Talking-Face_PC-AVS
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)
Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu.

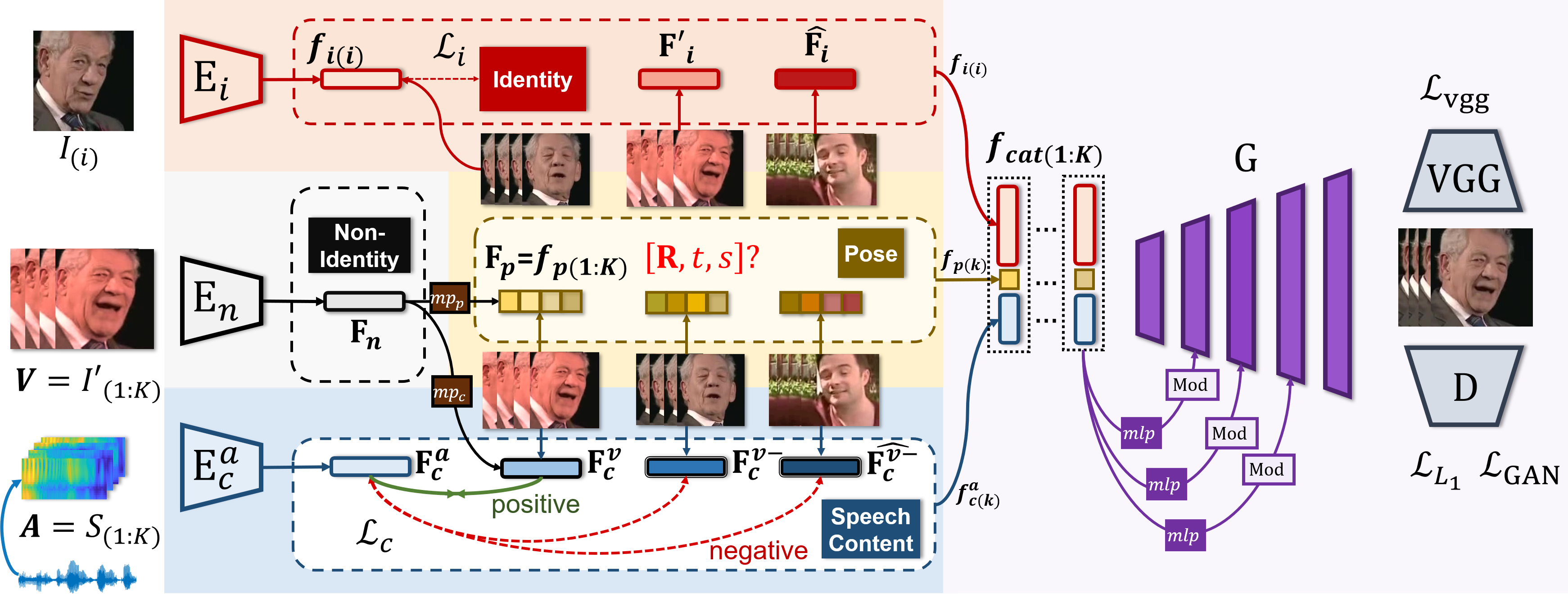
We propose Pose-Controllable Audio-Visual System (PC-AVS),
which achieves free pose control when driving arbitrary talking faces with audios. Instead of learning pose motions from audios, we leverage another pose source video to compensate only for head motions.
The key is to devise an implicit low-dimension pose code that is free of mouth shape or identity information.
In this way, audio-visual representations are modularized into spaces of three key factors: speech content, head pose, and identity information.
Requirements
- Python 3.6 and Pytorch 1.3.0 are used. Basic requirements are listed in the 'requirements.txt'.
pip install -r requirements.txt
Quick Start: Generate Demo Results
-
Download the pre-trained checkpoints.
-
Create the default folder
./checkpointsand
unzip thedemo.zipat./checkpoints/demo. There should be 5pths in it. -
Unzip all
*.zipfiles within themiscfolder. -
Run the demo scripts:
bash experiments/demo_vox.sh
- The
--gen_videoargument is by default on,
ffmpeg >= 4.0.0 is required to use this flag in linux systems.
All frames along with anavconcat.mp4video file will be saved in the./id_517600055_pose_517600078_audio_681600002/resultsfolder.

From left to right are the reference input, the generated results,
the pose source video and the synced original video with the driving audio.
Prepare Testing Meta Data
-
Automatic VoxCeleb2 Data Formulation
The inference code experiments/demo.sh refers to https://raw.githubusercontent.com/Hangz-nju-cuhk/Talking-Face_PC-AVS/main/misc/demo.csv for testing data paths.
In linux systems, any applicable csv file can be created automatically by running:
python scripts/prepare_testing_files.py
Then modify the meta_path_vox in experiments/demo_vox.sh to 'https://raw.githubusercontent.com/Hangz-nju-cuhk/Talking-Face_PC-AVS/main/misc/demo2.csv' and run
bash experiments/demo_vox.sh
An additional result should be seen saved.
-
Metadata Details
Detailedly, in scripts/prepare_testing_files.py there are certain flags which enjoy great flexibility when formulating the metadata:
-
--src_pose_pathdenotes the driving pose source path.
It can be anmp4file or a folder containing frames in the form of%06d.jpgstarting from 0. -
--src_audio_pathdenotes the audio source's path.
It can be anmp3audio file or anmp4video file. If a video is given,
the frames will be automatically saved inhttps://raw.githubusercontent.com/Hangz-nju-cuhk/Talking-Face_PC-AVS/main/misc/Mouth_Source/video_name, and disables the--src_mouth_frame_pathflag. -
--src_mouth_frame_path. When--src_audio_pathis not a video path,
this flags could provide the folder containing the video frames synced with the source audio. -
--src_input_pathis the path to the input reference image. When the path is a video file, we will convert it to frames. -
--csv_paththe path to the to-be-saved metadata.
You can manually modify the metadata csv file or add lines to it according to the rules defined in the scripts/prepare_testing_files.py file or the dataloader data/voxtest_dataset.py.
We provide a number of demo choices in the misc folder, including several ones used in our video.
Feel free to rearrange them even across folders. And you are welcome to record audio files by yourself.
-
Self-Prepared Data Processing
Our model handles only VoxCeleb2-like cropped data, thus pre-processing is needed for self-prepared data.
To process self-prepared data face-alignment is needed. It can be installed by running
pip install face-alignment
Assuming that a video is already processed into a [name] folder by previous steps through prepare_testing_files.py,
you can run
python scripts/align_68.py --folder_path [name]
The cropped images will be saved at an additional [name_cropped] folder.
Then you can manually change the demo.csv file or alter the directory folder path and run the preprocessing file again.






