layer exhibits the same memory footprint and computational complexity as a GCN. We illustrate the strength of our proposed layer on both synthetic graph datasets, and on several real-world citation graphs, setting the record state-of-the-art on Pubmed.
This repository provides a PyTorch implementation of MixHop and N-GCN as described in the papers:
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Hrayr Harutyunyan, Nazanin Alipourfard, Kristina Lerman, Greg Ver Steeg, and Aram Galstyan.
ICML, 2019.
[Paper]
A Higher-Order Graph Convolutional Layer.
Sami A Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Hrayr Harutyunyan.
NeurIPS, 2018.
[Paper]
The original TensorFlow implementation of MixHop is available [Here].
Requirements
The codebase is implemented in Python 3.5.2. package versions used for development are just below.
networkx 2.4
tqdm 4.28.1
numpy 1.15.4
pandas 0.23.4
texttable 1.5.0
scipy 1.1.0
argparse 1.1.0
torch 1.1.0
torch-sparse 0.3.0
Datasets
The code takes the **edge list** of the graph in a csv file. Every row indicates an edge between two nodes separated by a comma. The first row is a header. Nodes should be indexed starting with 0. A sample graph for `Cora` is included in the `input/` directory. In addition to the edgelist there is a JSON file with the sparse features and a csv with the target variable.
The **feature matrix** is a sparse binary one it is stored as a json. Nodes are keys of the json and feature indices are the values. For each node feature column ids are stored as elements of a list. The feature matrix is structured as:
{ 0: [0, 1, 38, 1968, 2000, 52727],
1: [10000, 20, 3],
2: [],
...
n: [2018, 10000]}
The **target vector** is a csv with two columns and headers, the first contains the node identifiers the second the targets. This csv is sorted by node identifiers and the target column contains the class meberships indexed from zero.
| NODE ID | Target |
|---|---|
| 0 | 3 |
| 1 | 1 |
| 2 | 0 |
| 3 | 1 |
| ... | ... |
| n | 3 |
Options
Training an N-GCN/MixHop model is handled by the `src/main.py` script which provides the following command line arguments.
Input and output options
--edge-path STR Edge list csv. Default is `input/cora_edges.csv`.
--features-path STR Features json. Default is `input/cora_features.json`.
--target-path STR Target classes csv. Default is `input/cora_target.csv`.
Model options
--model STR Model variant. Default is `mixhop`.
--seed INT Random seed. Default is 42.
--epochs INT Number of training epochs. Default is 2000.
--early-stopping INT Early stopping rounds. Default is 10.
--training-size INT Training set size. Default is 1500.
--validation-size INT Validation set size. Default is 500.
--learning-rate FLOAT Adam learning rate. Default is 0.01.
--dropout FLOAT Dropout rate value. Default is 0.5.
--lambd FLOAT Regularization coefficient. Default is 0.0005.
--layers-1 LST Layer sizes (upstream). Default is [200, 200, 200].
--layers-2 LST Layer sizes (bottom). Default is [200, 200, 200].
--cut-off FLOAT Norm cut-off for pruning. Default is 0.1.
--budget INT Architecture neuron budget. Default is 60.
Examples
The following commands learn a neural network and score on the test set. Training a model on the default dataset.
$ python src/main.py
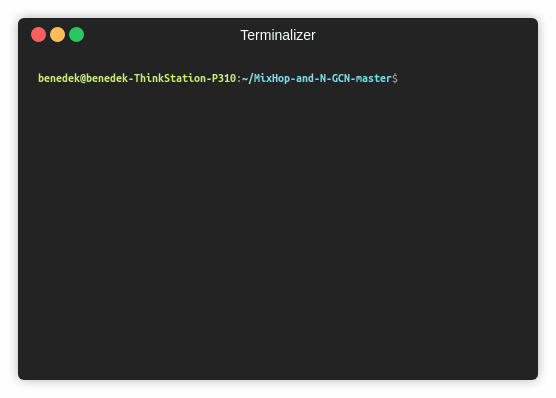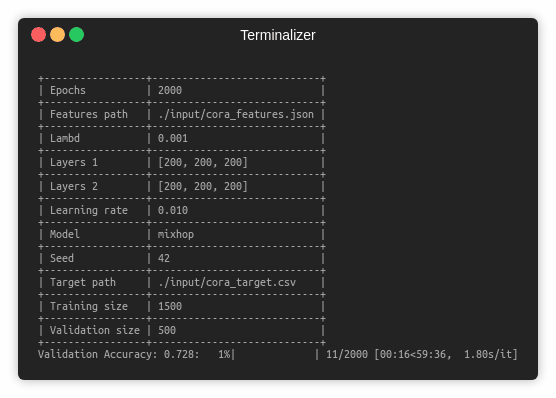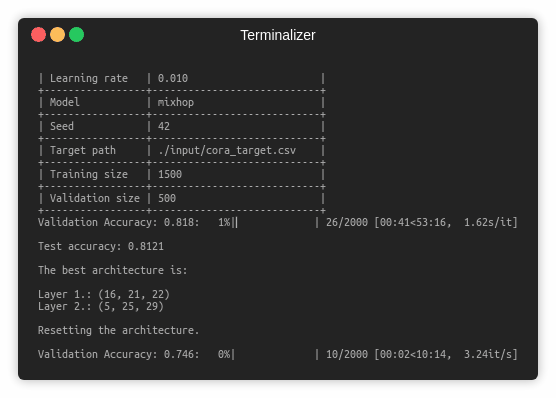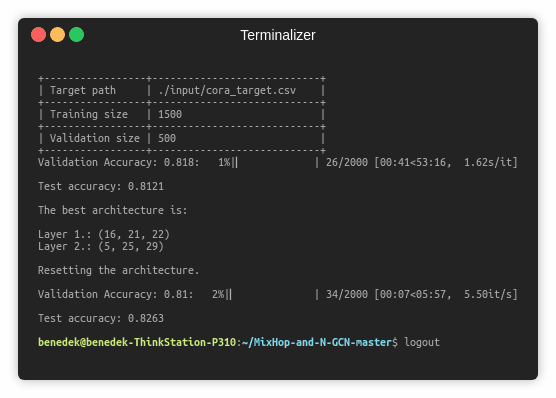
Training a MixHop model for a 100 epochs.
$ python src/main.py --epochs 100
Increasing the learning rate and the dropout.
$ python src/main.py --learning-rate 0.1 --dropout 0.9
Training a model with diffusion order 2:
$ python src/main.py --layers 64 64
Training an N-GCN model:
$ python src/main.py --model ngcn







