Segmenter
Segmenter: Transformer for Semantic Segmentation by Robin Strudel*, Ricardo Garcia*, Ivan Laptev and Cordelia Schmid.
*Equal Contribution
Installation
Define os environment variables pointing to your checkpoint and dataset directory, put in your .bashrc:
export DATASET=/path/to/dataset/dir
Install PyTorch 1.9 then pip install . at the root of this repository.
To download ADE20K, use the following command:
python -m segm.scripts.prepare_ade20k $DATASET
Model Zoo
We release models with a Vision Transformer backbone initialized from the improved ViT models.
ADE20K
Segmenter models with ViT backbone:
| Name | mIoU (SS/MS) | # params | Resolution | FPS | Download | ||
|---|---|---|---|---|---|---|---|
| Seg-T-Mask/16 | 38.1 / 38.8 | 7M | 512x512 | 52.4 | model | config | log |
| Seg-S-Mask/16 | 45.3 / 46.9 | 27M | 512x512 | 34.8 | model | config | log |
| Seg-B-Mask/16 | 48.5 / 50.0 | 106M | 512x512 | 24.1 | model | config | log |
| Seg-L-Mask/16 | 51.3 / 53.2 | 334M | 512x512 | 10.6 | model | config | log |
| Seg-L-Mask/16 | 51.8 / 53.6 | 334M | 640x640 | - | model | config | log |
Segmenter models with DeiT backbone:
| Name | mIoU (SS/MS) | # params | Resolution | FPS | Download | ||
|---|---|---|---|---|---|---|---|
| Seg-B†/16 | 47.1 / 48.1 | 87M | 512x512 | 27.3 | model | config | log |
| Seg-B†-Mask/16 | 48.7 / 50.1 | 106M | 512x512 | 24.1 | model | config | log |
Pascal Context
| Name | mIoU (SS/MS) | # params | Resolution | FPS | Download | ||
|---|---|---|---|---|---|---|---|
| Seg-L-Mask/16 | 58.1 / 59.0 | 334M | 480x480 | - | model | config | log |
Inference
Download one checkpoint with its configuration in a common folder, for example seg_tiny_mask.
You can generate segmentation maps from your own data with:
python -m segm.inference --model-path seg_tiny_mask/checkpoint.pth -i images/ -o segmaps/
To evaluate on ADE20K, run the command:
# single-scale evaluation:
python -m segm.eval.miou seg_tiny_mask/checkpoint.pth ade20k --singlescale
# multi-scale evaluation:
python -m segm.eval.miou seg_tiny_mask/checkpoint.pth ade20k --multiscale
Train
Train Seg-T-Mask/16 on ADE20K on a single GPU:
python -m segm.train --log-dir seg_tiny_mask --dataset ade20k \
--backbone vit_tiny_patch16_384 --decoder mask_transformer
To train Seg-B-Mask/16, simply set vit_base_patch16_384 as backbone and launch the above command using a minimum of 4 V100 GPUs (~12 minutes per epoch) and up to 8 V100 GPUs (~7 minutes per epoch). The code uses SLURM environment variables.
Logs
To plot the logs of your experiments, you can use
python -m segm.utils.logs logs.yml
with logs.yml located in utils/ with the path to your experiments logs:
root: /path/to/checkpoints/
logs:
seg-t: seg_tiny_mask/log.txt
seg-b: seg_base_mask/log.txt
Video Segmentation
Zero shot video segmentation on DAVIS video dataset with Seg-B-Mask/16 model trained on ADE20K.



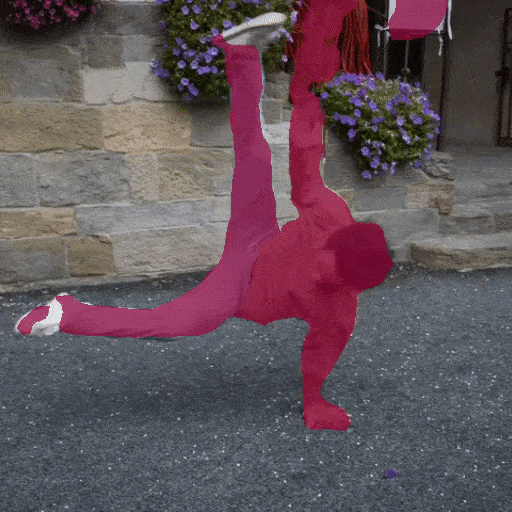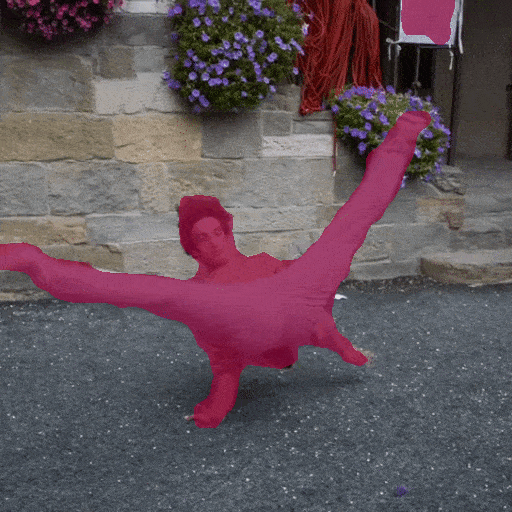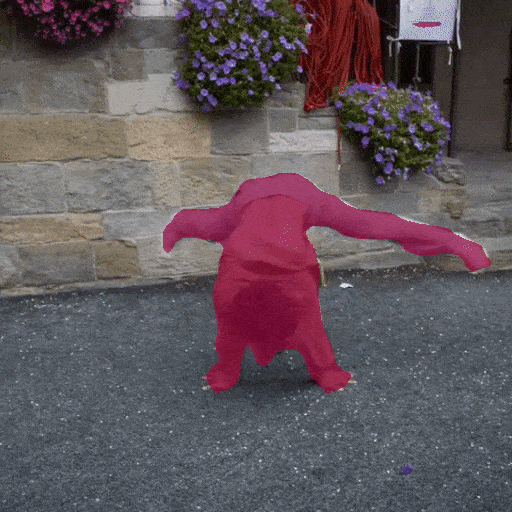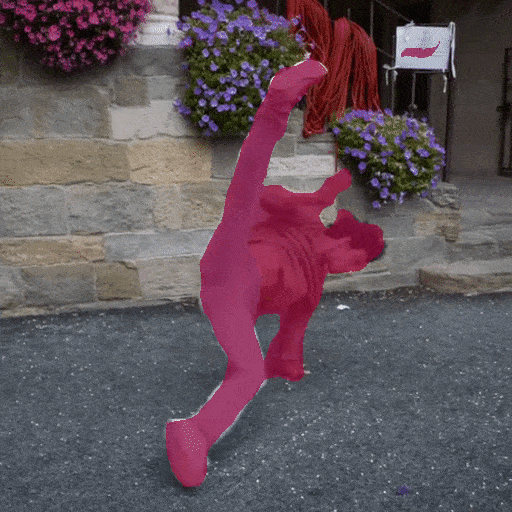
BibTex
@article{strudel2021,
title={Segmenter: Transformer for Semantic Segmentation},
author={Strudel, Robin and Garcia, Ricardo and Laptev, Ivan and Schmid, Cordelia},
journal={arXiv preprint arXiv:2105.05633},
year={2021}
}







