LASR
Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
Installation
Build with conda
conda env create -f lasr.yml
conda activate lasr
# install softras
cd third_party/softras; python setup.py install; cd -;
# install manifold remeshing
git clone --recursive -j8 git://github.com/hjwdzh/Manifold; cd Manifold; mkdir build; cd build; cmake .. -DCMAKE_BUILD_TYPE=Release;make; cd ../../
Overview
We provide instructions for data preparation and shape optimization on three types of data,
- Spot: Synthetic rendering of 3D meshes for debugging and evaluation
- DAVIS-camsl: Video frames with ground-truth segmentation masks
- Pika: Your own video
We recomend first trying spot and make sure the system works, and then run the rest two examples.
Data preparation
Create folders to store intermediate data and training logs
mkdir log; mkdir tmp;
The following steps generates data in subfolders under ./database/DAVIS/.
Spot: synthetic data
Download and unzip the pre-computed {silhouette, flow, rgb} rendering of spot,
gdown https://drive.google.com/uc?id=11Y3WQ0Qd7W-6Wds1_A7KsTbaG7jrmG7N -O spot.zip
unzip spot.zip -d database/DAVIS/
Otherwise, you could render the same data locally by running,
python scripts/render_syn.py
DAVIS-camel: real video frames with segmentation
First, download DAVIS 2017 trainval set and
copy JPEGImages/Full-Resolution and Annotations/Full-Resolution folders of DAVIS-camel into the according folders in database.
cp ...davis-path/DAVIS/Annotations/Full-Resolution/camel/ -rf database/DAVIS/Annotations/Full-Resolution/
cp ...davis-path/DAVIS-lasr/DAVIS/JPEGImages/Full-Resolution/camel/ -rf database/DAVIS/JPEGImages/Full-Resolution/
Then download pre-trained VCN optical flow:
mkdir ./lasr_vcn
gdown https://drive.google.com/uc?id=139S6pplPvMTB-_giI6V2dxpOHGqqAdHn -O ./lasr_vcn/vcn_rob.pth
Run VCN-robust to predict optical flow on DAVIS camel video:
bash preprocess/auto_gen.sh camel
Pika: your own video
You will need to install and clone detectron2 to obtain object segmentations as instructed below.
python -m pip install detectron2 -f \
https://dl.fbaipublicfiles.com/detectron2/wheels/cu110/torch1.7/index.html
git clone https://github.com/facebookresearch/detectron2
First, use any video processing tool (such as ffmpeg) to extract frames into JPEGImages/Full-Resolution/name-of-the-video.
mkdir database/DAVIS/JPEGImages/Full-Resolution/pika-tmp/
ffmpeg -ss 00:00:04 -i database/raw/IMG-7495.MOV -vf fps=10 database/DAVIS/JPEGImages/Full-Resolution/pika-tmp/%05d.jpg
Then, run pointrend to get segmentations:
cd preprocess
python mask.py pika ./detectron2; cd -
Assuming you have downloaded VCN flow in the previous step, run flow prediction:
bash preprocess/auto_gen.sh pika
Single video optimization
Spot
Next, we want to optimize the shape, texture and camera parameters from image observartions. Optimizing spot takes ~20min on a single Titan Xp GPU.bash scripts/spot3.sh
To render the optimized shape, texture and camera parameters
bash scripts/extract.sh spot3-1 10 1 26 spot3 no no
python render_vis.py --testdir log/spot3-1/ --seqname spot3 --freeze --outpath tmp/1.gif
DAVIS-camel
Optimize on camel observations.
bash scripts/template.sh camel
To render optimized camel
bash scripts/render_result.sh camel
Pika
Similarly, run the following steps to reconstruct pika
bash scripts/template.sh pika
To render reconstructed shape
bash scripts/render_result.sh pika
Monitor optimization
To monitor optimization, run
tensorboard --logdir log/
Example outputs

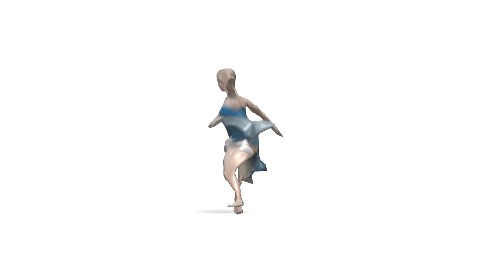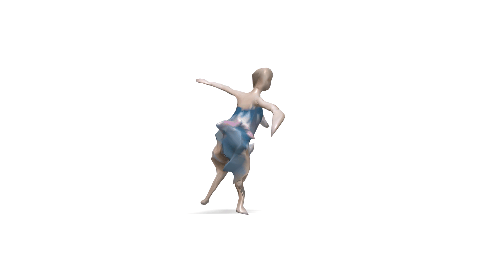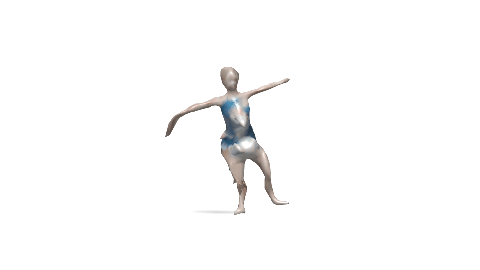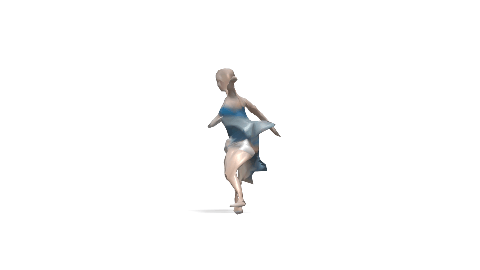

Evaluation
Run the following command to evaluate 3D shape accuracy for synthetic spot.
python scripts/eval_mesh.py --testdir log/spot3-1/ --gtdir database/DAVIS/Meshes/Full-Resolution/syn-spot3f/
Run the following command to evaluate keypoint accuracy on BADJA.
python scripts/eval_badja.py --testdir log/camel-5/ --seqname camel
Additional Notes
Other videos in DAVIS/BAJDA
Please refer to data preparation and optimization of the camel example, and modify camel to other sequence names, such as dance-twirl.
We provide config files the configs folder.
Synthetic articulated objects
To render and reproduce results on articulated objects (Sec. 4.2), you will need to purchase and download 3D models here.
We use blender to export animated meshes and run rendera_all.py:
python scripts/render_syn.py --outdir syn-dog-15 --nframes 15 --alpha 0.5 --model dog
Optimize on rendered observations
bash scripts/dog15.sh
To render optimized dog
bash scripts/render_result.sh dog
Batchsize
The current codebase is tested with batchsize=4. Batchsize can be modified in scripts/template.sh.
Note decreasing the batchsize will improive speed but reduce the stability.
Distributed training
The current codebase supports single-node multi-gpu training with pytorch distributed data-parallel.
Please modify dev and ngpu in scripts/template.sh to select devices.






