Stereo R-CNN
Code for 'Stereo R-CNN based 3D Object Detection for Autonomous Driving' (CVPR 2019)
This project contains the implementation of our CVPR 2019 paper arxiv.
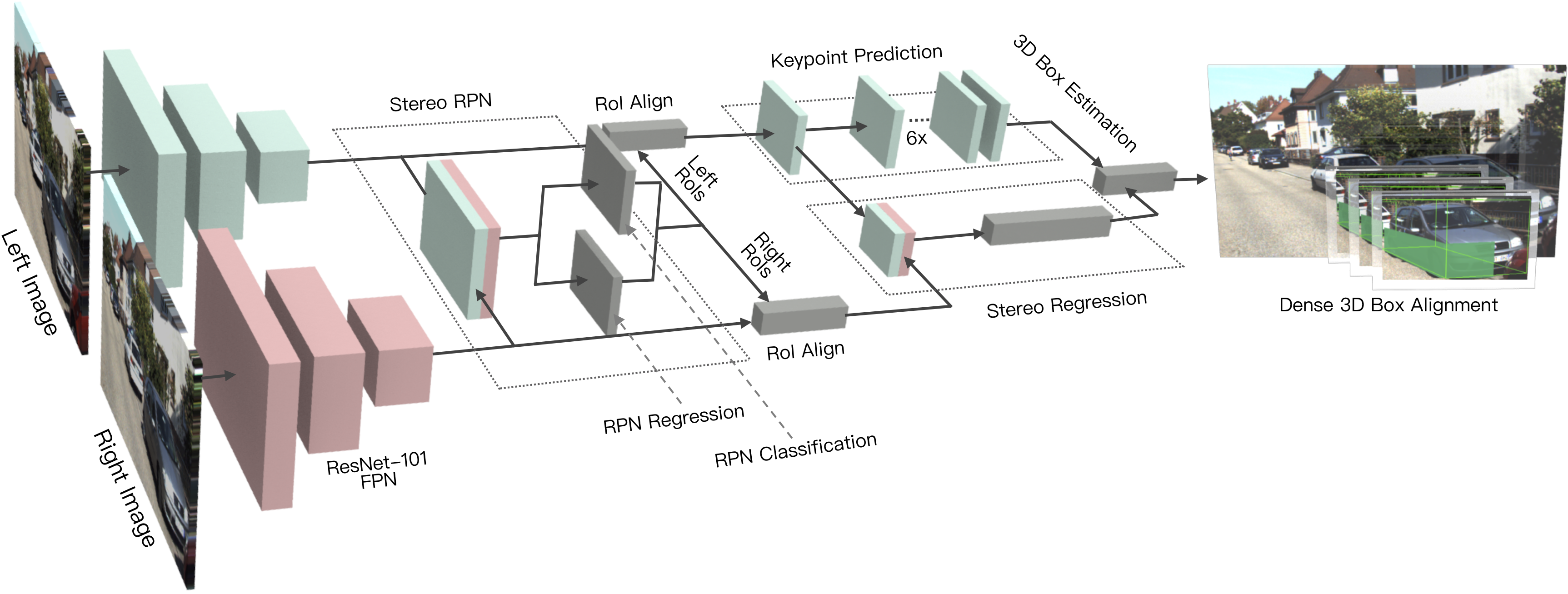
Stereo R-CNN focuses on accurate 3D object detection and estimation using image-only data in autonomous driving scenarios. It features simultaneous object detection and association for stereo images, 3D box estimation using 2D information, accurate dense alignment for 3D box refinement. We also provide a light-weight version based on the monocular 2D detection, which only uses stereo images in the dense alignment module. Please checkout to branch mono for details.
Authors: Peiliang Li, Xiaozhi Chen and Shaojie Shen from the HKUST Aerial Robotics Group, and DJI.
If you find the project useful for your research, please cite:
@inproceedings{licvpr2019,
title = {Stereo R-CNN based 3D Object Detection for Autonomous Driving},
author = {Li, Peiliang and Chen, Xiaozhi and Shen, Shaojie},
booktitle = {CVPR},
year = {2019}
}
0. Install
This implementation is tested under Pytorch 0.3.0. To avoid affecting your Pytorch version, we recommend using conda to enable multiple versions of Pytorch.
0.0. Install Pytorch:
conda create -n env_stereo python=2.7
conda activate env_stereo
conda install pytorch=0.3.0 cuda80 -c pytorch
conda install torchvision -c pytorch
0.1. Other dependencies:
git clone [email protected]:HKUST-Aerial-Robotics/Stereo-RCNN.git
cd stereo_rcnn
pip install -r requirements.txt
0.2. Build:
cd lib
sh make.sh
cd ..
1. Quick Demo
1.0. Set the folder for placing the model
mkdir models_stereo
1.1. Download our trained weight One Drive/Google Drive and put it into models_stereo/, then just run
python demo.py
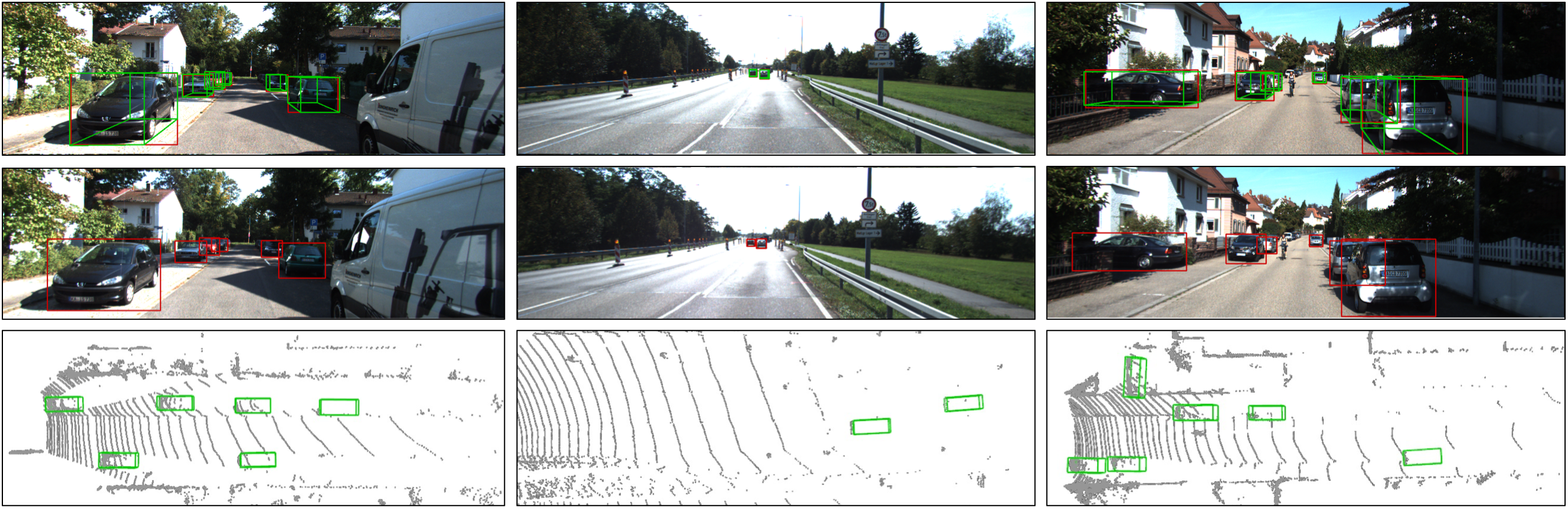
If everything goes well, you will see the detection result on the left, right and bird's eye view image respectively.
2. Dataset Preparation
2.0. Download the left image, right image, calibration, labels and point clouds (optional for visualization) from KITTI Object Benchmark. Make sure the structure looks like:
yourfolder/object
training
image_2
image_3
label_2
calib
velodyne
2.1. Create symlinks:
cd data/kitti
ln -s yourfolder/object object
cd ../..
3. Training
Download the Res-101 pretrained weight One Drive/Google Drive, and put it into data/pretrained_model
Set corresponding CUDA_VISIBLE_DEVICES in train.sh, and simply run
./train.sh
It consumes ~11G GPU memery for training. If your GPU memery is not enough, please try our light-weight version in branch mono.
The trained model and training log are saved in /models_stereo by default.
4. Evaluation
You can evaluate the 3D detection performance using either our provided model or your trained model.
Set corresponding CUDA_VISIBLE_DEVICES in test.sh, and run
./test.sh
The results are saved in models_stereo/result by default. You can evaluate the results using the tool from here.
Some sample results:
5. Acknowledgments
This repo is built based on the Faster RCNN implementation from faster-rcnn.pytorch and fpn.pytorch, and we also use the imagenet pretrained weight (originally provided from here) for initialization.



