ros2learn
This repository contains a number of ROS and ROS 2 enabled Artificial Intelligence (AI) and Reinforcement Learning (RL) algorithms that run in selected environments.
The repository contains the following:
- algorithms: techniques used for training and teaching robots.
- environments: pre-built environments of interest to train selected robots.
- experiments: experiments and examples of the different utilities that this repository provides.
A whitepaper about this work is available at https://arxiv.org/abs/1903.06282. Please use the following BibTex entry to cite our work:
@misc{1903.06282,
Author = {Yue Leire Erro Nuin and Nestor Gonzalez Lopez and Elias Barba Moral and Lander Usategui San Juan and Alejandro Solano Rueda and Víctor Mayoral Vilches and Risto Kojcev},
Title = {ROS2Learn: a reinforcement learning framework for ROS 2},
Year = {2019},
Eprint = {arXiv:1903.06282},
}
Usage
Train an agent
You will find all available examples at /experiments/examples/. Although the algorithms are complex, the way to execute them is really simple. For instance, if you want to train MARA robot using ppo2_mlp, you should execute the following command:
cd ~/ros2learn/experiments/examples/MARA
python3 train_ppo2_mlp.py
Note that you can add the command line arguments provided by the environment, which in this case are provided by the gym-gazebo2 Env. Use -h to get all the available commands.
If you want to test your own trained neural networks, or train with different environment form gym-gazebo2, or play with the hyperparametes, you must update the values of the dictionary directly in the corresponding algorithm itself. For this example, we are using ppo2_mlp from baselines submodule, so you can edit the mara_mpl() function inside baselines/ppo2/defaults.py.
Run a trained policy
Once you are done with the training, or if you want to test some specific checkpoint of it, you can run that using one of the running-scripts available. This time, to follow with the example, we are going to run a saved ppo2_mlp policy.
First, we will edit the already mentioned mara_mpl() dictionary, in particular the trained_path value, in baselines/ppo2/defaults.py to the checkpoint we want (checkpoints placed by default in /tmp/ros2learn). Now we are ready to launch the script.
Since we want to visualize it in real conditions, we are also going to set some flags:
cd ~/ros2learn/experiments/examples/MARA
python3 run_ppo2_mlp.py -g -r -v 0.3
This will launch the simulation with the visual interface, real time physics (no speed up) and 0.3 rad/sec velocity in each servomotor.

Visualize training data on tensorboard
The logdir path will change according to the used environment ID and the used algorithm in training.
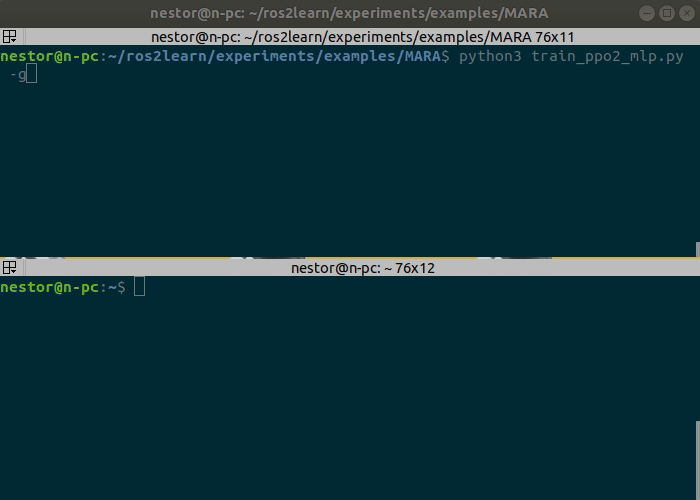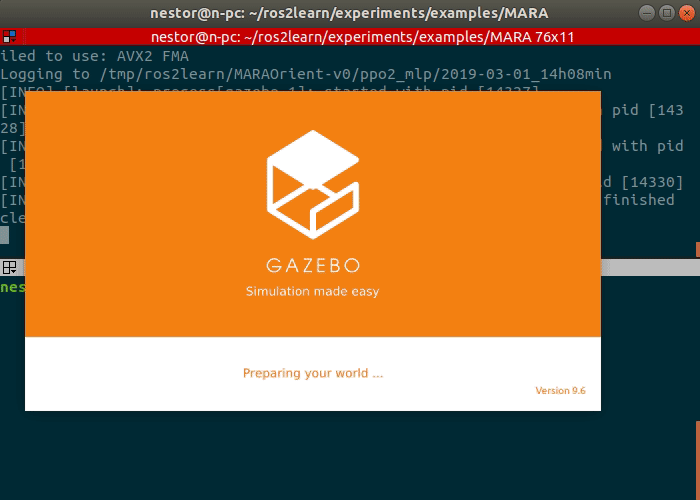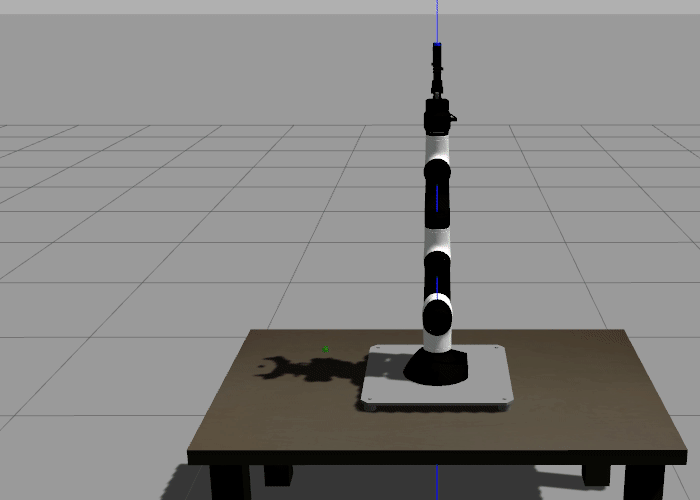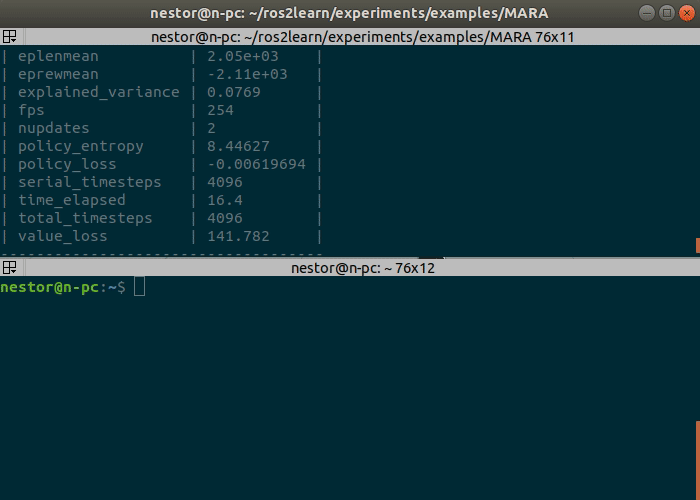
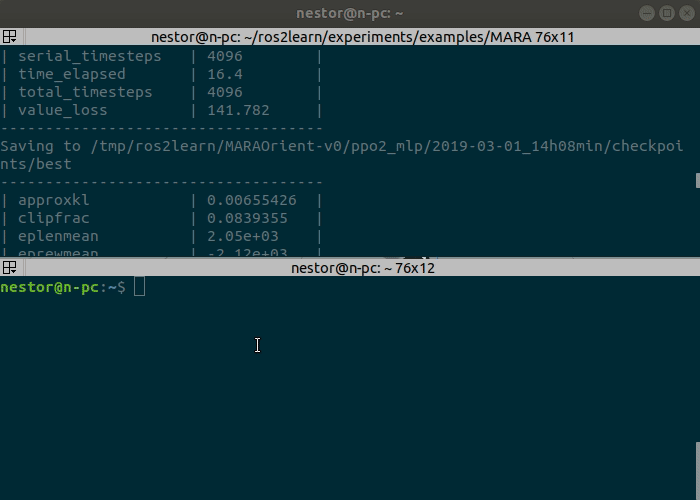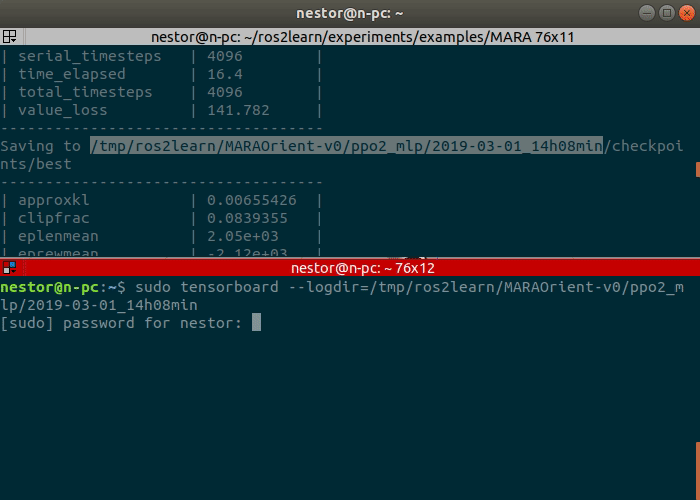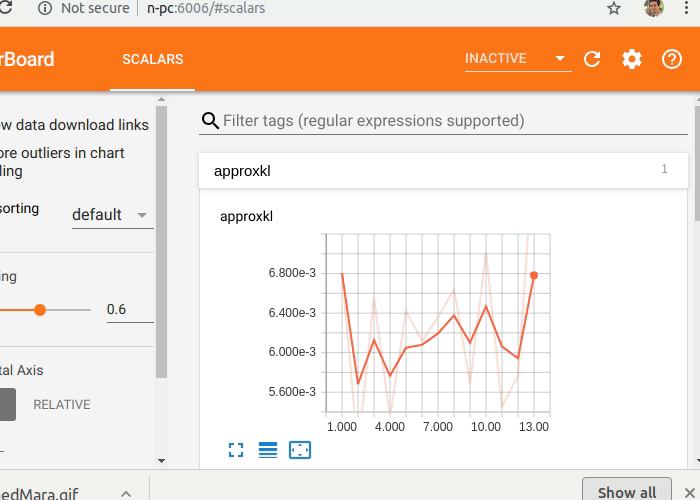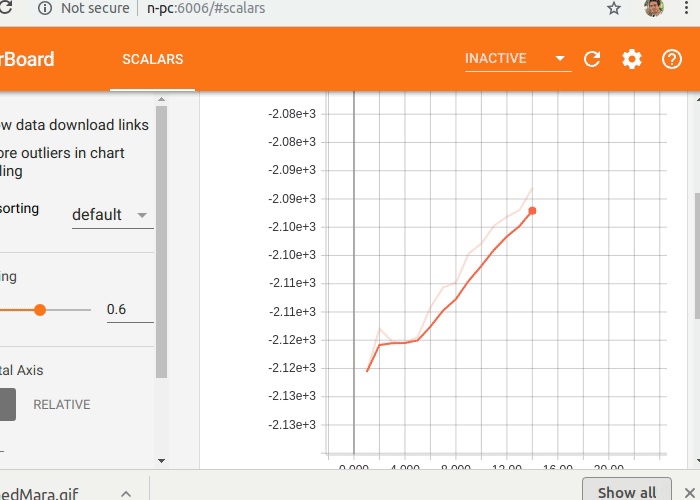
Now you just have to execute Tensorboard and open the link it will provide (or localhost:port_number) in your web browser. You will find many useful graphs like the reward (eprewmean) plotted there.
You can also set a specific port number in case you want to visualize more than one tensorboard file from different paths.
tensorboard --logdir=/tmp/ros2learn/MARACollision-v0/ppo2_mlp --port 8008
Do your own experiment
Hyperparameter tunning (existing environment)
- Set the desired target in the corresponding environment in gym-gazebo2 submodule.
- self.target_position
- self.target_orientation
- Set the desired hyperparameters in the corresponding default script of the algorithm in baselines submodule.
Create your own train script to use your own environment
- Create a session
- Get the hyperparameters from the corresponding defaults script of the algorithm to be used (you will need to add a new dictionary for your own environment)
- Make the environment
- DummyVecEnv for a single instance
- SubprocVecEnv for multiple instances
- Call the corresponding learn function of the algorithm to be used
Optional:
- Save the statistics and checkpoints in Tensorboard
- checkpoints
- tensorboard
- log
- monitor
- progress
- Save the used hyperparameters in the training
:warning: Be aware of env.set_episode_size(episode_size) function, if it is not called once the environment is made, the default size of the episode will be 1024. It is advisable to set the same value as the one to be used in the learning algorithm, or at least a power of 2.
Create your own run script to use your own environment
- Create a session
- Get the hyperparameters from the corresponding defaults script of the algorithm in baselines submodule used in training time, and also the target in your own environment
- self.target_position
- self.target_orientation
- Make a single environment (DummyVecEnv)
- Normalize the environment (VecNormalize) if you have normalized in the training
- Make the model and load the checkpoint you want to test
- Get the actions from the model
- stochastic
- deterministic
- Execute the actions
Optional:
- Save in files some useful information such us:
- Accuracy
- Position error (axes)
- Orientation error (quaternion)


