DDFlow
The official Tensorflow implementation of DDFlow (AAAI 2019).
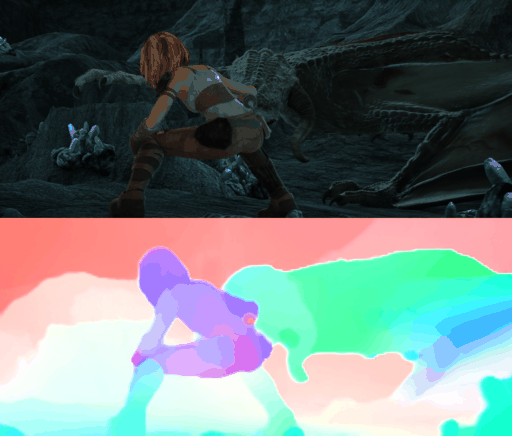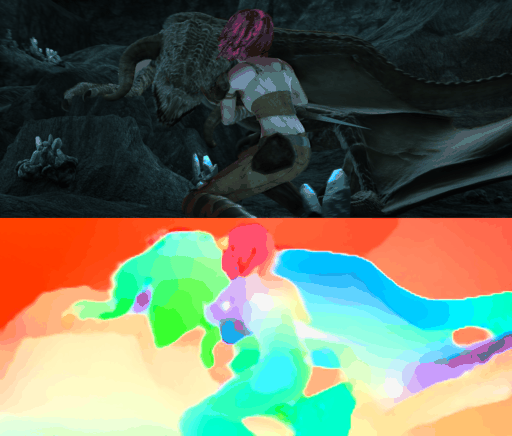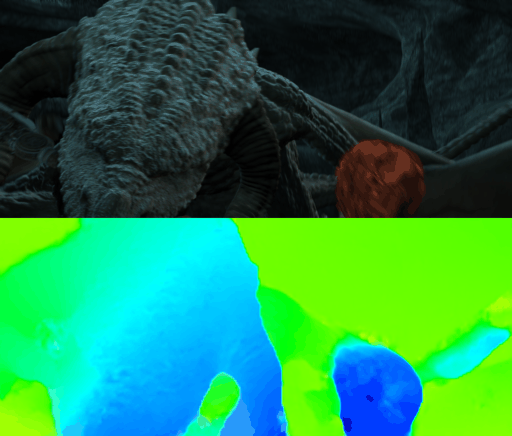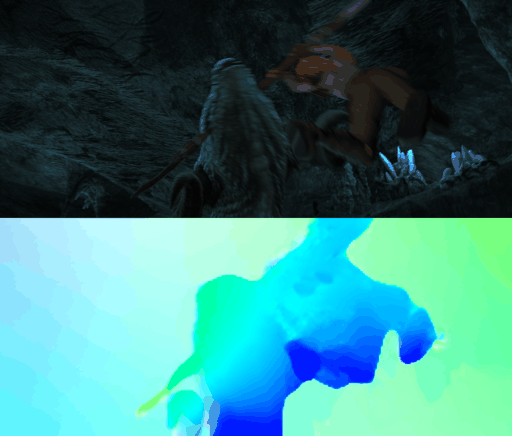
Requirements
- Software: The code was developed with python 2.7, opencv 3, tensorflow 1.8 and anaconda (python 2.7 version). It's okay to run without anaconda, but you may need to install the lacking packages by yourself when needed.
- Hardware: GPU with memory 12G or more is recommended. We also implement the multi-gpu version. Please use multiple GPUs when available.
Usage
By default, run "python main.py", you can get the testing results using the pre-trained KITTI model.
Please refer to the configuration file template config for a detailed description of the different operating modes.
Training
- Datasets: Please download Flying Chairs, KITTI 2012 (multi-view extension), KITTI 2015 (multi-view extension) and Sintel.
- Here we choose KITTI 2015 dataset as an example. Other datasets have similar training procedures. If you want to fully reproduce the results from scratch, please follow the training procedure in the paper.
- To reduce computation cost, we fix teacher model and pre-compute optical flow and occlusion map in this implementation, which is a little different from the paper implementation. Under such setting, we can achieve similar performance with much less computation cost.
- Step 1: Training without data distillation
- Edit config, set mode = train.
- Set training_mode=no_data_distillation
- Train the model without both census transform and occlusion handling for 100k steps (or more). Specially, edit function create_train_op and set optim_loss as losses['abs_robust_mean']['no_occlusion']. If you want to add regularization, please add it in the optim_loss.
- If needing to restore model from a checkpoint, set is_restore_model=True, set restore_model to the directory of the checkpoint.
- Train the model with both census transform and occlusion handling for 300k steps (or more). Specially, edit function create_train_op and set optim_loss as losses['census']['occlusion'].
- Step 2: Generate reliable optical flow and occlusion map
- Edit config, set mode=generate_fake_flow_occlusion
- Run the code to generate both flow and occlusion map.
- Step 3: Training with data distillation
- Edit config, set mode = train.
- Set training_mode=data_distillation
- Train the model with census transform, occlusion handling and data distillation for 300k steps (or more). Specially, edit function create_train_op and set optim_loss as losses['census']['occlusion']+losses['data_distillation'].
Pre-trained Models
Check models for our pre-trained models on different datasets.
Citation
If you find DDFlow useful in your research, please consider citing:
@inproceedings{Liu:2019:DDFlow,
title = {DDFlow: Learning Optical Flow with Unlabeled Data Distillation},
author = {Pengpeng Liu and Irwin King and Michael R. Lyu and Jia Xu},
booktitle = {AAAI},
year = {2019}}
Acknowledgement
Part of our codes are adapted from PWC-Net and UnFlow, we thank the authors for their contributions.



