BMW-TensorFlow-Inference-API-GPU
This is a repository for an object detection inference API using the Tensorflow framework.
This repo is based on Tensorflow Object Detection API.
The Tensorflow version used is 1.13.1. The inference REST API works on GPU. It's only supported on Linux Operating systems.
Models trained using our training tensorflow repository can be deployed in this API. Several object detection models can be loaded and used at the same time.
Prerequisites
- Ubuntu 18.04
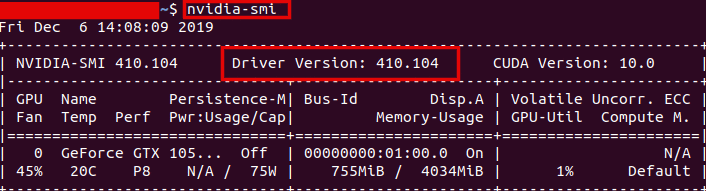
- NVIDIA Drivers (410.x or higher)
- Docker CE latest stable release
- NVIDIA Docker 2
Check for prerequisites
To check if you have docker-ce installed:
docker --version
To check if you have nvidia-docker installed:
nvidia-docker --version
To check your nvidia drivers version, open your terminal and type the command nvidia-smi
Install prerequisites
Use the following command to install docker on Ubuntu:
chmod +x install_prerequisites.sh && source install_prerequisites.sh
Install NVIDIA Drivers (410.x or higher) and NVIDIA Docker for GPU by following the official docs
Build The Docker Image
In order to build the project run the following command from the project's root directory:
sudo docker build -t tensorflow_inference_api_gpu -f docker/dockerfile .
Behind a proxy
sudo docker build --build-arg http_proxy='' --build-arg https_proxy='' -t tensorflow_inference_api_gpu -f ./docker/dockerfile .
Run the docker container
To run the API, go to the project's root directory and run the following:
Using Linux based docker:
sudo NV_GPU=0 nvidia-docker run -itv $(pwd)/models:/models -p <docker_host_port>:4343 tensorflow_inference_api_gpu
The <docker_host_port> can be any unique port of your choice.
The API file will be run automatically, and the service will listen to http requests on the chosen port.
NV_GPU defines on which GPU you want the API to run. If you want the API to run on multiple GPUs just enter multiple numbers separated by a comma: (NV_GPU=0,1 for example)
API Endpoints
To see all available endpoints, open your favorite browser and navigate to:
http://<machine_IP>:<docker_host_port>/docs
The 'predict_batch' endpoint is not shown on swagger. The list of files input is not yet supported.
P.S: If you are using custom endpoints like /load, /detect, and /get_labels, you should always use the /load endpoint first and then use /detect or /get_labels
Endpoints summary
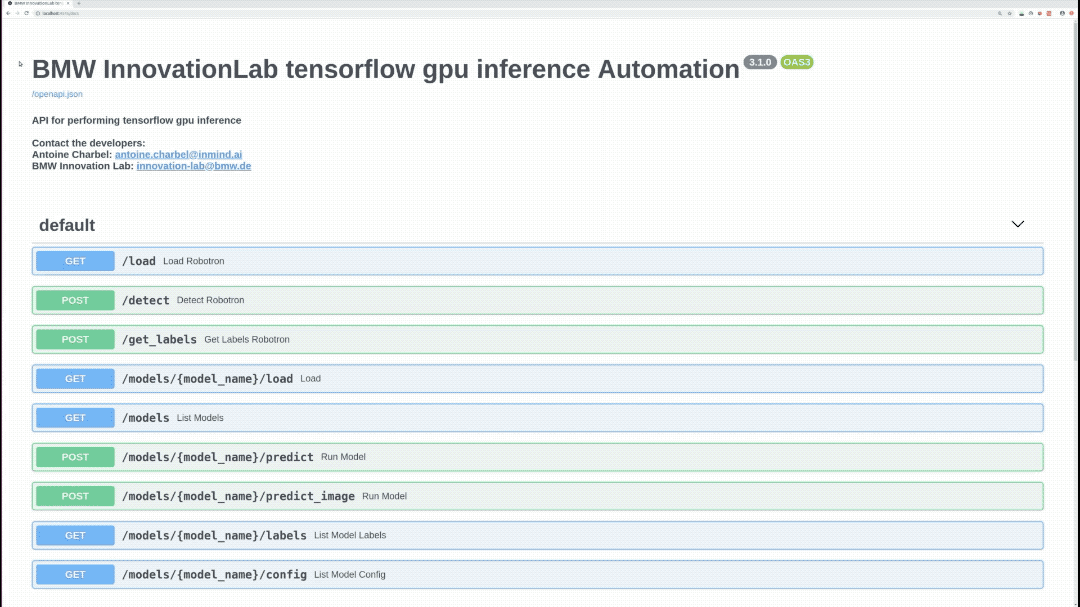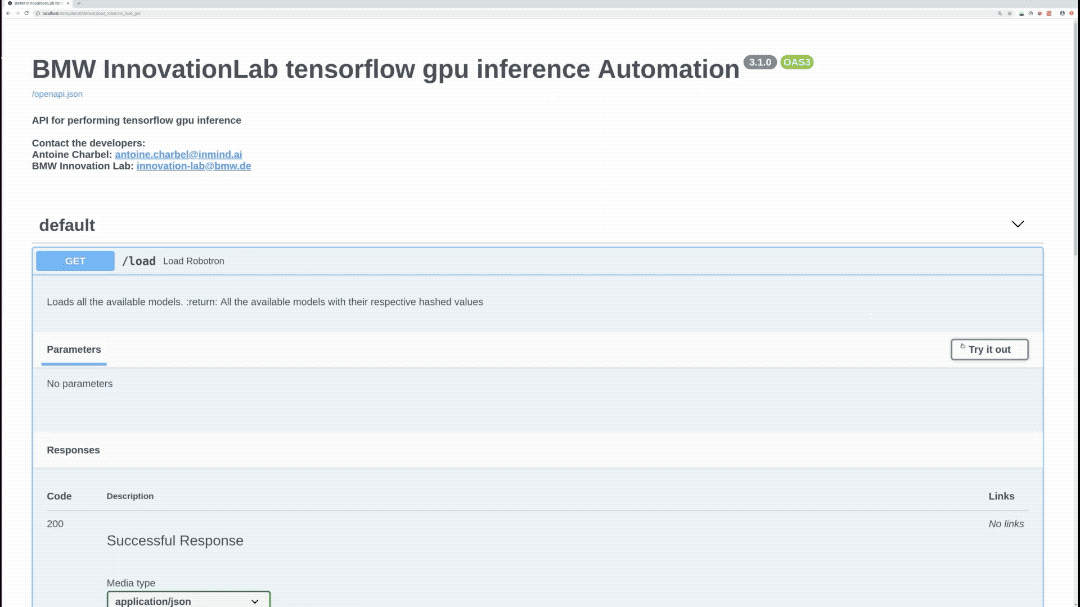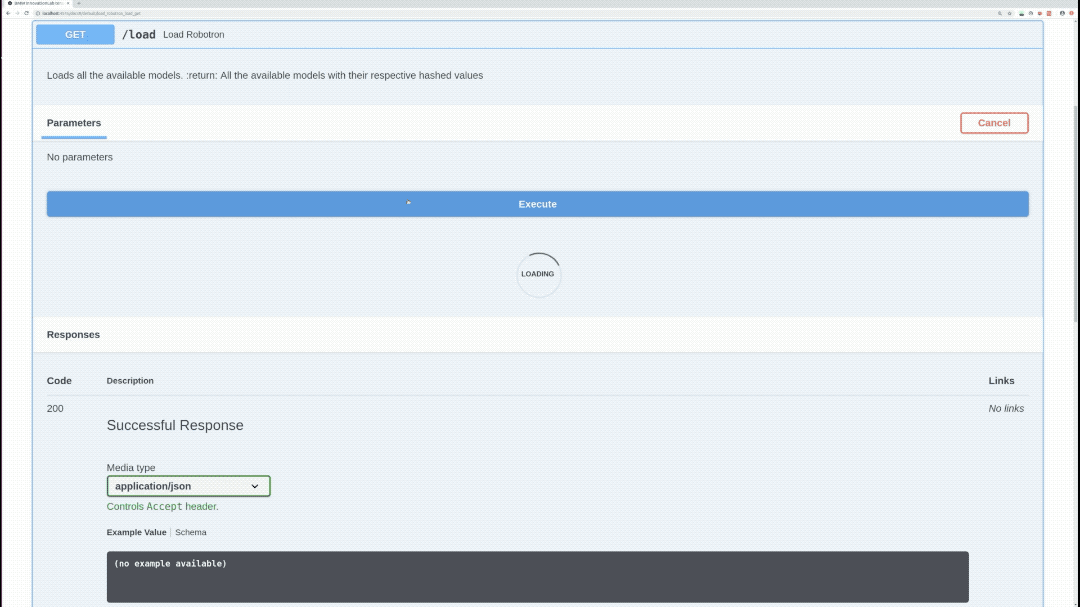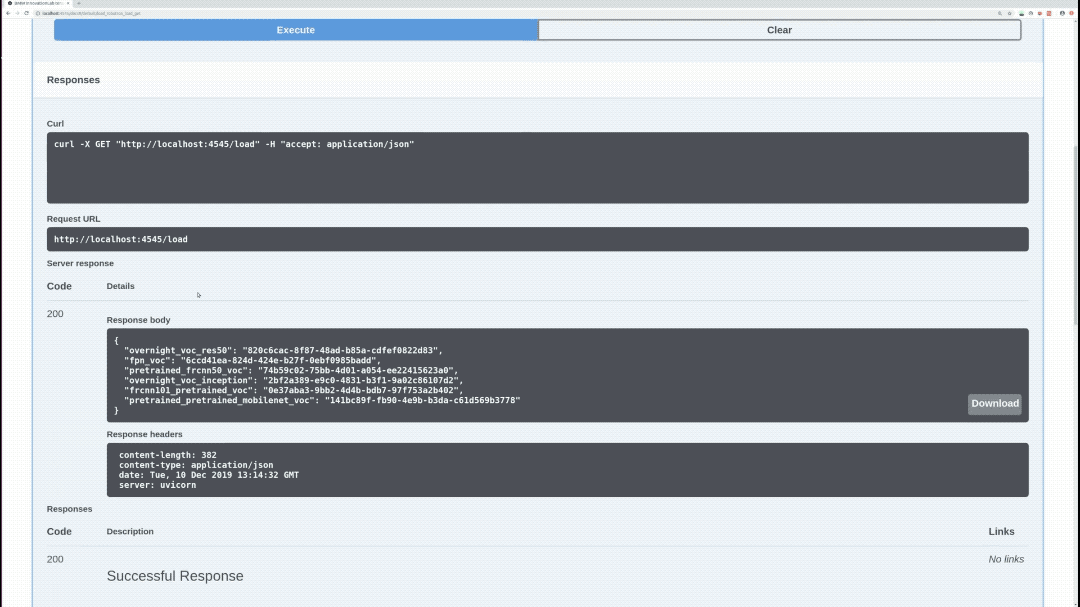
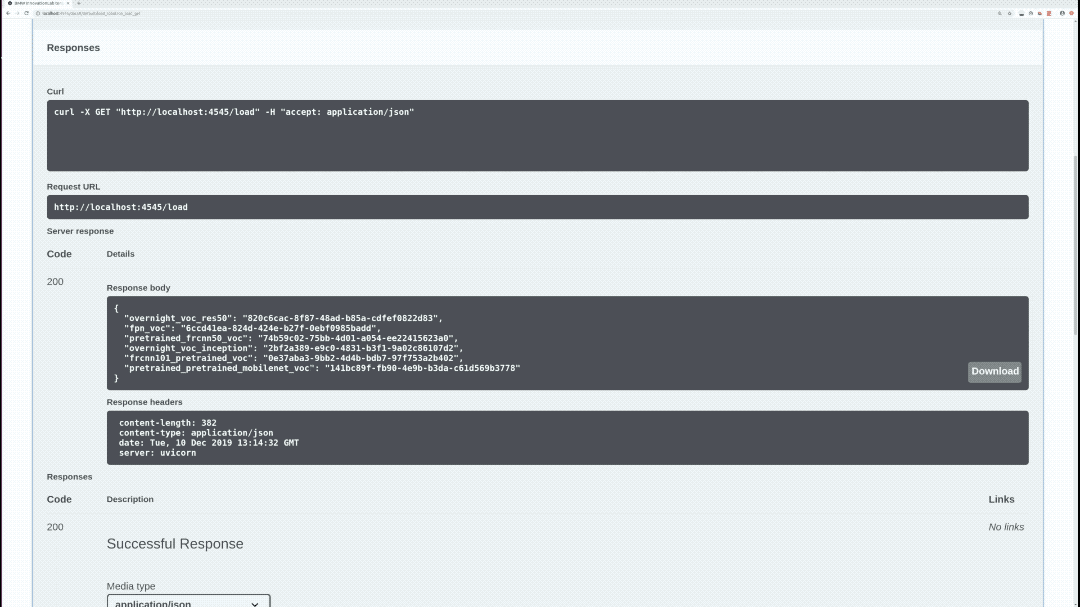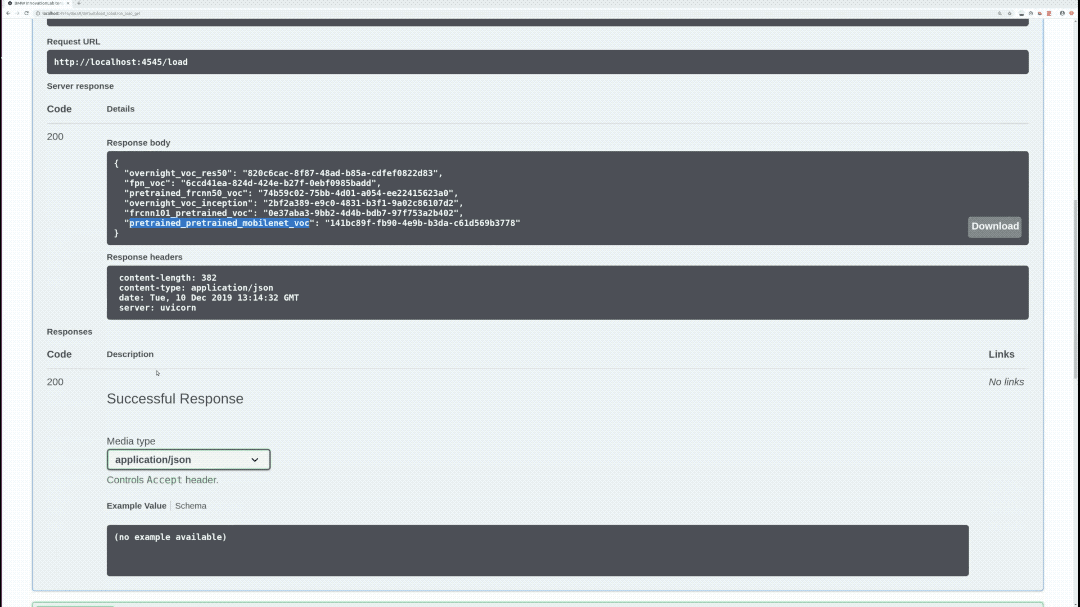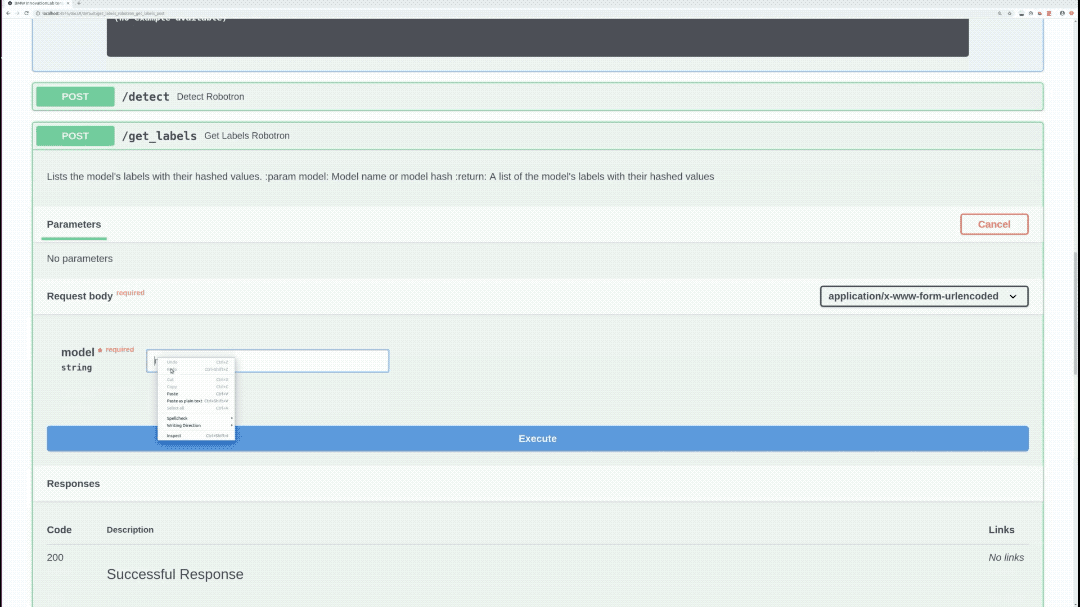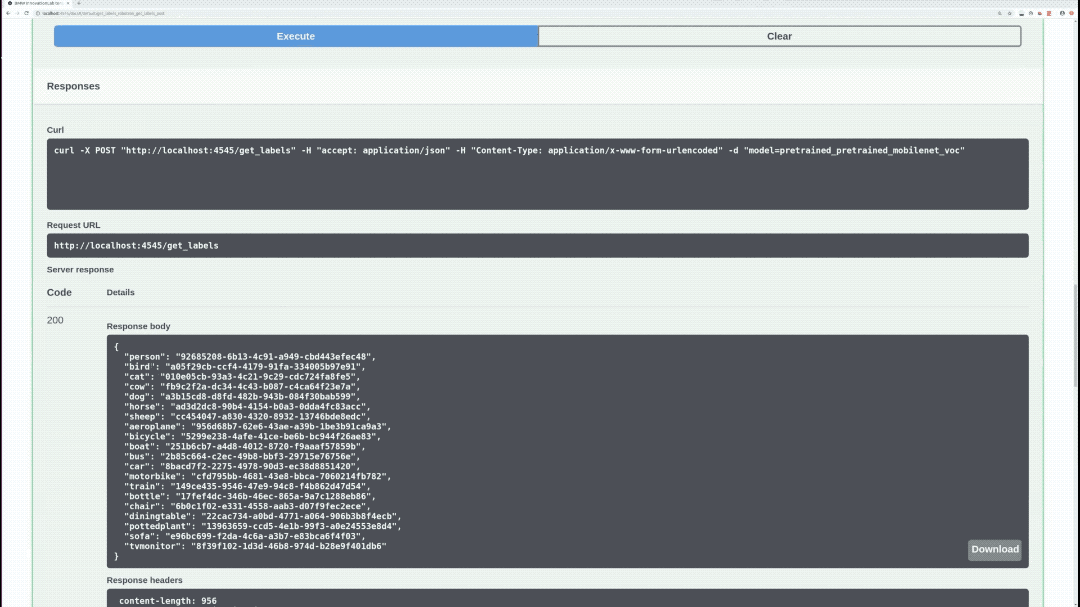
/load (GET)
Loads all available models and returns every model with it's hashed value. Loaded models are stored and aren't loaded again
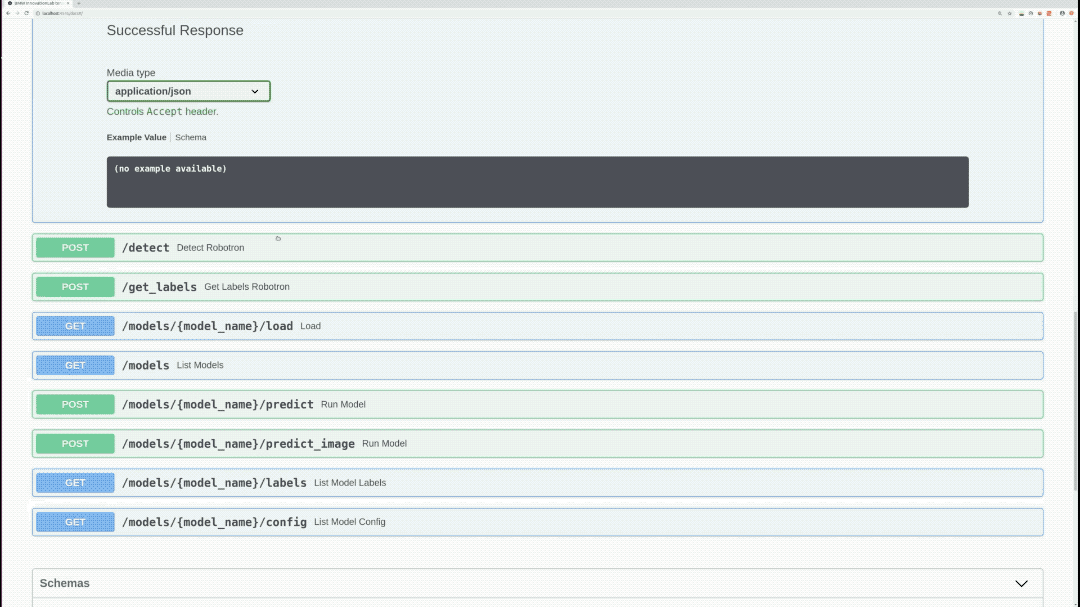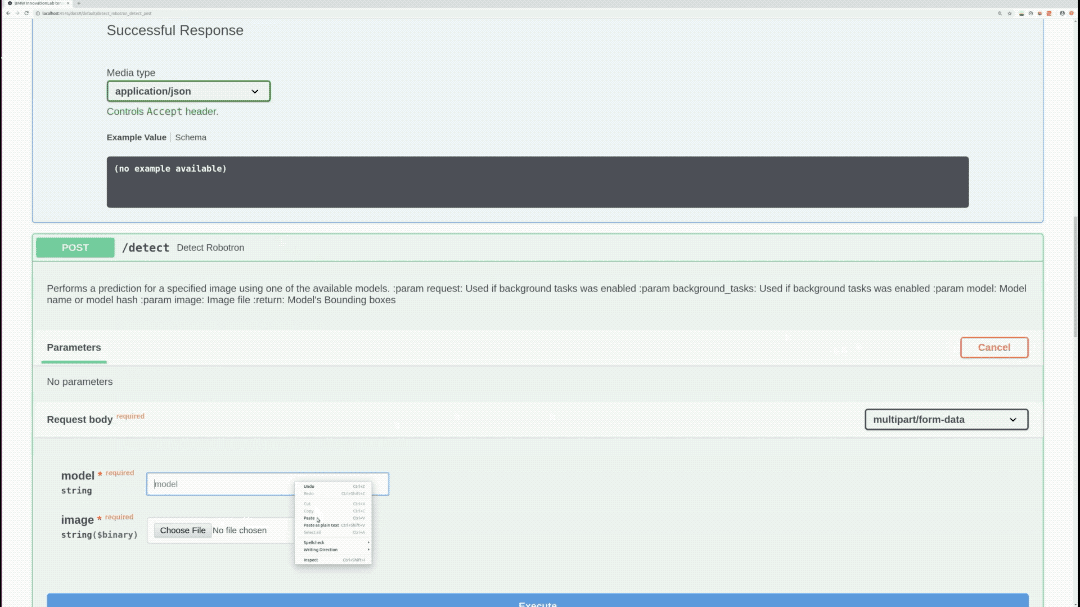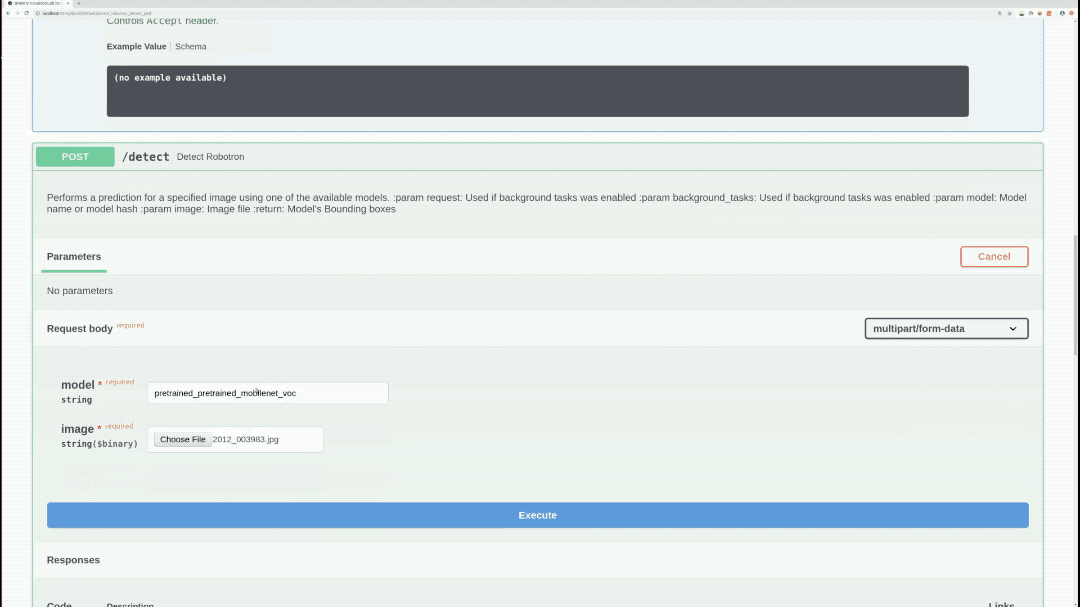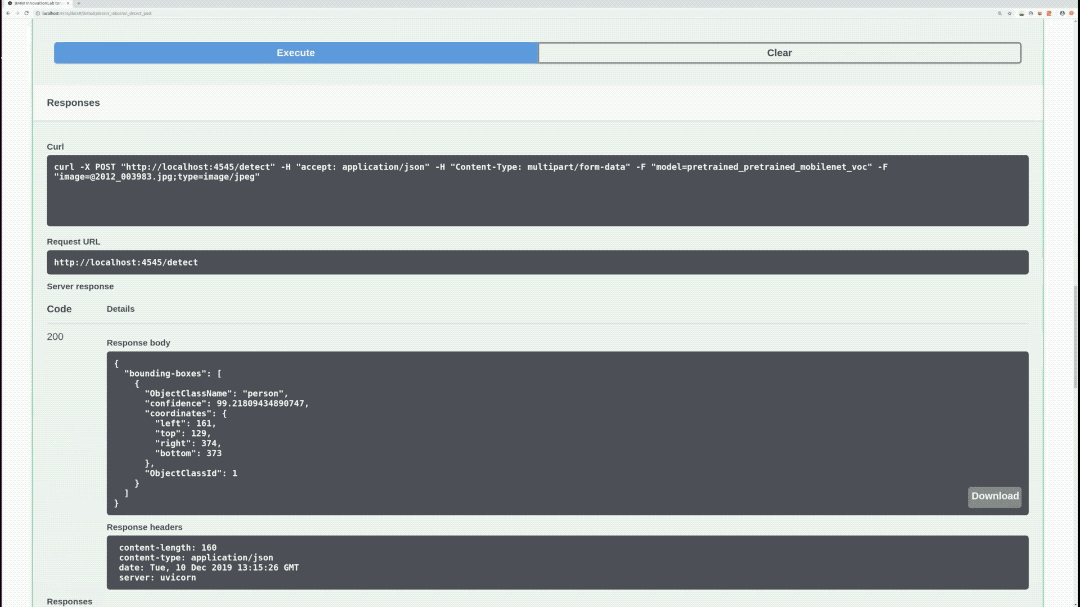
/detect (POST)
Performs inference on specified model, image, and returns bounding-boxes
/get_labels (POST)
Returns all of the specified model labels with their hashed values
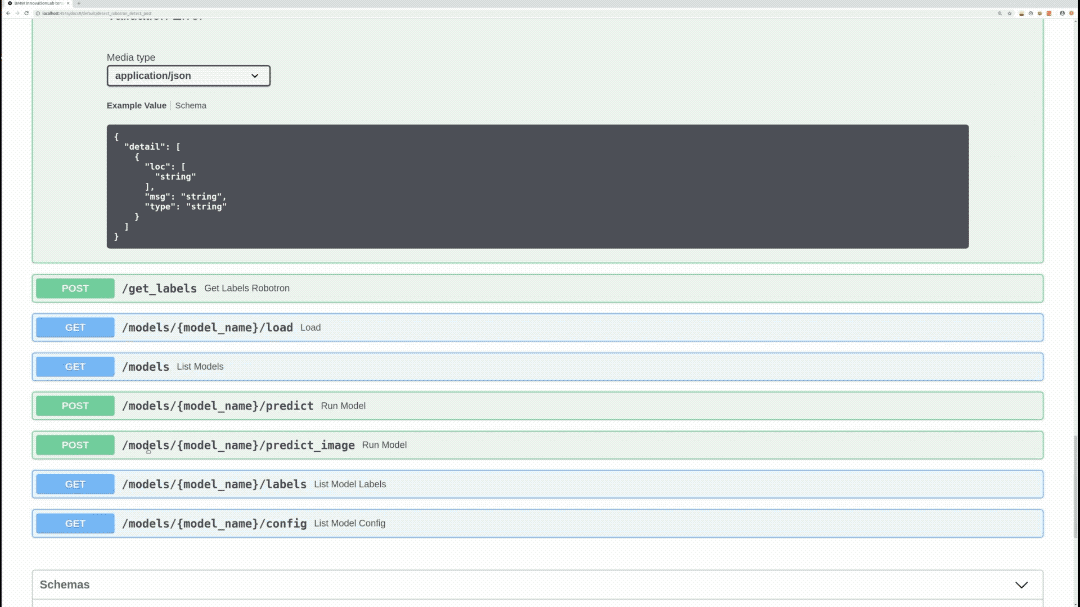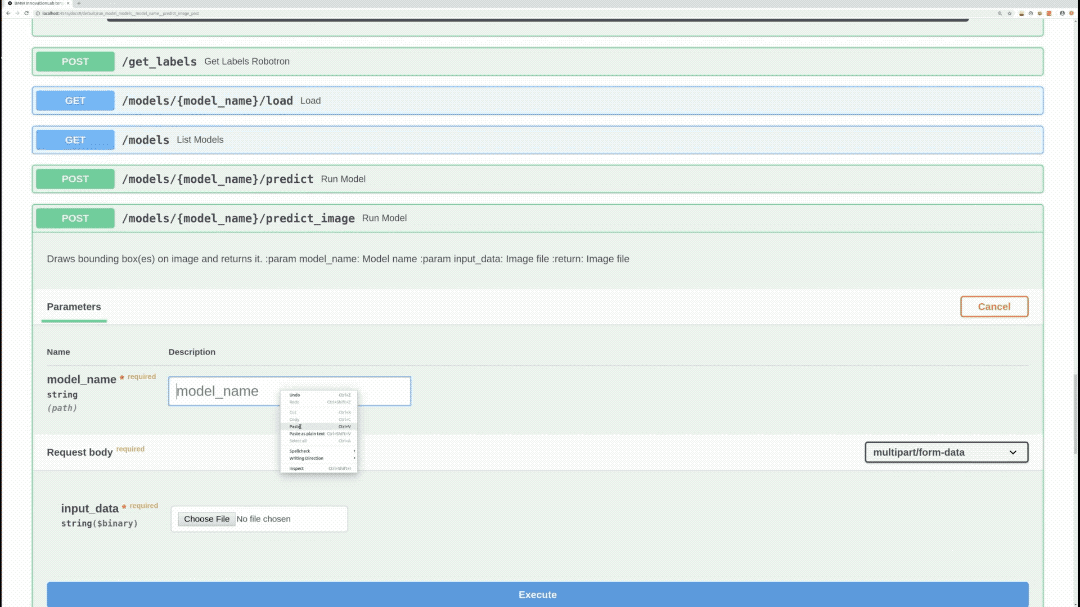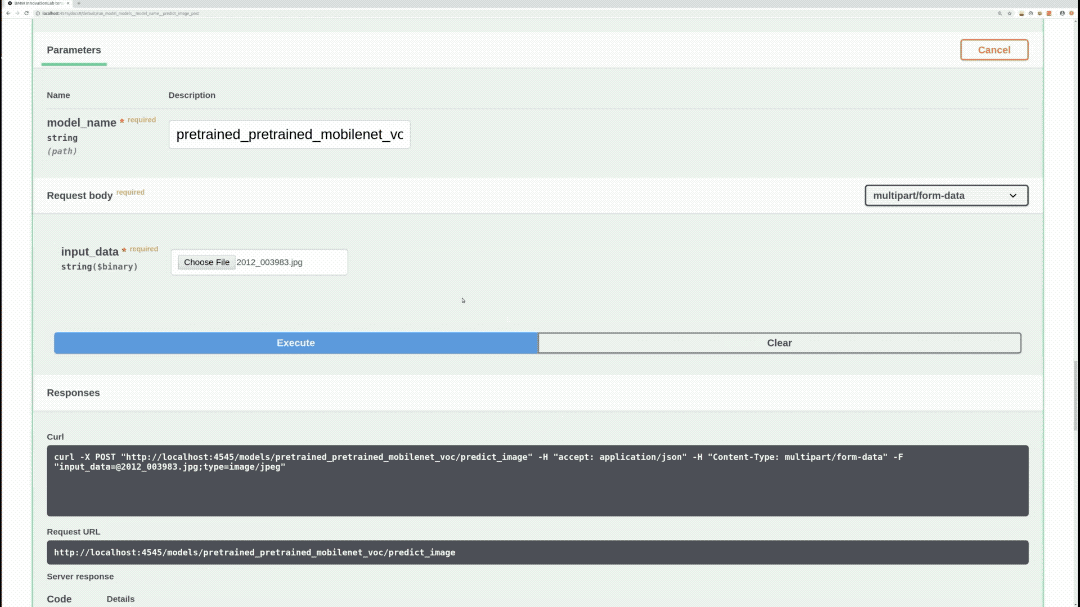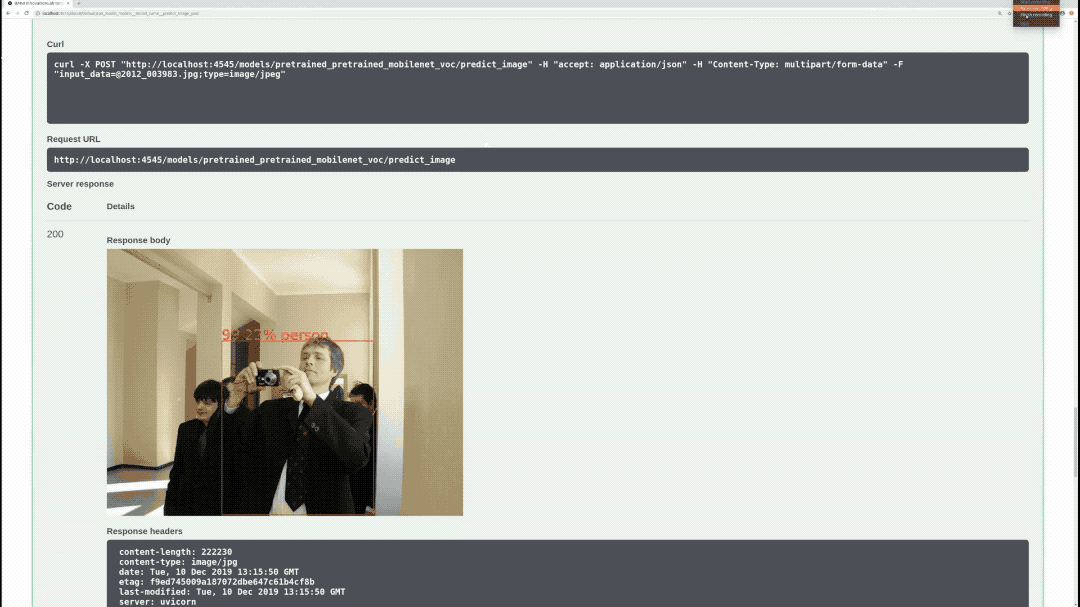
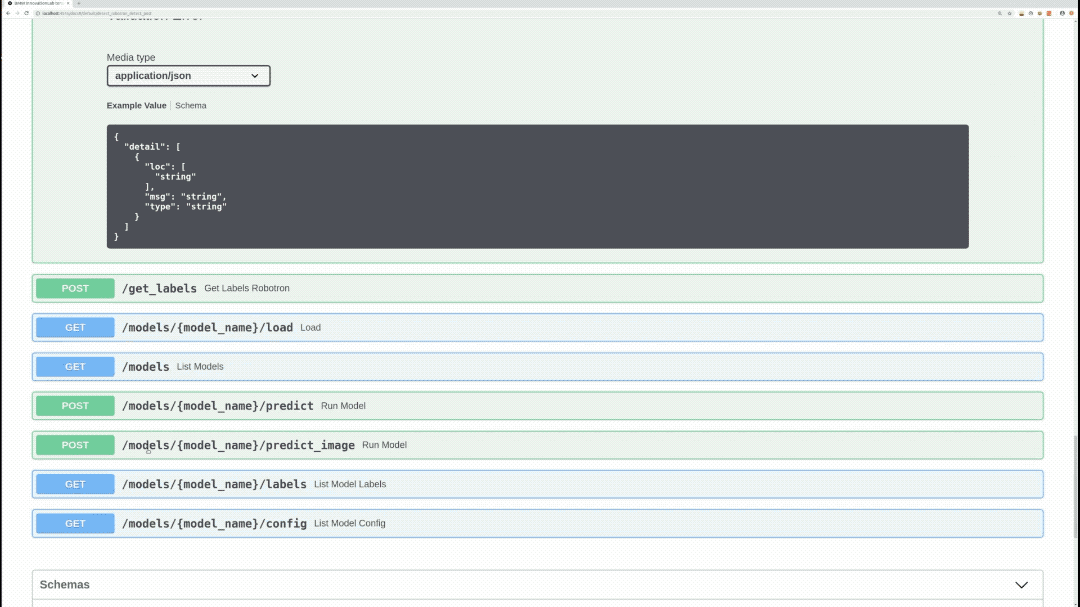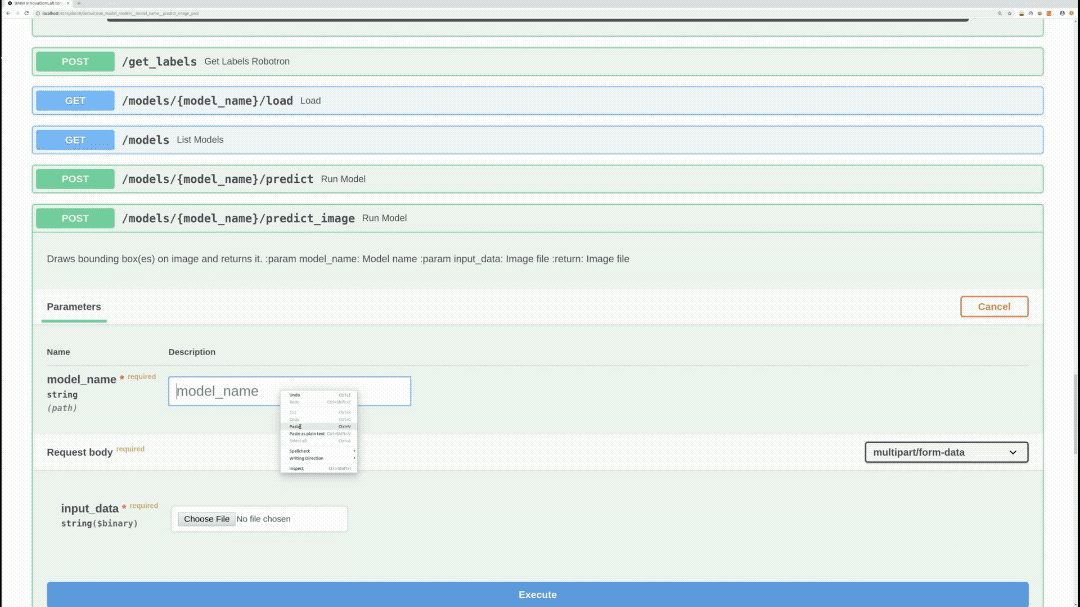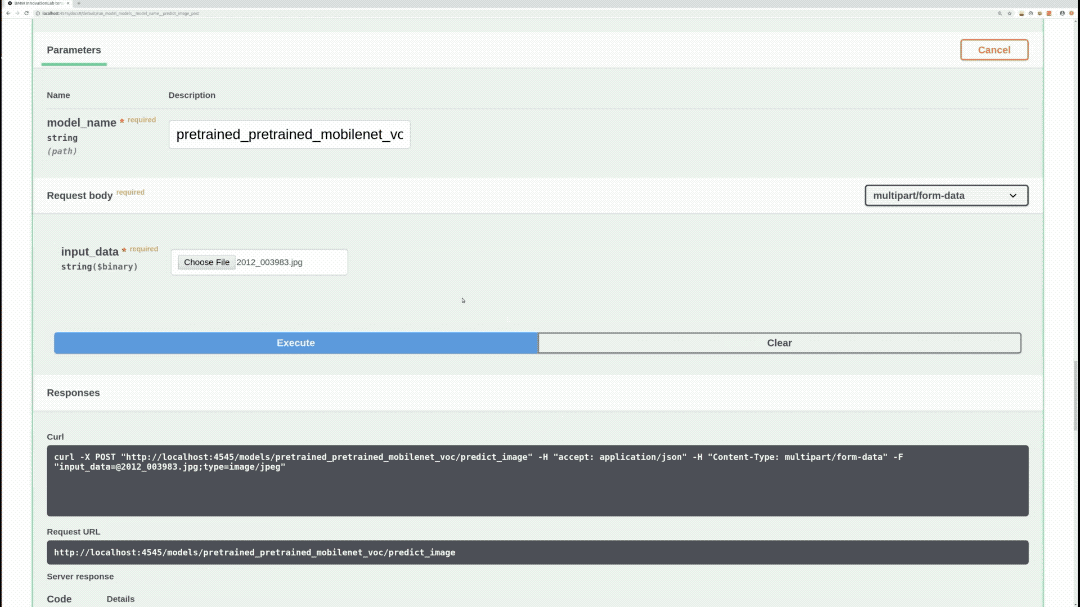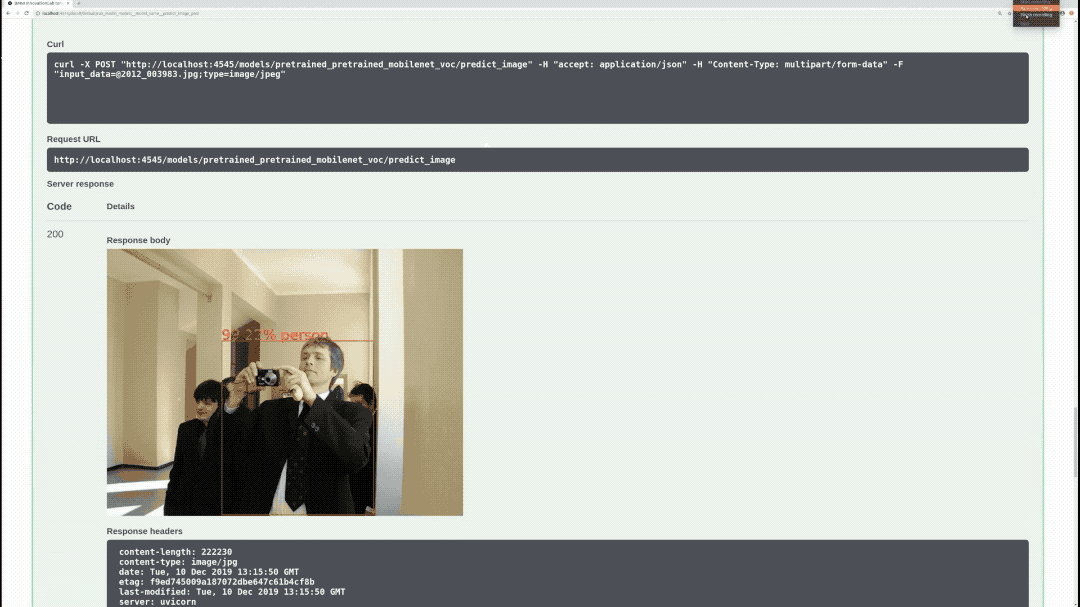
/models/{model_name}/predict_image (POST)
Performs inference on specified model, image, draws bounding boxes on the image, and returns the actual image as response
/models (GET)
Lists all available models
/models/{model_name}/load (GET)
Loads the specified model. Loaded models are stored and aren't loaded again
/models/{model_name}/predict (POST)
Performs inference on specified model, image, and returns bounding boxes.
/models/{model_name}/labels (GET)
Returns all of the specified model labels
/models/{model_name}/config (GET)
Returns the specified model's configuration
/models/{model_name}/predict_batch (POST)
Performs inference on specified model and a list of images, and returns bounding boxes
Model structure
The folder "models" contains subfolders of all the models to be loaded.
Inside each subfolder there should be a:
-
pb file: contains the model weights
-
pbtxt file: contains model classes
-
Config.json (This is a json file containing information about the model)
{ "confidence": 60, "predictions": 15, "number_of_classes": 2, "inference_engine_name": "tensorflow_detection", "framework": "tensorflow", "type": "detection", "network": "inception" }P.S:
- "number_of_classes" value should be equal to your model's number of classes
- You can change "confidence" and "predictions" values while running the API
- The API will return bounding boxes with a confidence higher than the "confidence" value. A high "confidence" can show you only accurate predictions. "confidence" value should be between 0 and 100
- The "predictions" value specifies the maximum number of bounding boxes in the API response. It should be positive
Benchmarking
| Windows | Ubuntu | |||
|---|---|---|---|---|
| Network\Hardware | Intel Xeon CPU 2.3 GHz | Intel Xeon CPU 2.3 GHz | Intel Xeon CPU 3.60 GHz | GeForce GTX 1080 |
| ssd_fpn | 0.867 seconds/image | 1.016 seconds/image | 0.434 seconds/image | 0.0658 seconds/image |
| frcnn_resnet_50 | 4.029 seconds/image | 4.219 seconds/image | 1.994 seconds/image | 0.148 seconds/image |
| ssd_mobilenet | 0.055 seconds/image | 0.106 seconds/image | 0.051 seconds/image | 0.052 seconds/image |
| frcnn_resnet_101 | 4.469 seconds/image | 4.985 seconds/image | 2.254 seconds/image | 0.364 seconds/image |
| ssd_resnet_50 | 1.34 seconds/image | 1.462 seconds/image | 0.668 seconds/image | 0.091 seconds/image |
| ssd_inception | 0.094 seconds/image | 0.15 seconds/image | 0.074 seconds/image | 0.0513 seconds/image |



