Rethinking-Image-Mixture-for-Unsupervised-Learning
This repo contains the implementation for Rethinking Image Mixture for Unsupervised Visual Representation Learning, which perturbs input image space to soften the output prediction space indirectly, so that the proposed method can smooth decision boundaries and prevent the learner from becoming over-confident.
Our Motivation: Soften Predictions
An Example of Using this Code on MoCo and CMC
CMC with Image Mixture (https://github.com/szq0214/CMC_with_Image_Mixture).
IM flag:
--IM: train with IM space.--IM_type: specify the type of IM and other augmentation methods that we implement, including: 'IM', 'global', 'region', 'Cutout', 'RandomErasing'.
Global mixture:
--g_alpha: global mix alpha. Default: 1.0--g_num: global mix num. Default: 2--g_prob: global mix prob. Default: 0.1
Region-level mixture:
--r_beta: region mix beta. Default: 1.0--r_prob: region mix prob. Default: 0.1--r_num: region mix num. Default: 2--r_pixel_decay: region mix pixel decay. Default: 1.0
We also include other data augmentation methods like Cutout and Random Erasing in this repo, the results are inferior than ours.
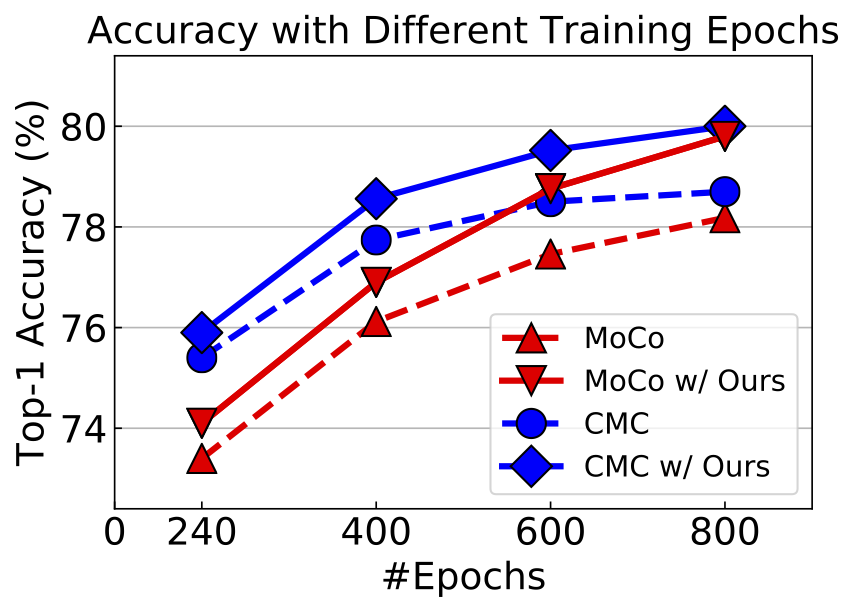
Results
We run our method with MoCo and CMC, the results are as follows:
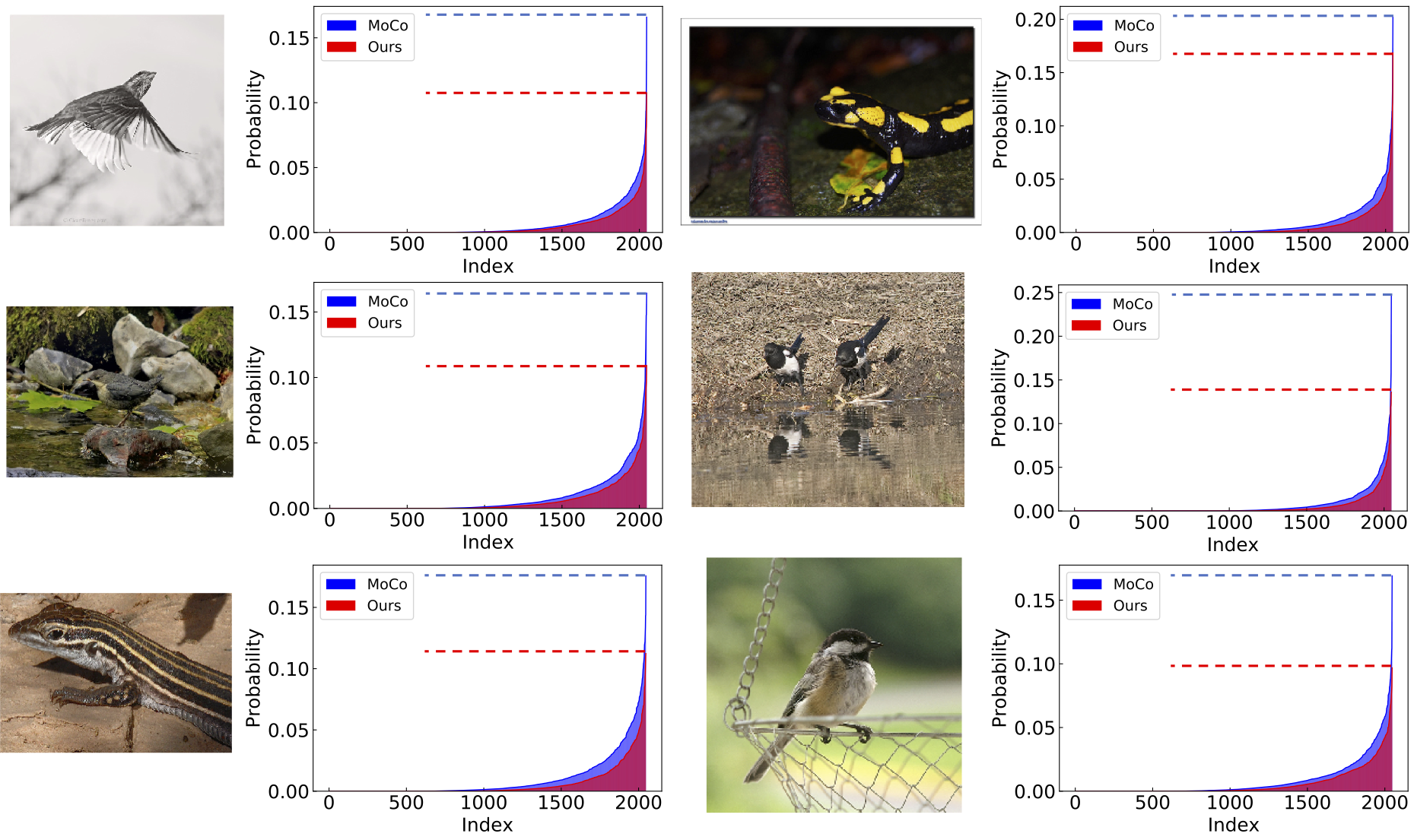
Visualizations
Citation
If you find this repo useful for your research, please consider citing the paper
@article{shen2020rethinking,
title={Rethinking Image Mixture for Unsupervised Visual Representation Learning},
author={Shen, Zhiqiang and Liu, Zechun and Liu, Zhuang and Savvides, Marios and Darrell, Trevor},
journal={arXiv preprint arXiv:2003.05438},
year={2020}
}
For any questions, please contact Zhiqiang Shen ([email protected]).



