bottleneck-transformer-pytorch
Implementation of Bottleneck Transformer, SotA visual recognition model with convolution + attention that outperforms EfficientNet and DeiT in terms of performance-computes trade-off, in Pytorch
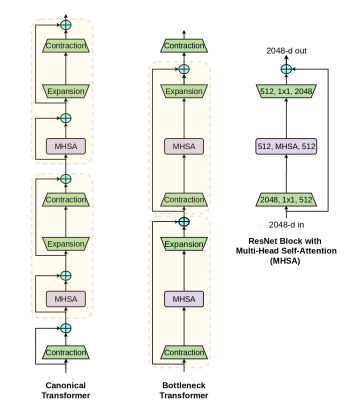
Install
$ pip install bottleneck-transformer-pytorch
Usage
import torch
from torch import nn
from bottleneck_transformer_pytorch import BottleStack
layer = BottleStack(
dim = 256, # channels in
fmap_size = 64, # feature map size
dim_out = 2048, # channels out
proj_factor = 4, # projection factor
downsample = True, # downsample on first layer or not
heads = 4, # number of heads
dim_head = 128, # dimension per head, defaults to 128
rel_pos_emb = False, # use relative positional embedding - uses absolute if False
activation = nn.ReLU() # activation throughout the network
)
fmap = torch.randn(2, 256, 64, 64) # feature map from previous resnet block(s)
layer(fmap) # (2, 2048, 32, 32)
Citations
@misc{srinivas2021bottleneck,
title = {Bottleneck Transformers for Visual Recognition},
author = {Aravind Srinivas and Tsung-Yi Lin and Niki Parmar and Jonathon Shlens and Pieter Abbeel and Ashish Vaswani},
year = {2021},
eprint = {2101.11605},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}



