Question-Answering-Albert-Electra
Question Answering using Albert and Electra.
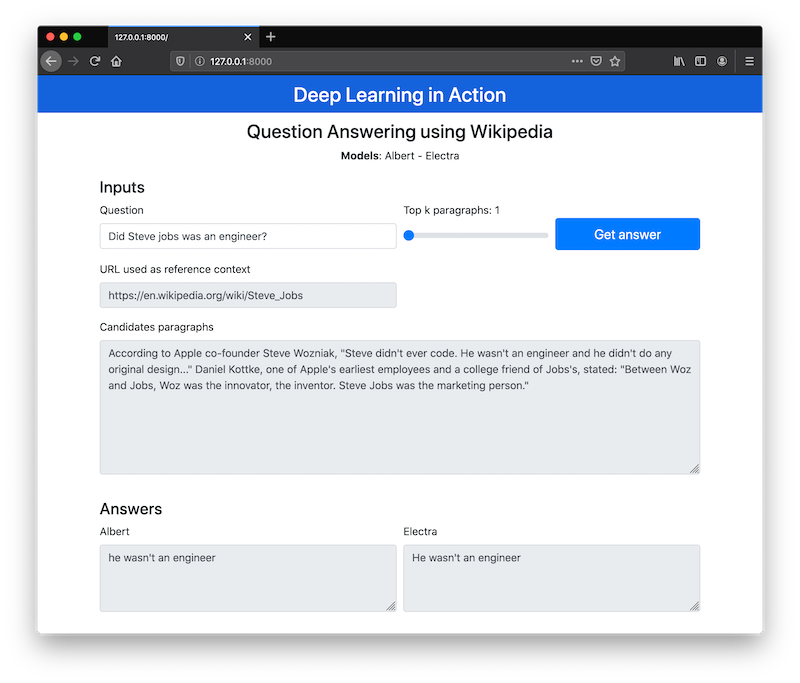
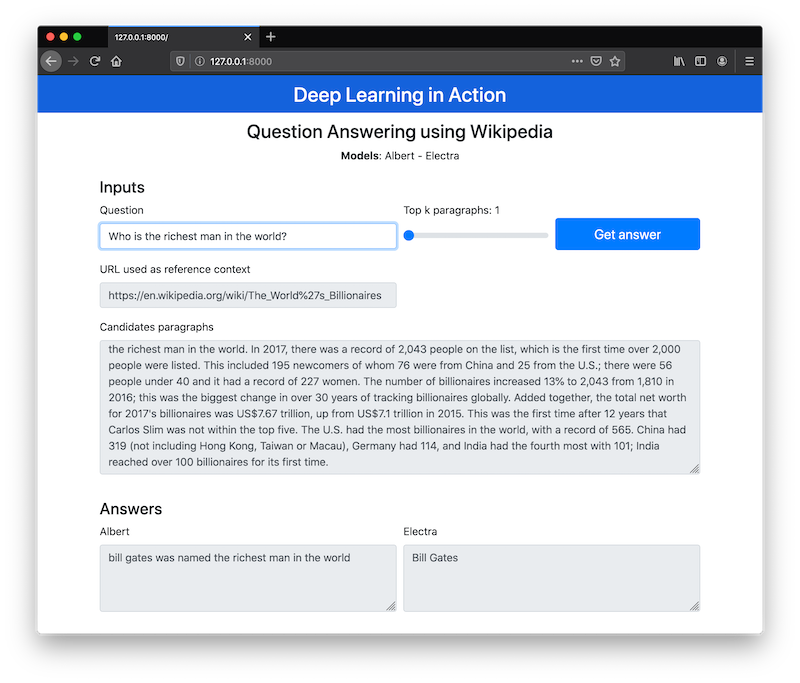
This repository implements a pipeline to answer questions using wikipedia text. Bellow is the pipeline:
- Using the input query, search on google filtering the wikipedia pages.
- Read the body content of the wikipedia, preprocess text and split the corpus in paragraphs.
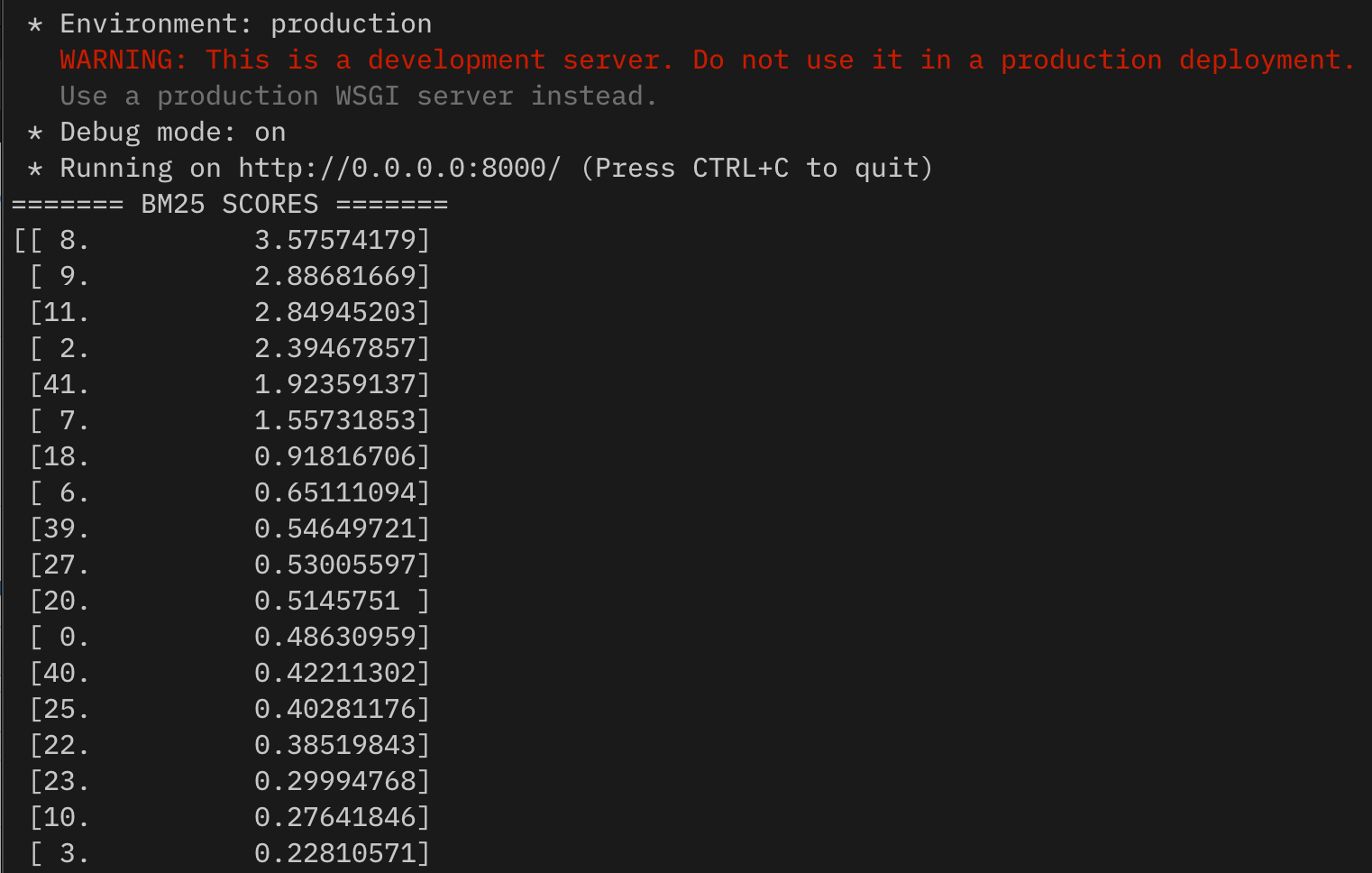
- Use BM25 algorithm to rank the best candidate passages, using the top K paragraphs.
- Selected paragraphs are used as input to Albert and Electra models.
- Both models try to find the answer given the candidate paragraphs.
Running
To predict with Electra, you need to download the pre-trained model from here. Extract the folder and adjust the DATA_MODEL_DIR (line 26) in qa_predict.py to point to the root folder.