Implicit3DUnderstanding
Holistic 3D Scene Understanding from a Single Image with Implicit Representation
Cheng Zhang*, Zhaopeng Cui*, Yinda Zhang*, Shuaicheng Liu, Bing Zeng, Marc Pollefeys







Introduction
This repo contains training, testing, evaluation, visualization code of our CVPR 2021 paper.
Specially, the repo contains our PyTorch implementation of the decoder of LDIF, which can be extracted and used in other projects.
We are expecting to release a refactored version of our pipeline and a PyTorch implementation of the full LDIF model in the future.
Install
Please make sure to install CUDA NVCC on your system first. then run the following:
sudo apt install xvfb ninja-build freeglut3-dev libglew-dev meshlab
conda env create -f environment.yml
conda activate Im3D
python project.py build
When running python project.py build, the script will run external/build_gaps.sh which requires password for sudo privilege for apt-get install.
Please make sure you are running with a user with sudo privilege.
If not, please reach your administrator for installation of these libraries and comment out the corresponding lines then run python project.py build.
Demo
-
Download the pretrained checkpoint
and unzip it intoout/total3d/20110611514267/ -
Change current directory to
Implicit3DUnderstanding/and run the demo, which will generate 3D detection result and rendered scene mesh todemo/output/1/CUDA_VISIBLE_DEVICES=0 python main.py out/total3d/20110611514267/out_config.yaml --mode demo --demo_path demo/inputs/1 -
In case you want to run it off screen (for example, with SSH)
CUDA_VISIBLE_DEVICES=0 xvfb-run -a -s "-screen 0 800x600x24" python main.py out/total3d/20110611514267/out_config.yaml --mode demo --demo_path demo/inputs/1 -
If you want to run it interactively, change the last line of demo.py
scene_box.draw3D(if_save=True, save_path = '%s/recon.png' % (save_path))to
scene_box.draw3D(if_save=False, save_path = '%s/recon.png' % (save_path))
Data preparation
We follow Total3DUnderstanding to use SUN-RGBD to train our Scene Graph Convolutional Network (SGCN), and use Pix3D to train our Local Implicit Embedding Network
(LIEN) with Local Deep Implicit Functions (LDIF) decoder.
Preprocess SUN-RGBD data
Please follow Total3DUnderstanding to directly download the processed train/test data.
In case you prefer processing by yourself or want to evaluate 3D detection with our code
(To ultilize the evaluation code of Coop, we modified the data processing code of Total3DUnderstanding to save parameters for transforming the coordinate system from Total3D back to Coop),
please follow these steps:
-
Follow Total3DUnderstanding to download the raw data.
-
According to issue #6 of Total3DUnderstanding,
there are a few typos in json files of SUNRGBD dataset, which is mostly solved by the json loader.
However, one typo still needs to be fixed by hand.
Please find{"name":""propulsion"tool"}indata/sunrgbd/Dataset/SUNRGBD/kv2/kinect2data/002922_2014-06-26_15-43-16_094959634447_rgbf000089-resize/annotation2Dfinal/index.jsonand remove""propulsion. -
Process the data by
python -m utils.generate_data
Preprocess Pix3D data
We use a different data process pipeline with Total3DUnderstanding. Please follow these steps to generate the train/test data:
-
Download the Pix3D dataset to
data/pix3d/metadata -
Run below to generate the train/test data into 'data/pix3d/ldif'
python utils/preprocess_pix3d4ldif.py
Training and Testing
We use wandb for logging and visualization.
You can register a wandb account and login before training by wandb login.
In case you don't need to visualize the training process, you can put WANDB_MODE=dryrun before the commands bellow.
Thanks to the well-structured code of Total3DUnderstanding, we use the same method to manage parameters of each experiment with configuration files (configs/****.yaml).
We first follow Total3DUnderstanding to pretrain each individual module, then jointly finetune the full model with additional physical violation loss.
Pretraining
We use the pretrained checkpoint of Total3DUnderstanding to load weights for ODN.
Please download and rename the checkpoint to out/pretrained_models/total3d/model_best.pth.
Other modules can be trained then tested with the following steps:
-
Train LEN by:
python main.py configs/layout_estimation.yamlThe pretrained checkpoint can be found at
out/layout_estimation/[start_time]/model_best.pth -
Train LIEN + LDIF by:
python main.py configs/ldif.yamlThe pretrained checkpoint can be found at
out/ldif/[start_time]/model_best.pth
(alternatively, you can download the pretrained model here, and unzip it into out/ldif/20101613380518/)The training process is followed with a quick test without ICP and Chamfer distance evaluated. In case you want to align mesh and evaluate the Chamfer distance during testing:
python main.py configs/ldif.yaml --mode trainThe generated object meshes can be found at
out/ldif/[start_time]/visualization -
Replace the checkpoint directories of LEN and LIEN in
configs/total3d_ldif_gcnn.yamlwith the checkpoints trained above, then train SGCN by:python main.py configs/total3d_ldif_gcnn.yamlThe pretrained checkpoint can be found at
out/total3d/[start_time]/model_best.pth
Joint finetune
-
Replace the checkpoint directory in
configs/total3d_ldif_gcnn_joint.yamlwith the one trained in the last step above, then train the full model by:python main.py configs/total3d_ldif_gcnn_joint.yamlThe trained model can be found at
out/total3d/[start_time]/model_best.pth -
The training process is followed with a quick test without scene mesh generated. In case you want to generate the scene mesh during testing (which will cost a day on 1080ti due to the unoptimized interface of LDIF CUDA kernel):
python main.py configs/total3d_ldif_gcnn_joint.yaml --mode trainThe testing resaults can be found at
out/total3d/[start_time]/visualization
Testing
-
The training process above already include a testing process. In case you want to test LIEN+LDIF or full model by yourself:
python main.py out/[ldif/total3d]/[start_time]/out_config.yaml --mode testThe results will be saved to
out/total3d/[start_time]/visualizationand the evaluation metrics will be logged to wandb as run summary. -
Evaluate 3D object detection with our modified matlab script from Coop:
external/cooperative_scene_parsing/evaluation/detections/script_eval_detection.mBefore running the script, please specify the following parameters:
SUNRGBD_path = 'path/to/SUNRGBD'; result_path = 'path/to/experiment/results/visualization'; -
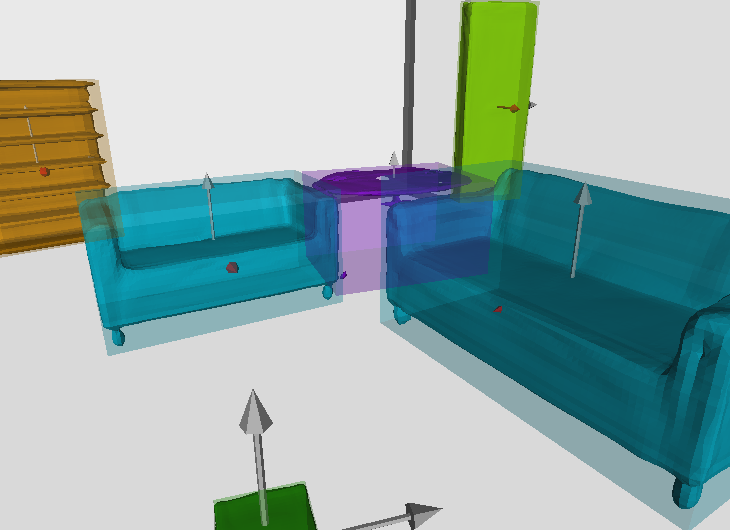
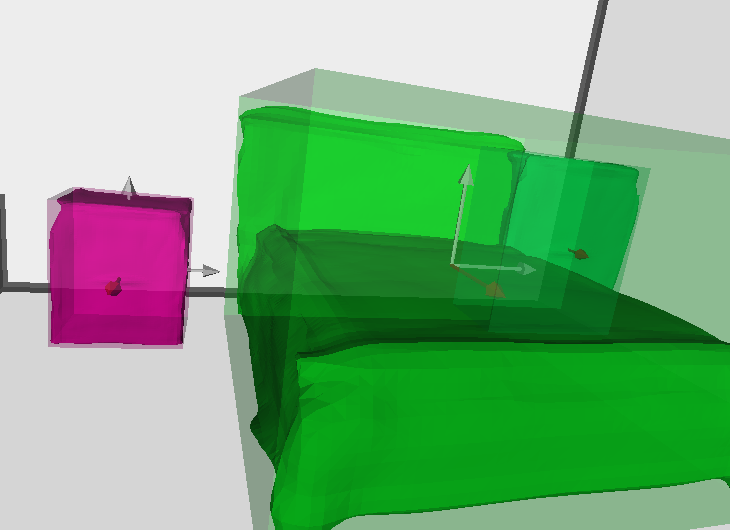
Visualize the i-th 3D scene interacively by
python utils/visualize.py --result_path out/total3d/[start_time]/visualization --sequence_id [i]or save the 3D detection result and rendered scene mesh by
python utils/visualize.py --result_path out/total3d/[start_time]/visualization --sequence_id [i] --save_path []In case you do not have a screen:
python utils/visualize.py --result_path out/total3d/[start_time]/visualization --sequence_id [i] --save_path [] --offscreenIf nothing goes wrong, you should get results like:


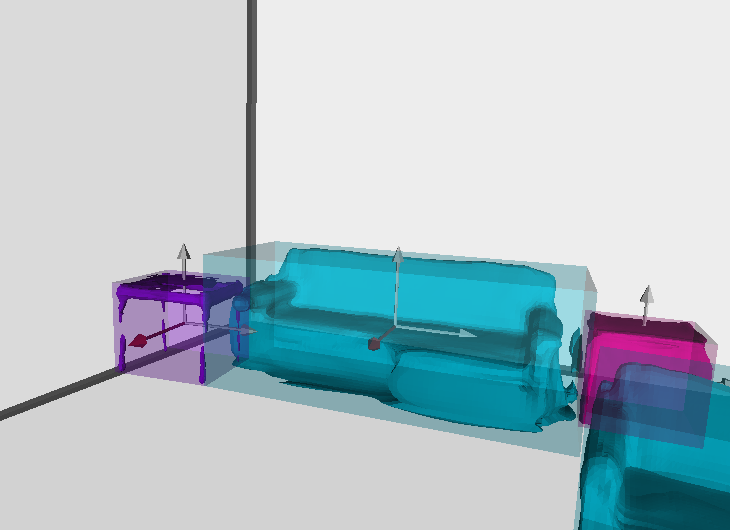
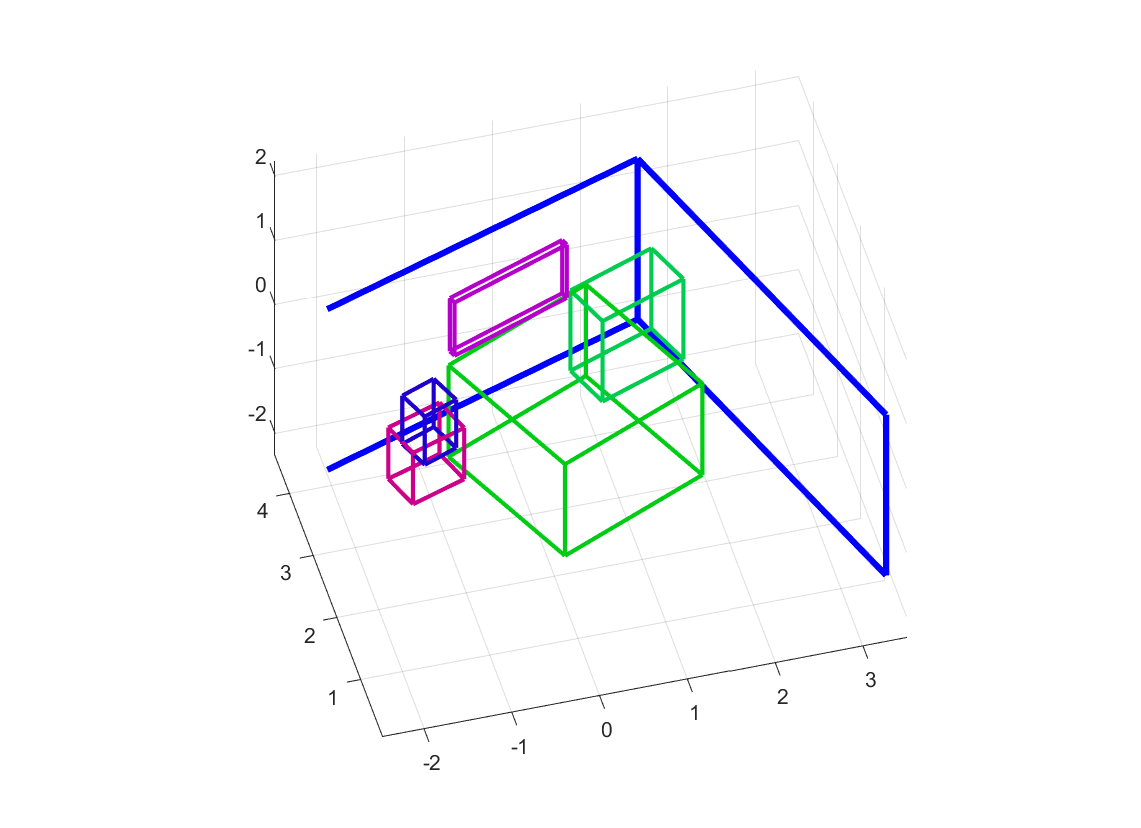
- Visualize the detection results from a third person view with our modified matlab script from Coop:
Before running the script, please specify the following parameters:external/cooperative_scene_parsing/evaluation/vis/show_result.m
If nothing goes wrong, you should get results like:SUNRGBD_path = 'path/to/SUNRGBD'; save_root = 'path/to/save/the/detection/results'; paths = { {'path/to/save/detection/results', 'path/to/experiment/results/visualization'}, ... {'path/to/save/gt/boundingbox/results'} }; vis_pc = false; % or true, if you want to show cloud point ground truth views3d = {'oblique', 'top'}; % choose prefered view dosave = true; % or false, please place breakpoints to interactively view the results.
About the testing speed
Thanks to the simplicity of LIEN+LDIF, the pretrain takes only about 8 hours on a 1080Ti.
However, although we used the CUDA kernel of LDIF to optimize the speed,
the file-based interface of the kernel still bottlenecked the mesh reconstruction.
This is the main reason why our method takes much more time in object and scene mesh reconstruction.
If you want speed over mesh quality, please lower the parameter data.marching_cube_resolution in the configuration file.
Citation
If you find our work and code helpful, please consider cite:
@InProceedings{Zhang_2021_CVPR,
author = {Zhang, Cheng and Cui, Zhaopeng and Zhang, Yinda and Zeng, Bing and Pollefeys, Marc and Liu, Shuaicheng},
title = {Holistic 3D Scene Understanding From a Single Image With Implicit Representation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {8833-8842}
}
We thank the following great works:
- Total3DUnderstanding for their well-structured code. We construct our network based on their well-structured code.
- Coop for their dataset. We used their processed dataset with 2D detector prediction.
- LDIF for their novel representation method. We ported their LDIF decoder from Tensorflow to PyTorch.
- Graph R-CNN for their scene graph design. We adopted their GCN implemention to construct our SGCN.
- Occupancy Networks for their modified version of mesh-fusion pipeline.
If you find them helpful, please cite:
@InProceedings{Nie_2020_CVPR,
author = {Nie, Yinyu and Han, Xiaoguang and Guo, Shihui and Zheng, Yujian and Chang, Jian and Zhang, Jian Jun},
title = {Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes From a Single Image},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
@inproceedings{huang2018cooperative,
title={Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation},
author={Huang, Siyuan and Qi, Siyuan and Xiao, Yinxue and Zhu, Yixin and Wu, Ying Nian and Zhu, Song-Chun},
booktitle={Advances in Neural Information Processing Systems},
pages={206--217},
year={2018}
}
@inproceedings{genova2020local,
title={Local Deep Implicit Functions for 3D Shape},
author={Genova, Kyle and Cole, Forrester and Sud, Avneesh and Sarna, Aaron and Funkhouser, Thomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4857--4866},
year={2020}
}
@inproceedings{yang2018graph,
title={Graph r-cnn for scene graph generation},
author={Yang, Jianwei and Lu, Jiasen and Lee, Stefan and Batra, Dhruv and Parikh, Devi},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={670--685},
year={2018}
}
@inproceedings{mescheder2019occupancy,
title={Occupancy networks: Learning 3d reconstruction in function space},
author={Mescheder, Lars and Oechsle, Michael and Niemeyer, Michael and Nowozin, Sebastian and Geiger, Andreas},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={4460--4470},
year={2019}
}



