Implicit-feature-alignment
This is a pytorch-based implementation for paper Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter.
Due to the company's code confidentiality requirements, we only release the code of ExCTC on the IAM dataset.
Personally, I dont't think it is a thorough work, but I hope this idea is useful.
Requirements
Data Preparation
We re-crop the lines from IAM full-page images. This operation is to remove the edge phenomenon in the official line images.
Official image:

Re-cropped image:

These re-cropped images are used as training set.
Training
Trained parameter: https://drive.google.com/drive/folders/1rXJ9at9erPN6v5nPAOGWsMWFUiwBq8D6?usp=sharing
Crop the training images (data/crop_images.py) and modify the path in configuration files (cfgs.py). Then
python main.py
A simple demo:
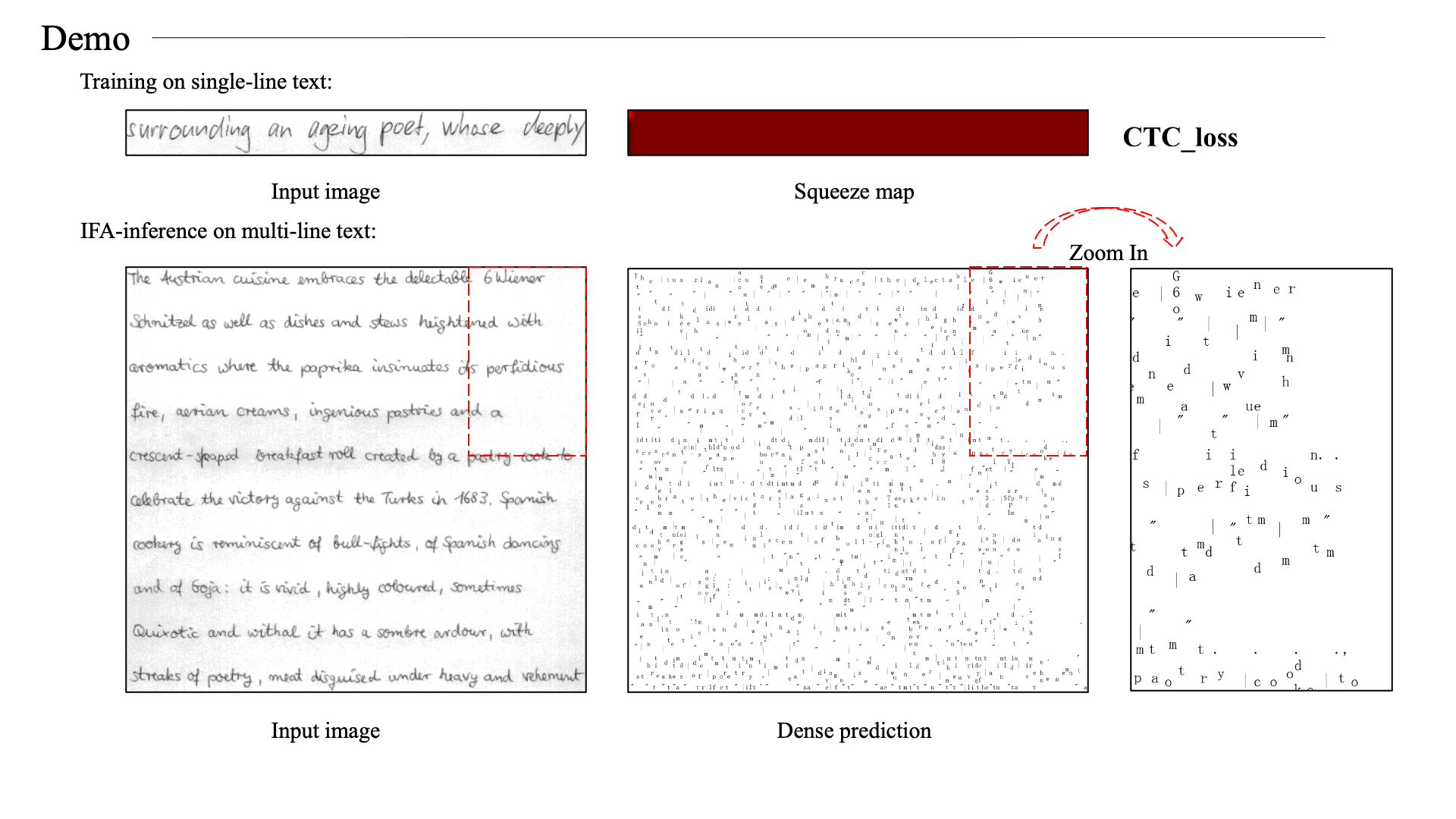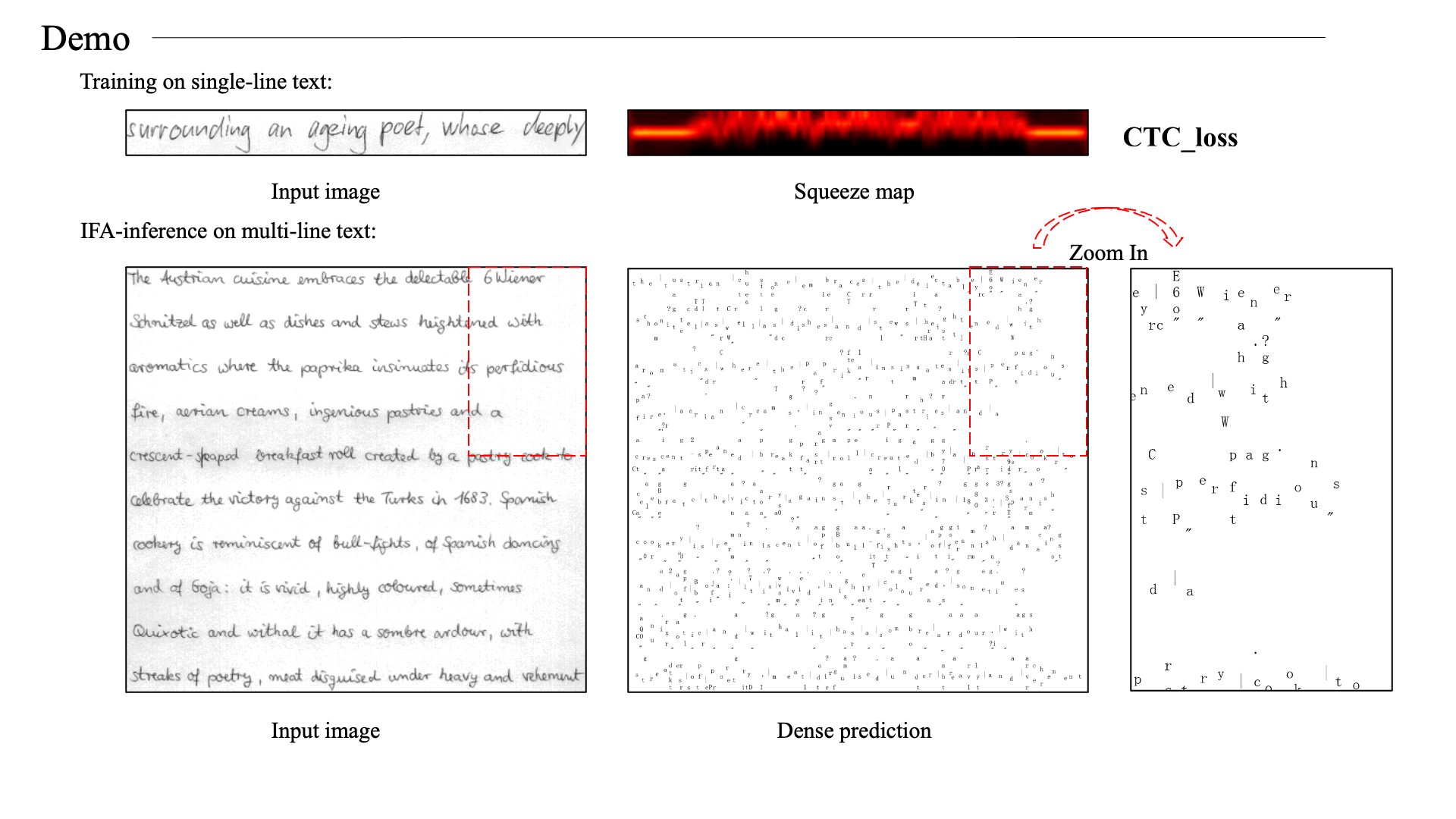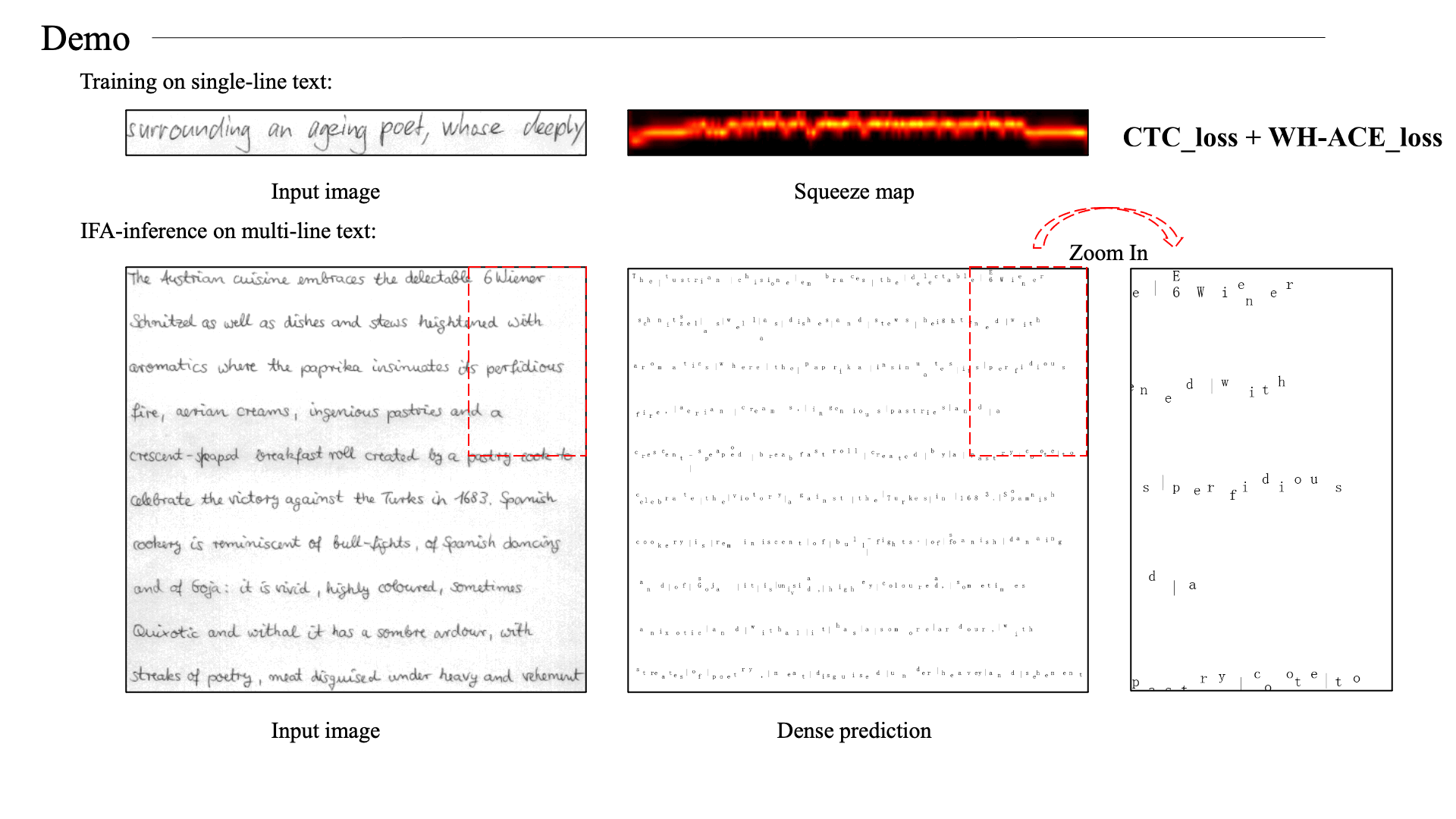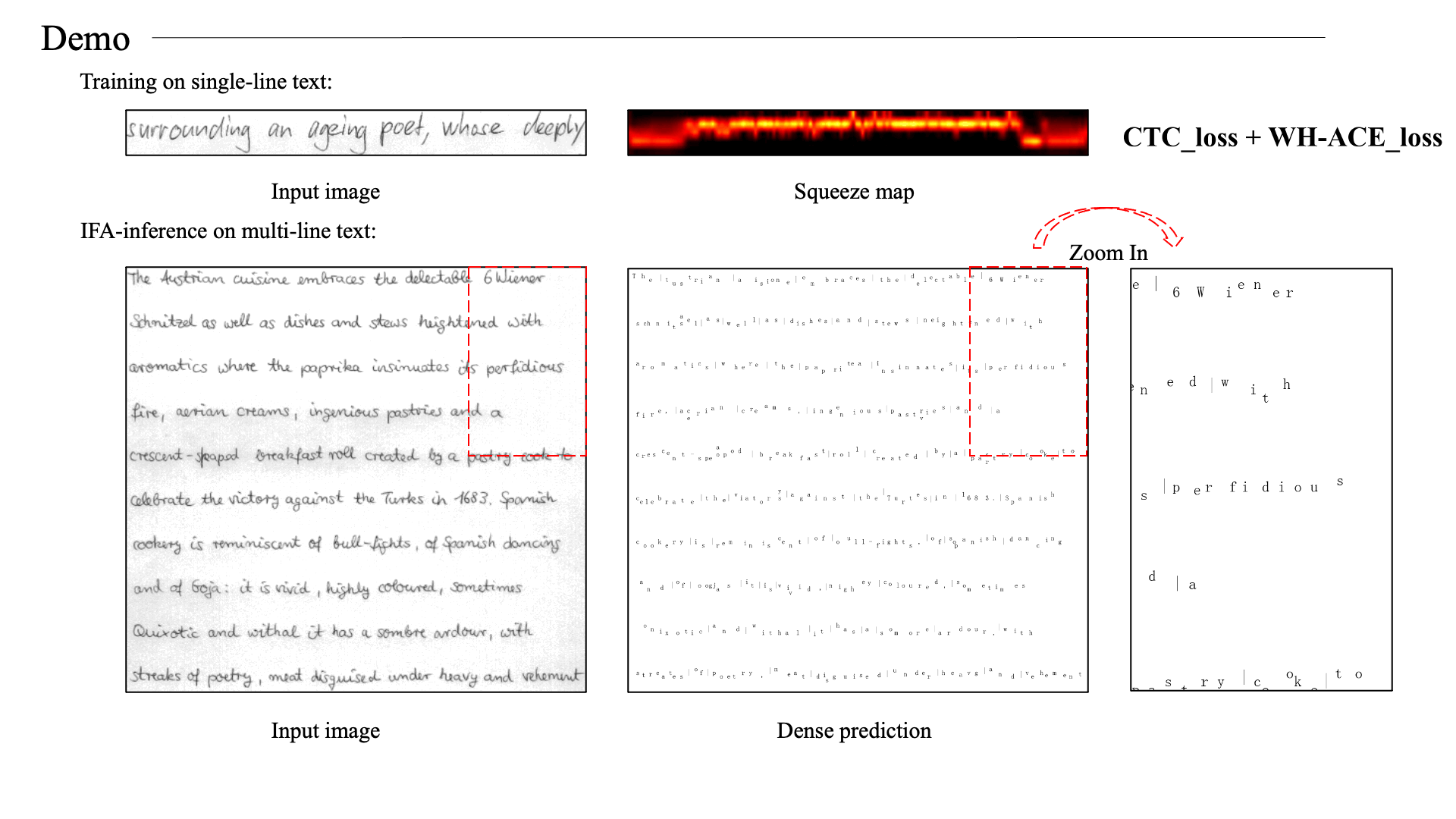
Ackowledgement
We use the augmentation toolkit released by RubanSeven to train the network.





